앙상블의 정의
앙상블이란 여러 약한 분류기들을 결합하여 강 분류기로 만드는 것입니다.
여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법입니다.
앙상블 학습의 유형은 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)의 세가지로 나눌 수 있으며, 이외에도 스태킹을 포함한 다양한 앙상블 기법이 있습니다.
보팅(Voting)
보팅이란 서로 다른 알고리즘을 가진 분류기를 결합하는 것입니다.
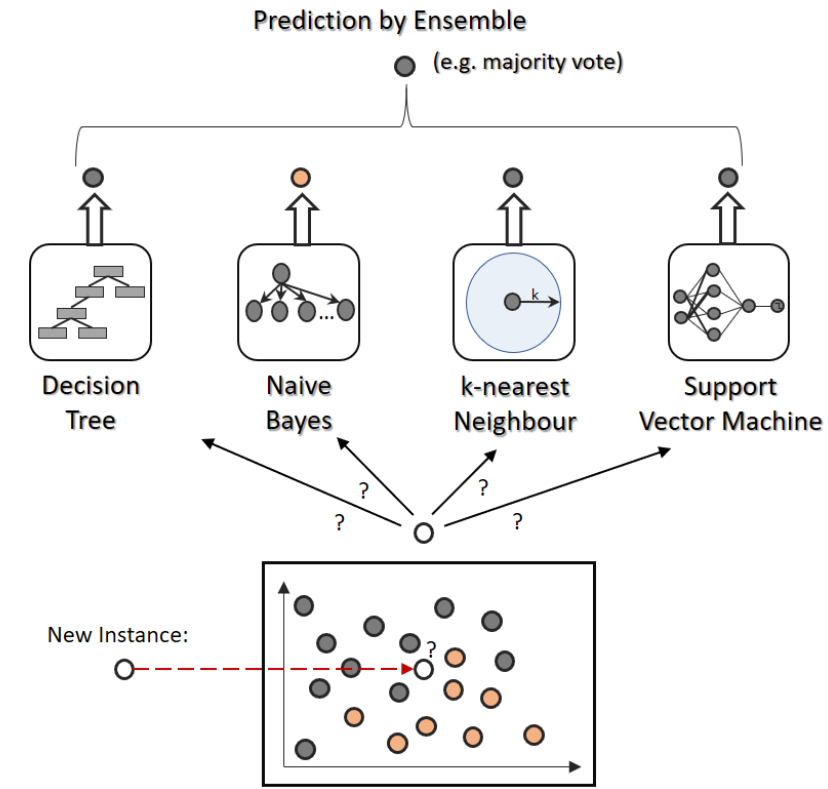
보팅 방법에는 두 가지가 있습니다. 하드 보팅과 소프트 보팅입니다. 하드 보팅을 이용한 분류는 다수결 원칙과 비슷합니다. 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것입니다. 소프트 보팅은 분류기들의 레이블 값 결정 확률을 모두 더하고 평균하여 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정합니다. 일반적으로 소프트 보팅이 많이 쓰입니다.

import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
lr = LogisticRegression()
knn = KNeighborsClassifier(8)
voting = VotingClassifier(estimators=[('LR', lr), ('KNN', knn)], voting='soft')
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
voting.fit(train_x, train_y)
lr.fit(train_x, train_y)
knn.fit(train_x, train_y)
vot_pred = voting.predict(test_x)
lr_pred = lr.predict(test_x)
knn_pred = knn.predict(test_x)
print('LogisticRegression 정확도 : {:.4f}'.format(accuracy_score(test_y, lr_pred)))
print('KNN 정확도 : {:.4f}'.format(accuracy_score(test_y, knn_pred)))
print('Voting 정확도 : {:.4f}'.format(accuracy_score(test_y, vot_pred)))
보팅을 한다고해서 항상 성능이 올라가진 않지만, 단일 ML 알고리즘보다 뛰어는 예측 성능을 가지는 경우가 많습니다.
