확률의 개념
특정한 사건이 일어날 가능성을 이야기합니다.

조건부 확률
어떤 사건 A가 일어났을 때, 다른 사건 B가 발생할 확률
ex) 어제 비가 왔는데, 오늘 비가 올 확률

독립

조건부 독립
사건 C가 일어났을 때 서로 다른 사건 A, B가 독립일 때

베이즈 정리


위의 데이터가 있다고 가정해봅시다. 여기서 이 길 확률과 질 확률 각각 구하면

여기서 fast와 slow의 확률을 또 구하면

이제 조건부 확률로 Y가 win일 때 X가 fast일확률과, Y가 win일때 X가 slow일 확률 각각 구하면

조건부 확률로 Y가 lose일 때 X가 fast일확률과, Y가 lose일때 X가 slow일 확률 각각 구하면

이제 모든 조건부 확률을 구했으니 베이즈 정리를 이용하여 Fast의 결과를 예측해봅시다. X가 Fast일 때 Y값을 예측하면 되므로 X가 Fast일때 질 확률과 이 길 확률 둘 중 높은 확률을 선택하면 됩니다.

Fast가 win일 확률이 2/3로 더 크므로 Fast이면 win이라는 정답이 나옵니다.
하지만 베이즈 정리의 단점이 변수가 많아질수록 계산량이 기하급수적으로 늘어난다는 것입니다.


X의 벡터의 길이가 길면 길수록 계산량이 많아져 Naive Bayes를 사용합니다.
Naive Bayes
- 종속 변수(Y)가 주어졌을 때 입력 변수(X)들은 모두 조건부 독립이다.
- 예측 변수들의 정확한 조건부 확률은 각 조건부 확률의 곱으로 충분히 잘 추정할 수 있다는 단순한 가정으로 시작

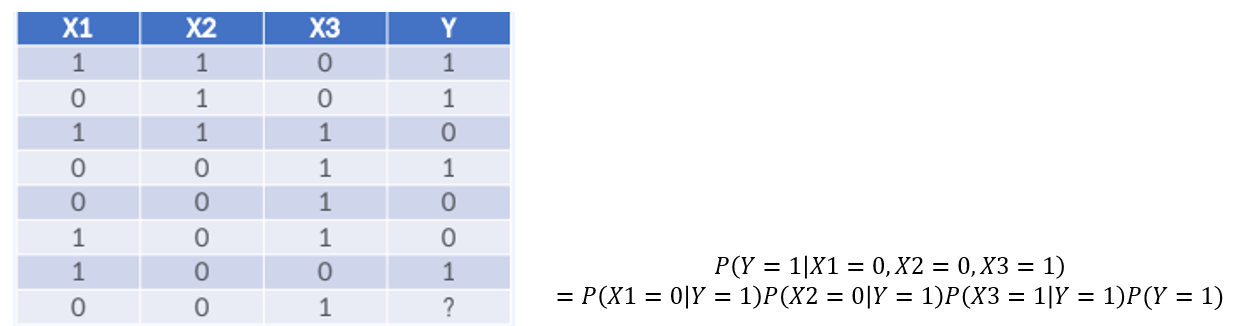



Y가 0일 때 확률이 더 높으므로 Y=0입니다.
장점
- 변수가 많을 때 좋다.
- 텍스트 데이터에서 큰 강점을 보인다.
단점
- 희귀한 확률이 나왔을 때 처리하기 힘들다.
- 조건부 독립이라는 가정 자체가 비 현실적
예시를 보겠습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
spam = pd.read_csv('sms_spam.csv')
spam.head(5)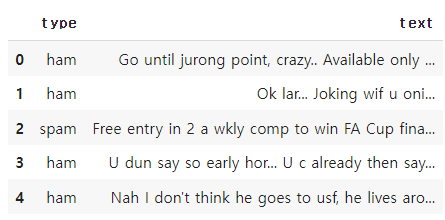
스팸인지 아닌지를 분류하는 csv파일 하나를 가져왔습니다. type은 라벨 인코딩을 시켜주고 text파일은 숫자와 영어를 제외한 나머지는 삭제해주겠습니다. 그리고 훈련 데이터와 테스트 데이터를 분리시키겠습니다.
text = spam['text']
label = spam['type']
text = text.str.replace("[^a-zA-Z0-9\ ]", "", regex=True).str.lower()
label = label.map({'ham': 0, 'spam': 1})
train_x, test_x, train_y, test_y = train_test_split(text, label, test_size=0.3, stratify=label)
후에 단어들을 토큰 시킬 nltk 모듈을 사용하겠습니다.
# Naive Bayes를 학습 시키기 위해서는 각 문장에서 단어들이 몇 번 나오는지 확인해야함.
import nltk
from nltk import word_tokenize
nltk.download('punkt')
word_tokenize(train_x.iloc[0])
word_tokenize안에 문장을 넣으면 토큰 시켜서 위처럼 잘라줍니다. 여러 문장들을 넣으려면 CountVectorizer를 사용합니다.
# 단어들의 countvector를 만듬
from sklearn.feature_extraction.text import CountVectorizer
cnt_vector = CountVectorizer(tokenizer=word_tokenize)
cnt_vector.fit(train_x.iloc[:1])
# vocabuloary_하면 학습에 사용된 단어를 모두 사전형으로 나열
# 이 단어들을 사전순으로 나열
vocab = sorted(cnt_vector.vocabulary_.keys())
#transform 은 학습시킨 모델의 단어를 사전 순으로 변환
sample_cnt_vector = cnt_vector.transform(train_x.iloc[:2]).toarray()
pd.DataFrame(sample_cnt_vector, columns=vocab)
이제 모든 데이터를 넣은 CountVector로 naive_bayes를 학습시켜 결과를 보겠습니다.
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score
cnt_vector = CountVectorizer(tokenizer=word_tokenize)
cnt_vector.fit(train_x)
train_matrix = cnt_vector.transform(train_x)
test_matrix = cnt_vector.transform(test_x)
# 모델에 단어 학습
naive_bayes = BernoulliNB()
naive_bayes.fit(train_matrix, train_y)
train_pred = naive_bayes.predict(train_matrix)
test_pred = naive_bayes.predict(test_matrix)
train_acc = accuracy_score(train_y, train_pred)
test_acc = accuracy_score(test_y, test_pred)
print('Train Accuracy is {:.4f}'.format(train_acc))
print('Test Accuracy is {:.4f}'.format(test_acc))
'머신러닝' 카테고리의 다른 글
| [머신러닝] SVM (0) | 2022.05.06 |
|---|---|
| [머신러닝] K-Nearest Neighbors (0) | 2022.05.06 |
| [머신러닝] 앙상블(Ensemble) (0) | 2022.05.06 |
| [머신러닝] 의사결정트리(Decision Tree) 알고리즘 (2) | 2022.05.05 |
| [머신러닝] 성능 평가 지표 (0) | 2022.05.04 |




댓글