추천 시스템이란?
특정 사용자가 관심 가질만한 정보를 추천하는 시스템으로, 사용자의 취향을 알아내 새로운 아이템을 추천하는 것입니다.
ex) 영화, 음악, 책, 뉴스...
사례)
넷플릭스 : 고객의 영화 평가를 바탕으로 특정 고객에게 영화를 추천하는 서비스
아마존 : 협업 필터링 알고리즘 기반 추천 시스템 적용

정보 필터링 방법과 연관성 분석 등 다양한 추천 기법이 연구되고 있습니다.
유사도 정의
비슷한 정도를 나타내는 지표
종류
- 유클리디안 유사도
- 코사인 유사도
- 피어슨 유사도
- 자카드 유사도

유클리디안 유사도
유클리디안 거리의 역수로 정의
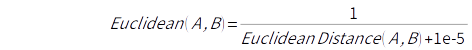
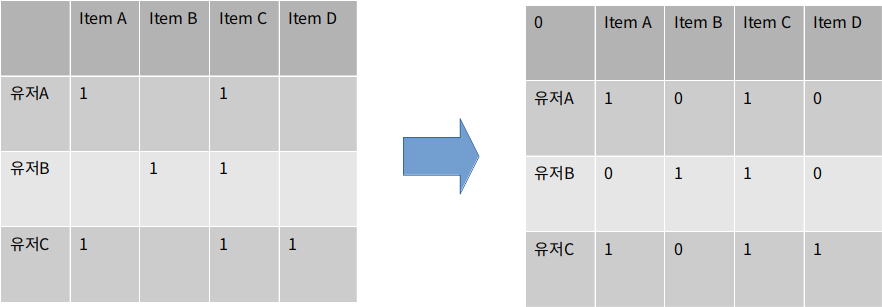
EUCLIDEAN DISTANCE OF USER A AND USER B

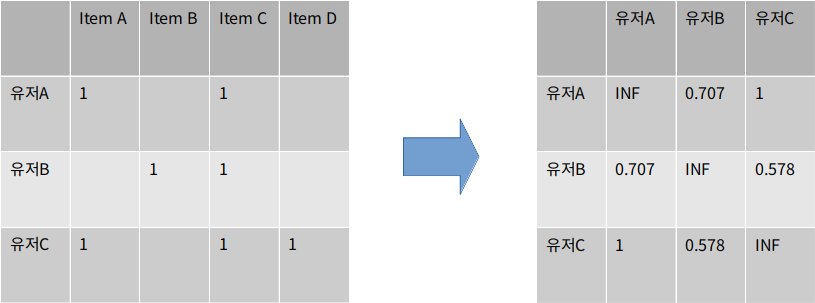
유사한 유저: 유저 A & 유저 C
코사인 유사도
두 벡터 간의 코사인 각도를 이용해 계산

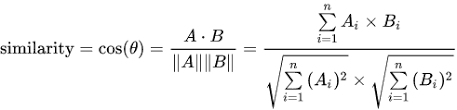
Cosine Similarity DISTANCE OF USER A AND USER B
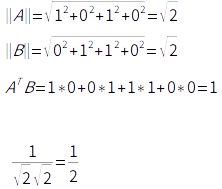
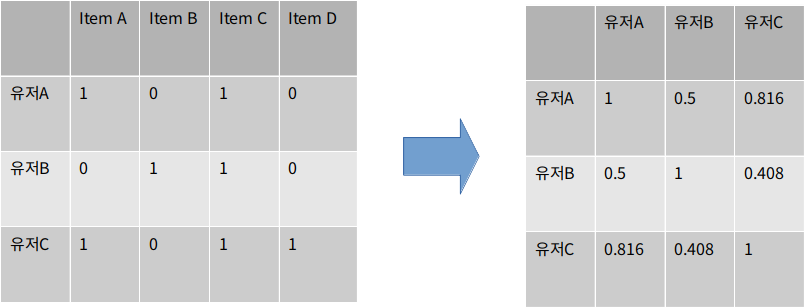
유사한 유저: 유저 A & 유저 C
피어슨 유사도
두 벡터의 상관 계수로 정의
유저 또는 아이템별로 가지는 특성을 제거