배깅(Bagging)
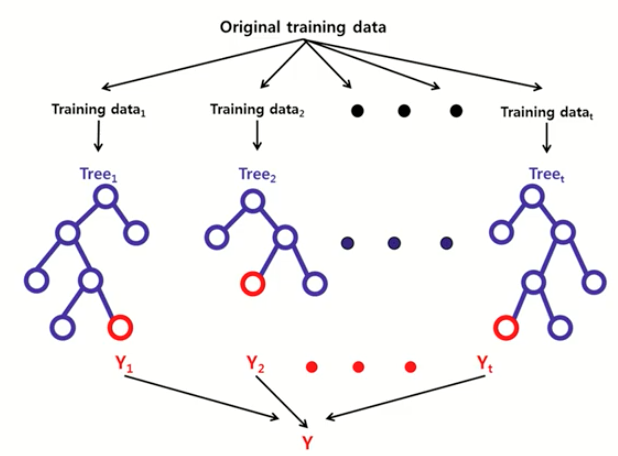
각각의 분류기가 모두 같은 유형의 알고리즘 기반이며, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것입니다. 대표적으로 랜덤 포레스트가 있습니다.
Bagging = Bootstrap + Aggregation
즉, 약한 분류기들을 결합하여 강 분류기로 만드는 것입니다.
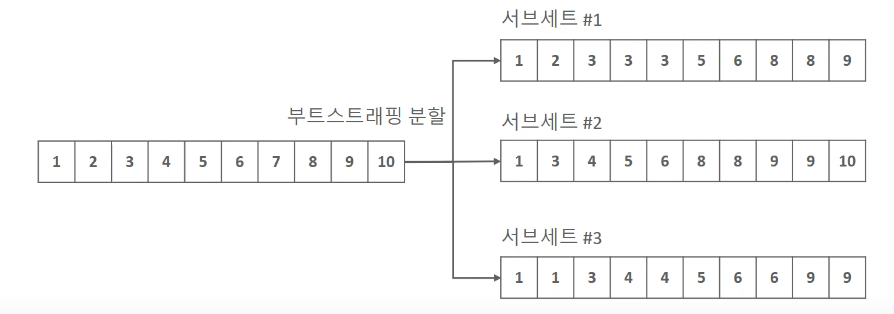
Bootstrap
- Train Data에서 여러 번 복원 추출하는 Random Sampling 기법(데이터 일부가 중첩됨)
- 추출된 샘플들을 부트스트랩 샘플이라고 부릅니다.
- 이론적으로 36.8%의 샘플이 뽑히지 않게 됩니다. (Out-Of-Bag 샘플)
- 추출되지 않는 샘플들을 이용해 교차 검증에서 Valid 데이터로 사용할 수 있습니다.

Aggregation
- 추출된 부트스트랩 샘플마다 약 분류기를 학습합니다.
- 생성된 약 분류기들의 예측 결과를 Voting을 통해 결합합니다.

랜덤 포레스트
- 랜덤 포레스트는 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘입니다.
- 랜덤 포레스트는 결정 트리의 기반 알고리즘으로써 쉽고 직관적인 장점을 그대로 가지고 있습니다.
- 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 합니다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
rf = RandomForestClassifier()
rf.fit(train_x, train_y)
pred = rf.predict(test_x)
acc = accuracy_score(test_y, pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(acc))
결정 트리의 단점인 Overfitting을 해결하고, 노이즈 데이터에 영향을 크게 받지 않습니다.
하지만, 트리 기반의 앙상블 알고리즘의 단점은 하이퍼 파라미터가 너무 많고, 그로 인한 튜닝 시간이 많이 소모되며, 예측 결과를 해석하고 이해하기가 어렵습니다.
- n_estimators: 랜덤 포레스트에서 결정 트리의 개수를 지정합니다. 많이 설정할수록 좋은 성능을 기대할 수 있지만 계속 증가시킨다고 무조건 성능이 좋아지는 것도 아니고, 늘릴수록 학습 수행 시간이 오래 걸립니다.
