SVM의 정의
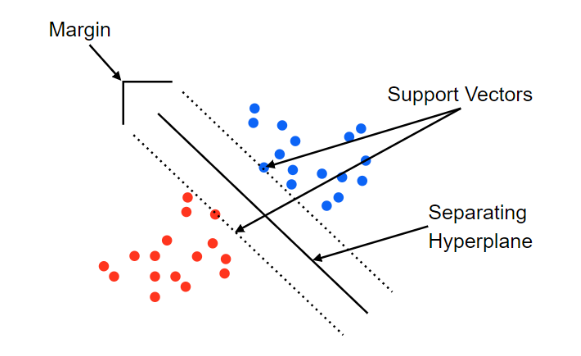
SVM은 신경망보다 사용이 간결하여 분류나 회귀 분석에서 사용이 가능하지만, 분류에서 주로 사용하고 있는 기법입니다. SVM은 초평면을 이용해서 분류를 수행하게 되는 알고리즘입니다.
어느 한쪽에 치우치지 않게 분류하며, 양쪽 데이터와 균등한 위치에 분류 기준을 세워줘야 합니다.
(그런게해야 새로운 데이터가 들어오더라도 오류가 적습니다.)
그렇 어떻게 할까요?
SVM 분류 방법
- SVM은 결정 경계를 정의하는 모델입니다.
- 최적의 모델은 Margin을 최대화하는 결정 경계를 찾는 것입니다.
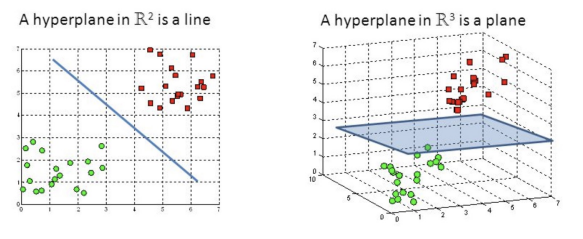
SVM 분류 종류

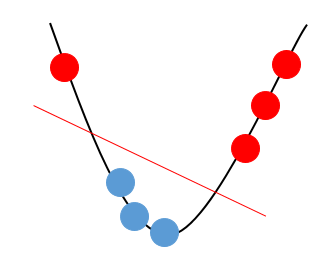
Hard Margin
어떠한 오분류도 허용하지 않습니다.

위의 데이터를 영역을 정확히 나누려면 2차 곡선 위로 올립니다.
Soft Margin
어느 정도의 오분류는 허용합니다. 그에 따른 Penalty를 줍니다.
0-1 Loss
Error 가 발생한 개수만큼 페널티 계산
Hinge Loss
오분류 정도에 따라 패널티 계산
- 오류를 감안해서 분류를 할 것인지, 최적 마진을 목 퓨로 할 것인지 사전 정의가 필요합니다.
- 마진을 최대화하면, 새로 들어오는 데이터에 대해서 마진이 넓어 잘 분류됩니다.
- 오류 발생을 최소화하면, 새로 들어오는 데이터에 대해서는 마진이 좁아서 분류가 잘못될 가능성이 비교적 높습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
iris = load_iris()
data = iris['data']
target = iris['target']
data = data[target !=0, :2]
target = target[target !=0]
train_x, test_x, train_y, test_y = train_test_split(
data, target, test_size=0.2)
svc = SVC(kernel='linear')
svc.fit(train_x, train_y)
linear_pred = svc.predict(test_x)
poly_svc = SVC(kernel='poly')
poly_svc.fit(train_x, train_y)
poly_pred = poly_svc.predict(test_x)
print('Linear SVC 정확도 : {:.4f}'.format(accuracy_score(test_y, linear_pred)))
print('Poly SVC 정확도 : {:.4f}'.format(accuracy_score(test_y, poly_pred)))
파라미터
- kernel이 poly이면 직선을 곡선으로 mapping 시켜줍니다
- RBF는 데이터를 고차원의 공간으로 mapping 시켜줍니다.(gamma와 C도 세팅해주어야 함)
- gamma는 결정 경계를 스케일 해주는 값입니다. 하나의 데이터 샘플이 영향력을 행사하는 거리를 결정합니다. 결정 경계의 곡률을 조정 (휘는 정도?)
- degree는 몇 차원의 곡선으로 맵핑할지 정해주는 값입니다.
- C는 얼마나 많은 데이터 샘플이 다른 클래스에 놓이는 것을 허용하는지 결정(C가 너무 높으면 과대 접합이 될 가능성이 커지고, 너무 낮으면 과소 적합이 된다) C의 유무에 따라 하드 마진, 소프트 마진이 결정됩니다.


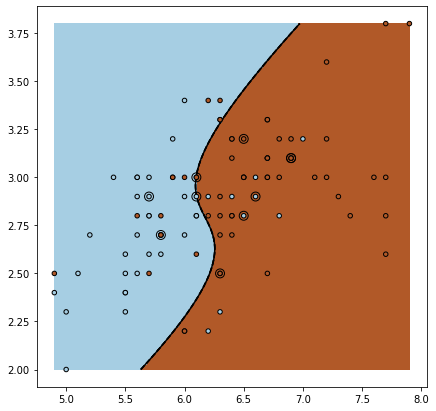

거리 기반의 데이터는 Scaling을 시켜주어야 합니다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 차원축소 (0) | 2022.05.10 |
|---|---|
| [머신러닝] 군집화 (0) | 2022.05.06 |
| [머신러닝] K-Nearest Neighbors (0) | 2022.05.06 |
| [머신러닝] Naive Bayes (0) | 2022.05.06 |
| [머신러닝] 앙상블(Ensemble) (0) | 2022.05.06 |




댓글