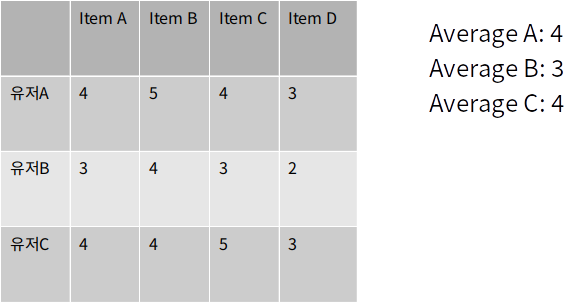


피어슨 유사도는 유저 특성을 제거해 점수가 편향된 경우 효과적
자카드 유사도
유저가 상호작용한 아이템의 합집합과 교집합의 비율로 계산


유저가 아이템에 평가한 점수의 크기가 무시됨
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import euclidean_distances
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics import jaccard_score
np.random.seed(2021)
data = [
[1., None, 1., None],
[None, 1., 1., None],
[1., None, 1., 1.],
]
df = pd.DataFrame(
data = data,
index = ['userA', 'userB', 'userC'],
columns=['itemA', 'itemB', 'itemC', 'itemD']
)
df = df.fillna(0)
#유저와 유저사이의 유클리디안 거리
# euclidean_distances(
# X = df.loc[['userA']],
# Y = df.loc[['userB']]
# )
# euclidean_distances에 X만 입력할 경우, X의 모든 Row사이의 유클리디안 거리를 계산합니다.
# 전체 데이터를 입력할 경우 모든 유저 사이의 유클리디안 거리를 계산할 수 있습니다.
distance = euclidean_distances(df)
similarity = 1 / (distance + 1e-5)
print('Euclidean_similarity: \n', similarity)
# 코사인 유사도 계산
print('cosine_similarity: \n', cosine_similarity(df))
#피어슨 유사도 계산
print('pearson_similarity: \n', np.corrcoef(df))
# 피어슨 유사도는 유저 또는 아이템 별로 특성을 제거한 데이터에 코사인 유사도
# 적용한 것과 같습니다.
user_mean = df.mean(axis=1)
df_sub = df.sub(user_mean, axis=0)
print('pearson_similarity2: \n', cosine_similarity(df_sub))
#자카드 유사도 계산
df[df > 0] = 1
print(jaccard_score(df.loc['userB'], df.loc['userC']))Euclidean_similarity:
[[1.00000000e+05 7.07101781e-01 9.99990000e-01]