- min_samples_split: 노드를 분할하기 위한 최소한의 심플 데이터수(과적합 제어)
- min_samples_leaf: 리프 노드가 되기 위한 최소한의 심플 데이터수(과적합 제어)
- max_features: 최적의 분할을 위해 고려할 피처의 최대 개수(sqrt, auto, log2)
- max_depth: 트리의 최대 깊이(과적합 제어)
- max_leaf_nodes: 리프 노드의 최대 개수
AdaBoost, GBM(Gradient Boosting Machine)
부스팅 알고리즘은 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여를 통해 오류를 개선해 나가면서 학습하는 방식입니다. 대표적으로 AdaBoost(Adaptive boosting)와 그래디언트 부스트가 있습니다.
AdaBoost
에이다 부스트는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘입니다.
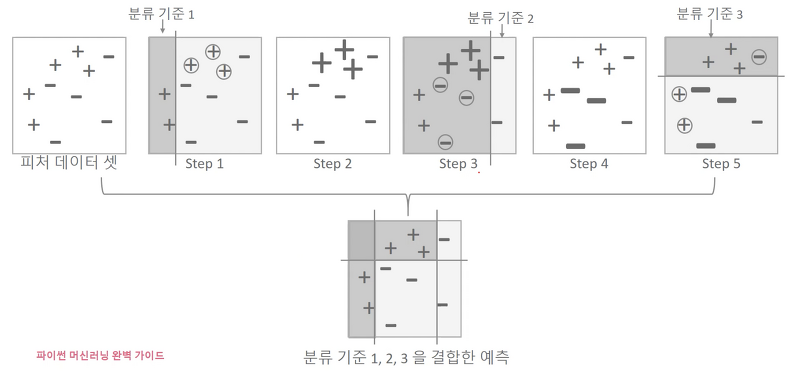
- step 1: 첫 번째 약한 학습기가 분류 기준 1로 +와 -를 분류한 것입니다. 오른쪽에 + 데이터는 잘못 분류된 오류 데이터입니다.
- step 2: 이 오류 데이터에는 다음 약한 학습기가 잘 분류할 수 있게 가중치 값을 부여합니다.
- step 3: 두 번째 약한 학습기가 분류 기준 2로 +와 -를 분류하고, 왼쪽의 -는 잘못 분류된 오류 데이터입니다.
- step 4: 이 오류 데이터에는 다음 약한 학습기가 잘 분류할 수 있게 가중치 값을 부여합니다.
- step 5: 세 번째 약한 학습기가 분류 기준 3으로 +와 -를 분류하고 오류 데이터를 찾습니다. 에이다 부스트는 이렇게 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행합니다.
- 마지막은 모든 약한 학습기를 결합한 결과 예측입니다. 하나의 약한 학습기들보다 훨씬 정확도가 올라갔습니다.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
ada_boost = AdaBoostClassifier(n_estimators=500, learning_rate=0.1)
ada_boost.fit(train_x, train_y)
pred = ada_boost.predict(test_x)
acc = accuracy_score(test_y, pred)
print('AdaBoost 정확도: {0:.4f}'.format(acc))
- base_estimator : 앙상블에 포함될 기본 분류기 종류, 기본값으로 DecisionTreeClassifier(max_depth=1)를 사용
- n_estimators : 모델에 포함될 분류기 개수
- learning_rate : 학습률
- algorithm : 부스팅 알고리즘, 기본값='SAMME.R'
- random_state : 난수 seed 설정
GBM(Gradient Boosting Machine)
- GBM도 에이다 부스트와 유사하지만, 경사 하강법을 이용하는 것이 가장 큰 차이입니다.
- 분류의 실제 결괏값을 y, 피처를 x1, x2,..., xn 그리고 이 예 함수를 F(x)라고 하면 h(x) = y - F(x)이고, 이 식이 최소화되는 방향성을 가지고 경사 하강법으로 가중치를 업데이트하는 것입니다.
