모델 학습 방법
1. 모델 기반 학습(Model-Based Learning)
데이터로부터 모델을 생성하여 분류/예측 진행
ex) Linear Regression, Logistic Regression

2. 사례 기반 학습(Instance-Based Learning)
- 별도의 모델 생성 없이 인접 데이터를 분류/예측에 사용
- Lazy Learning
- 모델을 미리 만들지 않고, 새로운 데이터가 들어오면 계산을 시작
- KNN, Naive Bayes
KNN
- K 개의 가까운 이웃을 찾는다.
- 학습 데이터 중 K개의 가장 가까운 사례를 사용하여 분류 및 수치 예측
- 새로운 데이터를 입력 받음
- 모든 데이터들과의 거리를 계산
- 가장 가까운 K개의 데이터를 선택
- K개 데이터의 클래스를 확인
- 다수의 클래스를 새로운 데이터의 클래스로 예측
1) 새로운 데이터를 입력 받음
2) 모든 데이터들과의 거리를 계산
3) 가장 가까운 K개의 데이터를 선택
4) K개 데이터의 클래스를 확인
5) 다수의 클래스를 새로운 데이터의 클래스로 예측
교차 검증을 통해 제일 성능이 좋은 K를 선택해야 합니다.
K가 적을수록 Overfitting이 나고, 많을수록 Underfitting이 납니다.
K가 짝수일 경우 동점이 발생할 수 있기 때문에, 홀수로 설정해야 합니다.
유클리드 거리(Euclidean Distance)
- 두 점 사이의 거리를 계산할 때 흔히 쓰는 방법입니다.
- 두 점 사이의 최단거리를 의미합니다.
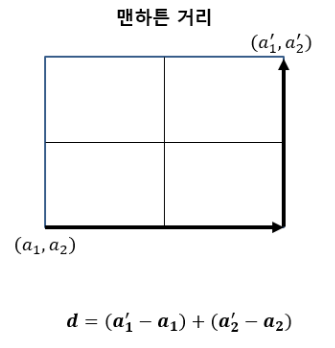
맨해튼 거리(Manhattan Distance)
한 번에 한 축 방향으로 움직일 수 있을 때 두 점 사이의 거리
- KNN은 학습 과정이 없고, 결과를 이해하기가 쉽습니다.
- 데이터가 많을수록 시간이 오래 걸리고, 지나치게 데이터에 의존적입니다.
붓꽃 데이터 종류를 2개로 축약하고, 피쳐도 시각화를 위해 2개만 쓰겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
data = iris['data']
target = iris['target']
data = data[target != 0, 2:]
target = target[target != 0]
data = pd.DataFrame(data)
target = pd.DataFrame(target)
target = target.loc[~data.duplicated()].values.flatten()
data = data.loc[~data.duplicated()].values
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.2, stratify=target)
plt.scatter(train_x[:, 0], train_x[:, 1], c=train_y)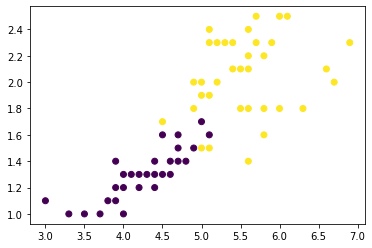
K를 바꿔가며 정확도를 확인해보겠습니다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
preds = []
for idx, n in enumerate(range(1, 12, 2)):
#n_neightbors는 주변 이웃 갯수, p=1 이면 맨해튼, p=2 이면 유클리드
knn = KNeighborsClassifier(n_neighbors=n, p=2)
knn.fit(data, target)
Z = knn.predict(test_x)
acc = accuracy_score(Z, test_y)
preds.append([n, acc])
for x, y in preds:
print('K: {0}, 정확도: {1}'.format(x, y))
kneighbors는 데이터, 데이터의 근처 개수, 거리 반환 순으로 입력합니다.
knn.fit(train_x, train_y)
knn_neightbors_idx = knn.kneighbors(
test_x[1].reshape(1, -1), n_neighbors=10, return_distance=False
).ravel()
near_data = train_x[knn_neightbors_idx]
near_label = train_y[knn_neightbors_idx]
plt.scatter(train_x[:, 0], train_x[:, 1], c=train_y)
plt.scatter(test_x[1][0], test_x[1][1], marker='*')
plt.scatter(near_data[:, 0], near_data[:, 1], c=near_label, edgecolors="red")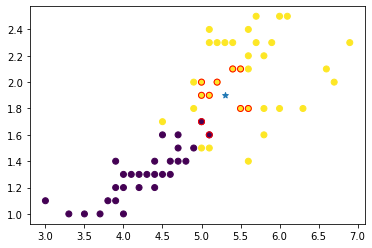
거리 기반으로 모델을 학습하기 때문에 Scaling을 시켜주어야 합니다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 군집화 (0) | 2022.05.06 |
|---|---|
| [머신러닝] SVM (0) | 2022.05.06 |
| [머신러닝] Naive Bayes (0) | 2022.05.06 |
| [머신러닝] 앙상블(Ensemble) (0) | 2022.05.06 |
| [머신러닝] 의사결정트리(Decision Tree) 알고리즘 (2) | 2022.05.05 |




댓글