[7.07101781e-01 1.00000000e+05 5.77346936e-01]
[9.99990000e-01 5.77346936e-01 1.00000000e+05]]
cosine_similarity:
[[1. 0.5 0.81649658]
[0.5 1. 0.40824829]
[0.81649658 0.40824829 1. ]]
pearson_similarity:
[[ 1. 0. 0.57735027]
[ 0. 1. -0.57735027]
[ 0.57735027 -0.57735027 1. ]]
pearson_similarity2:
[[ 1. 0. 0.57735027]
[ 0. 1. -0.57735027]
[ 0.57735027 -0.57735027 1. ]]
0.25
Contents Based Filtering (콘텐츠 기반 필터링)
추천 시스템은 Utility Matrix에 기반하고 있습니다.
Utility Matrix는 어떤 유저가 어떤 아이템들을 구매했는지 나타내는 행렬입니다.
콘텐츠 기반 필터링은 '내용(Content)'에 알맞은 아이템을 추천해주는 것입니다.
유저 X가 아이템 Y를 구매했다면, Y와 비슷한 아이템을 추천해주는 것입니다.
아이템의 프로필을 이용한 아이템 간의 유사성 계산
영화: 장르, 감독, 배우, 개봉일, 소개글...
제품: 카테고리, 브랜드, 가격, 제품명...
영화 A(코미디), 영화 B(액션), 영화 C(코미디)
영화 A를 봤다고 하면, 영화 C와 장르가 같기 때문에 영화 C를 추천하는 것입니다.
TF-IDF
- Term Frequency - Inverse Document Frequency
- 텍스트 기반 콘텐츠의 특징 벡터를 추출하는 방법
- 출현 빈도를 이용해 특성 문서 (d) 내에서 키워드 (w)의 중요도를 측정
- 자주 등장하는 키워드는 낮은 중요도를 부여
TF - IDF(w, d) = TF(w, d) * IDF(w)
- TF: 특정 문서 내에 특정 키워드가 등장하는 빈도
- TF(w, d) = 문서 d에 속한 키워드 w의 수
- DF: 전체 문서 내에 특정 키워드가 등장하는 빈도
- DF가 큰 경우 보편적인 키워드
- IDF: DF의 역수
- IDF(w) = log(전체 문서의 수 / 키워드 w가 포함된 문서의 수(DF))
Step 1) TF를 계산합니다.
TF(w, d) = 문서 d에 속한 키워드 w의 수
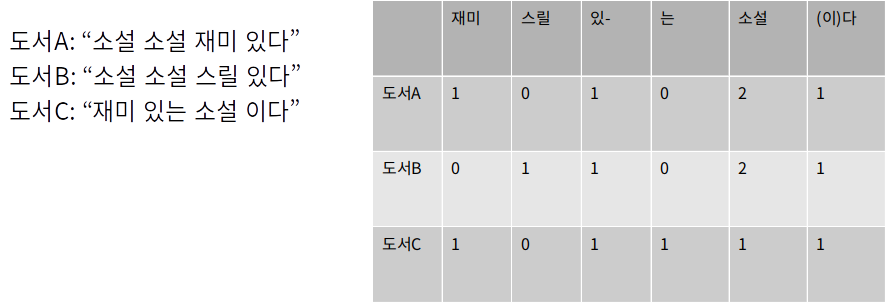
Step 2)
- IDF(w) = log(전체 문서의 수 / 키워드 w가 포함된 문서의 수(DF))
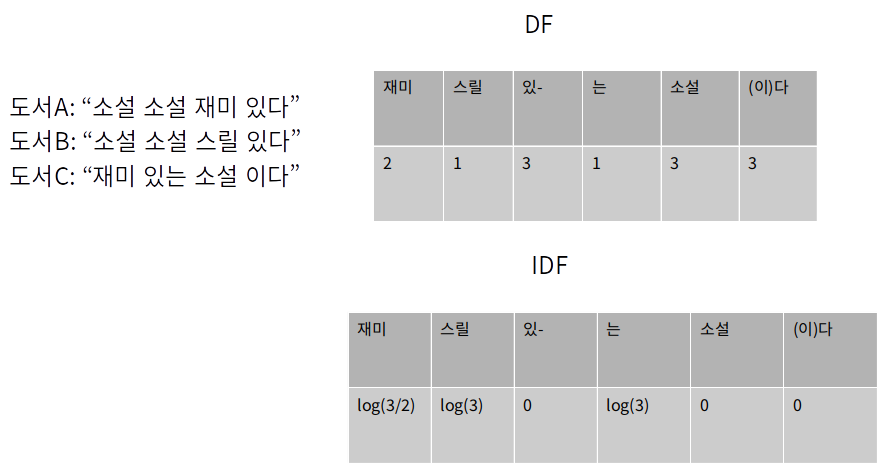
Step 3)
TF - IDF(w, d) = TF(w, d) * IDF(w)