- GBM은 CART 기반으로 분류와, 회귀 모두 가능합니다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.1)
gb.fit(train_x, train_y)
pred = gb.predict(test_x)
acc = accuracy_score(test_y, pred)
print('GradientBoosting 정확도: {0:.4f}'.format(acc))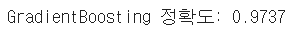
- loss: 손실 함수를 지정합니다. (deviance, exponential), default는 deviance
- n_estimators: 약한 분류기 개수
- learning_rate: (0~1) default=0.1, 너무 작게 설정하면 모든 약한 학습기 반복이 완료돼도 최소 오류 값을 찾지 못할 수 있고, 너무 크면 global minimum을 찾지 못하고 지나쳐 버릴 수 있습니다. n_estimator와 상호 보완적으로 조합해 사용합니다.
- max_depth: 최대 깊이
- min_samples_split: 노드를 분할하기 위한 최소한의 심플 데이터수
- min_samples_leaf: 리프 노드가 되기 위한 최소한의 심플 데이터수
- max_features: 최적의 분할을 위해 고려할 피처의 최대 개수(sqrt, auto, log2)
- max_depth: 트리의 최대 깊이
- max_leaf_nodes: 리프 노드의 최대 개수
- subsample: 약한 학습기에 사용하는 데이터 샘플링 비율입니다. (0 ~ 1 사이의 값) default = 1
GBM은 과적합에도 강한 뛰어난 성능을 보이지만, 병렬 처리가 되지 않아 수행 시간이 오래 걸린다는 단점이 있습니다.
XGBoost(eXtrea Gradient Boost)
XGBoost는 GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제 등의 문제를 해결해서 매우 각광을 받고 있습니다. 특히 병렬 CPU 환경에서 병렬 학습이 가능해 기존 GBM보다 빠르게 학습을 완료할 수 있습니다.
- 기존 GBM은 과적합 교제 기능이 없으나 XGBoost는 자체에 과적합 규제 기능이 있습니다.
- 다른 GBM과 마찬가지로 XGBoost도 max_depth 파라미터로 분할 깊이를 조정하기도 하지만, tree pruning으로 더 이상 긍정 이득이 없는 분할을 가지치기해서 분할 수를 더 줄이는 추가적인 장점을 가지고 있습니다.
- Early Stopping(조기 종료) 기능이 있습니다.
- 일반 파라미터: 일반적으로 실행 시 스레드의 개수나 slient 모드 등의 선택을 위한 파라미터로서 디폴트 파라미터 값을 바꾸는 경우는 거의 없습니다.
- 부스터 파라미터: 트리 최적화, 부스팅, regularization 등과 관련 파라미터 등을 지칭합니다.
- 학습 테스트 파라미터: 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정하는 파라미터입니다.
파라미터
- 일반 파라미터
- booster: gbtree(tree based model) 또는 gblinear(linear model) 선택, 디폴트는 gbtree입니다.
- slient: 디폴트는 0이며, 출력 메시지를 나타내고 싶지 않을 경우 1로 합니다.
- nthread: CPU의 실행 스레드 개수를 조정하며, 디폴트는 CPU의 전체 스레드를 다 사용하는 것입니다.
- 주요 부스터 파라미터
- eta [default=0.3, alias: learning_rate]: 학습률입니다. 0에서 1 사이의 값
- num_boost_rounds: n_estimators와 같은 파라미터입니다.
- min_child_weight [default=1]: 트리에서 추가적으로 가지를 나눌지 결정하기 위해 필요한 데이터들의 weight 총합
- gamma [default=0, alias: min_split_loss]: 트리의 리프 노드를 추가적으로 나눌지 결정할 최소 손실 감소 값입니다.
- max_depth: 트리의 깊이, 0을 지정하면 깊이에 제한이 없습니다.
- sub_sample [default=1]: 0~1 사이의 값, 데이터를 샘플링하는 비율
- colsample_bytree [default=1]: GBM의 max_features와 유사, 트리 생성에 필요한 피처를 임의로 샘플링
- lambda [default=1, alias: reg_lambda]: L2 규제 적용 값
- alpha [default=0, alias: reg_alpha]: L1 규제 적용 값
- scale_pos_weight [default=1]: 특정 값으로 치우친 비대칭 클래스의 데이터 세트의 균형을 유지하기 위한 파라미터
- 학습 태스크 파라미터
- objective: 최솟값을 가져야 할 손실 함수를 정의, 주로 사용되는 손실 함수는 이진 분류인지 다중 분류인지에 따라 달라짐
- binary:logistic: 이진 분류일 때 적용
- multi:softmax: 다중 분류일 때 적용
- multi:softprob: multl:softmax와 유사하나 개별 레이블 클래스의 해당되는 예측 확률을 반환
- eval_metric: 검증에 사용되는 함수를 정의
- rmse: Root Mean Square Error
- mae: Mean Absolute Error
- logloss: Negative log-likelihood
- error: Binary Classification error rate(0.5 threshold)
- merror: Multiclass classification error rate
- mlogloss: Multiclass logloss
- auc: Area under the curve
- objective: 최솟값을 가져야 할 손실 함수를 정의, 주로 사용되는 손실 함수는 이진 분류인지 다중 분류인지에 따라 달라짐
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
# XGBoost는 학습용 테스트용 데이터 세트를 위해 DMatrix객체를 생성해야함
dtrain = xgb.DMatrix(data=train_x, label=train_y)
dtest = xgb.DMatrix(data=test_x, label=test_y)
params = {'max_depth':3,
'eta': 0.1,
'objective':'binary:logistic',
'eval_metric':'logloss',
'early_stoppings':100}
num_rounds = 400
# 조기 종료를 위해 eval_set과 eval_metric이 함께 설정 돼어야 함
wlist = [(dtrain, 'train'), (dtest, 'eval')]
xgb_model = xgb.train(params=params, dtrain=dtrain, num_boost_round=num_rounds,
early_stopping_rounds=100, evals=wlist)
# xgboost의 predict는 결괏값이 아닌 확률 값을 반환함
pred_prob = xgb_model.predict(dtest)
preds = [1 if i > 0.5 else 0 for i in pred_prob]
print(pred_prob[:10])
print(preds[:10])
print('XGBoost의 정확도: {:.4f}'.format(accuracy_score(test_y, preds)))
from xgboost import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)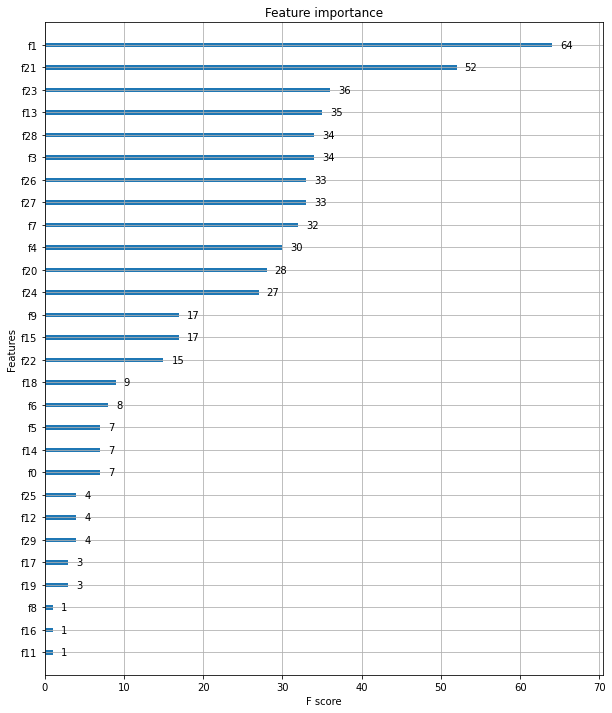
사이킷런 래퍼 XGBoost
- eta -> learning_rate
- sub_sample -> subsample
- lambda -> reg_lambda
- alpha -> reg_alpha
사이킷런 래퍼로 변화면서 바뀐 하이퍼 파라미터들입니다.
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
evals = [(test_x, test_y)]
xgb_wrapper.fit(train_x, train_y, early_stopping_rounds=100, eval_metric='logloss',
eval_set=evals, verbose=True)
preds = xgb_wrapper.predict(test_x)
pred_proba = xgb_wrapper.predict_proba(test_x)[:, 1]
print(preds[:10])
print(pred_proba[:10])
print("XGBoost 정확도 : {:.4f}".format(accuracy_score(preds, test_y)))
LightGBM
- 위의 XGBoost보다 학습시간이 훨씬 더 적습니다.
- 메모리 사용량이 낮습니다.
- 한 가지 단점으로 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉽습니다.
위의 모든 트리구조의 알고리즘은 level-wise구조이지만, Light GBM은 leaf-wise 구조입니다. 균형 잡힌 트리를 생성하는 이유는 오버 피팅에 보다 더 강한 구조를 가질 수 있다고 알려져 있기 때문입니다. 반대로 균형을 맞추기 위한 시간이 필요하다는 단점이 있습니다. 리프 중심 트리 분할 방식은 트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 규칙 트리가 생성됩니다.
동일한 leaf를 확장할 때, leaf-wise알고리즘이 level-wise 알고리즘보다 더 많은 loss를 줄일 수 있었습니다.
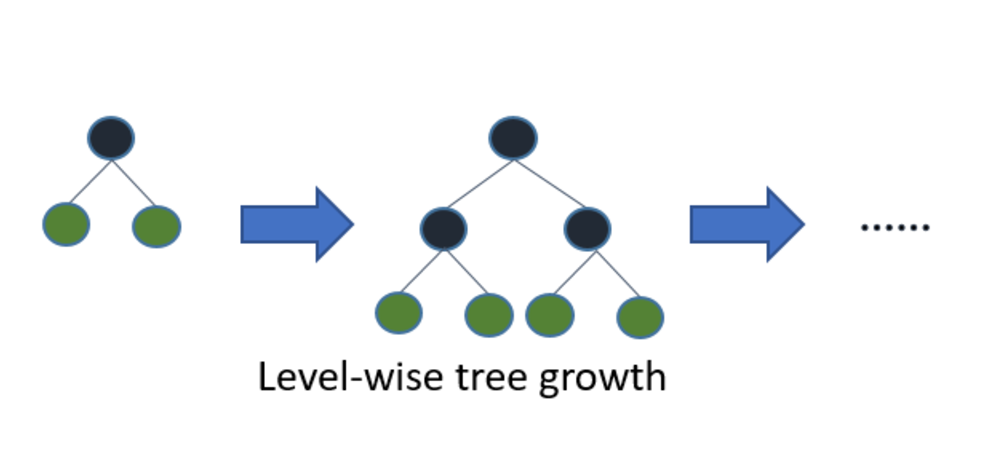
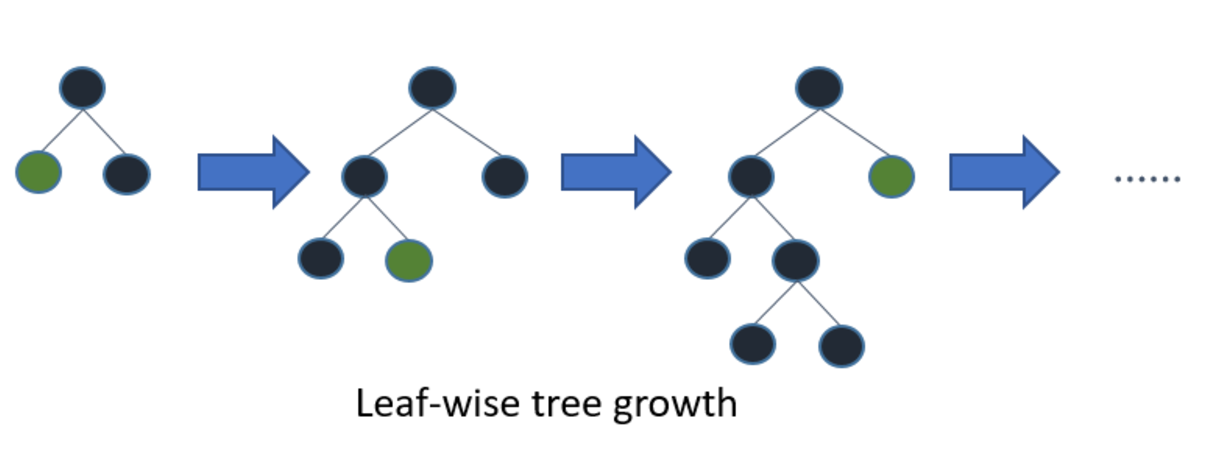
파라미터
- num_iteration [default=100] : 반복 수행하기 위한 트리의 개수 지정. 크게 지정할수록 예측 성능이 높아질 수 있지만 과적합 문제 가능성 또한 높아짐. n_estimator와 같음
- learning_rate [default=0.1] : 0~1 사이의 값을 지정해 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률 값. 일반적으로 n_estimators를 크게 하고 learning_rate을 작게 해서 예측 성능 향상 가능, 과적합 이슈 동반.
- max_depth [default=-1]: 0보다 작은 값을 지정하면 깊이에 제한 없음.
- min_data_in_leaf [default=20] : 결정 트리의 min_samples_leaf와 동일. 최종 결정 클래스인 리프 노드가 되기 위해 최소한으로 필요한 레코드 수. (과적합 방지용)
- num_leaves [default=32] : 하나의 트리가 가질 수 있는 최대 리프 수
- boosting [default=gbdt] : 부스팅 트리를 생성하는 알고리즘 (gbdt:일반적인 그래디언트 부스팅, rf:랜덤 포레스트)
- bagging_fraction [default=1.0] : 트리가 커져서 과적합 되는 것을 방지하기 위한 데이터 샘플링 비율.
- feature_fraction [default=1.0] : 개별 트리를 학습할 때 무작위로 선택되는 피처의 비율 (GBM의 max_features와 동일)
- lambda_I2 [default=0.0] : L2 regulation 제어를 위한 값. 피처 개수가 많을 경우 적용 검토. 값이 클수록 과적합 감소 효과
- lambda_I1 [default=0.0] : L1 regulation 제어를 위한 값. 과적합 방지용.
import lightgbm as lgb
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
train_data = lgb.Dataset(train_x, train_y)
eval_data = lgb.Dataset(test_x, test_y)
params = {'max_depth':3,
'learning_rate ': 0.1,
'objective':'binary',
'metric':'binary_logloss'
}
num_rounds = 400
lgb_model = lgb.train(params, train_data, num_boost_round=num_rounds,
early_stopping_rounds=100, valid_sets=eval_data )
pred_prob = lgb_model.predict(test_x)
preds = [1 if i > 0.5 else 0 for i in pred_prob]
print(pred_prob[:10])
print(preds[:10])
print('LightGBMoost의 정확도: {:.4f}'.format(accuracy_score(test_y, preds)))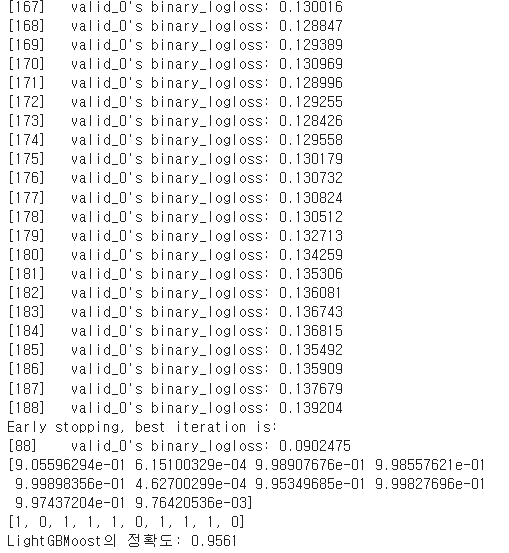
사이킷런 래퍼
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(cancer['data'], cancer['target'], test_size=0.2)
lgb_wrapper = LGBMClassifier(n_estimators=400)
evals = [(test_x, test_y)]
lgb_wrapper.fit(train_x, train_y, early_stopping_rounds=100, eval_metric='logloss',
eval_set=evals, verbose=True)
preds = xgb_wrapper.predict(test_x)
pred_proba = xgb_wrapper.predict_proba(test_x)[:, 1]
print(preds[:10])
print(pred_proba[:10])
print("LightGBM 정확도 : {:.4f}".format(accuracy_score(preds, test_y)))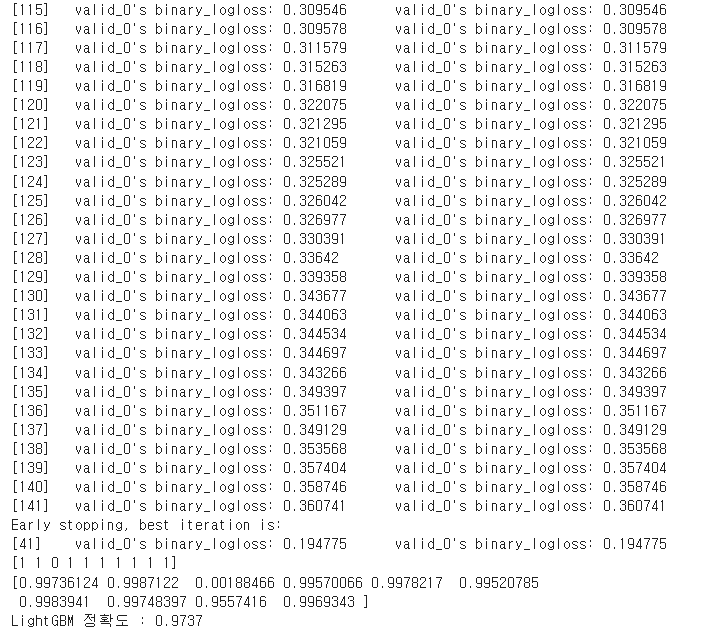
from lightgbm import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgb_wrapper, ax=ax)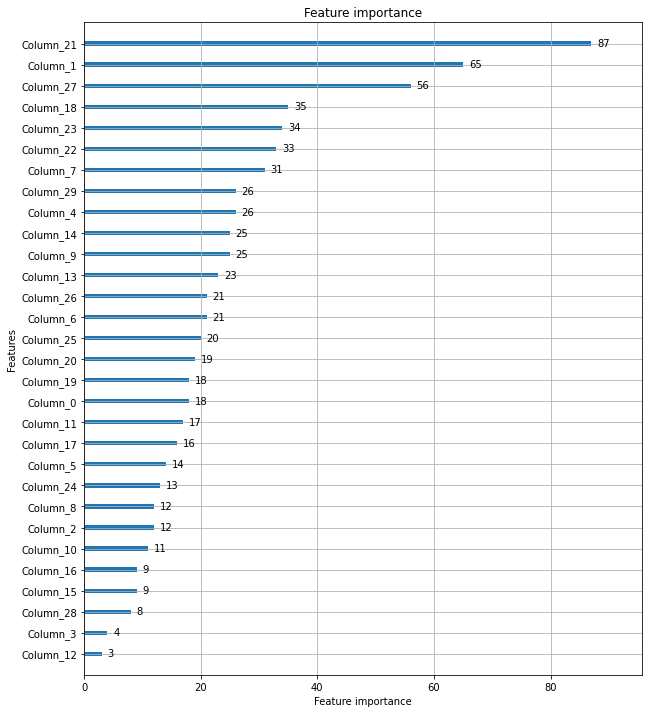
'머신러닝' 카테고리의 다른 글
| [머신러닝] K-Nearest Neighbors (0) | 2022.05.06 |
|---|---|
| [머신러닝] Naive Bayes (0) | 2022.05.06 |
| [머신러닝] 의사결정트리(Decision Tree) 알고리즘 (2) | 2022.05.05 |
| [머신러닝] 성능 평가 지표 (0) | 2022.05.04 |
| [머신러닝] Logistic Regression (0) | 2022.05.04 |




댓글