Contents Based Filtering 적용
코사인 유사도 계산
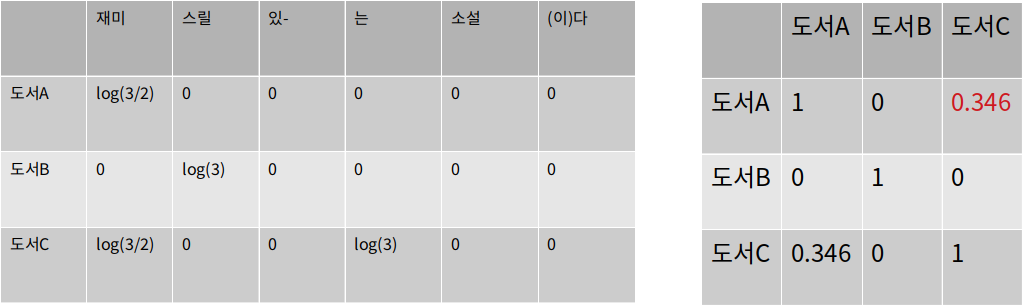
TF-IDF의 필요성
단어의 중요도를 반영하기 위함입니다.
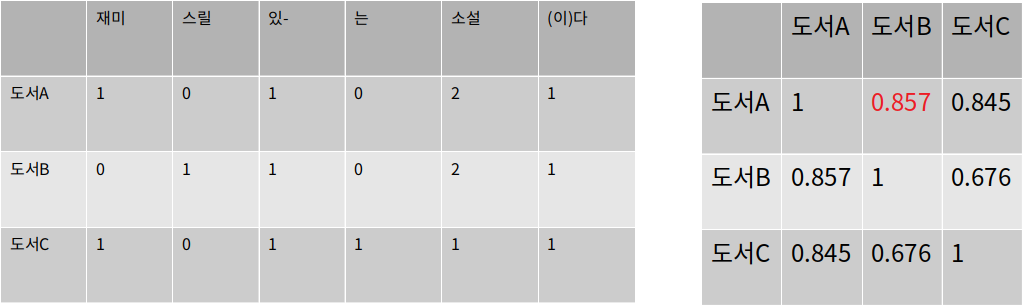
콘텐츠 기반 필터링의 장단점
장점
- 다른 사용자들의 데이터가 없어도 추천이 가능
- 추천을 제공받는 사용자의 컨텐츠 이용내역만 있으면 됩니다.
- 새로 추가된 아이템, 평점이 없는 유명하지 않은 아이템도 추천이 가능
- 아이템의 설명만 있다면 다양한 아이템이 후보군이 될 수 있음
- 추천을 하는 근거를 설명할 수 있음
단점
- 아이템의 설명을 구성하는 과정에서 주관성이 개입될 수 있음
- 사용자 A가 영화가 재미있다고 했지만, B는 재미없다고 평가할 수도 있음
- 사용자가 과거에 좋아했던 아이템을 제공하지 않으면 추천이 어려움
- 아이템 속성 정보 간의 연관성을 바탕으로 하기 때문에 아미 알거나, 알고 있는 유사한 아이템만을 추천
영화리뷰파일분석
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('movies_metadata.csv')
df = df[['title', 'overview']]
df.head(5)
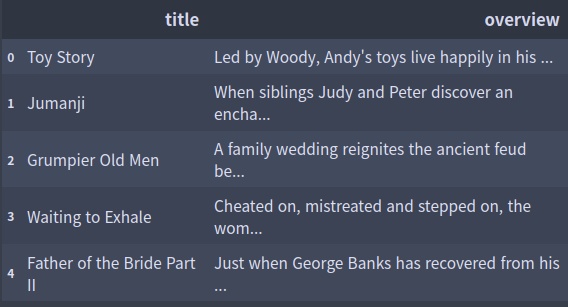
단어들 테이블화
from sklearn.feature_extraction.text import TfidfVectorizer
df['overview'] = df['overview'].fillna('')
transformer = TfidfVectorizer(stop_words='english')
tfidf_matrix = transformer.fit_transform(df['overview'].values[:2])
pd.DataFrame(tfidf_matrix.toarray(), columns=transformer.get_feature_names())
from sklearn.metrics.pairwise import cosine_similarity
transformer = TfidfVectorizer(stop_words='english')
tfidf_matrix = transformer.fit_transform(df['overview'])
#영화별 유사도 계산
similarity = cosine_similarity(tfidf_matrix)
# 10번째와 유사한 영화 추천
idx = 10
print('10th movie', df.loc[idx, 'title'])
similarity_one_idx = similarity[idx]
# 역순으로 가장 유사한 인덱스가 앞으로 오도록
order_idx = similarity_one_idx.argsort()[::-1]
df.loc[order_idx[:6], 'title']10th movie The American President
10 The American President
17042 My Dog Tulip
17491 Four Times
42295 Finding Rin Tin Tin
11849 Satan
4729 Kansas
Name: title, dtype: object
Collaborative Fiterling(협업 필터링)
여러 유저의 과거 아이템 상호작용 정보를 이용해 추천
상호작용
- 영화 평점
- 제품 사용 리뷰
- 동영상 시청 시간
- 클릭 횟수
메모리 기반(Memory Based) 협업 필터링
여러 유저의 과거 아이템 상호작용 정보를 메모리에 저장하고 추천이 필요할 때마다 전체 데이터를 이용해서 추천
- 유저 기반
- 아이템 기반
유저 기반
아이템 선호도가 비슷한 유저를 탐색하고 비슷한 유저가 좋아한 것 중에 새로운 아이템을 추천

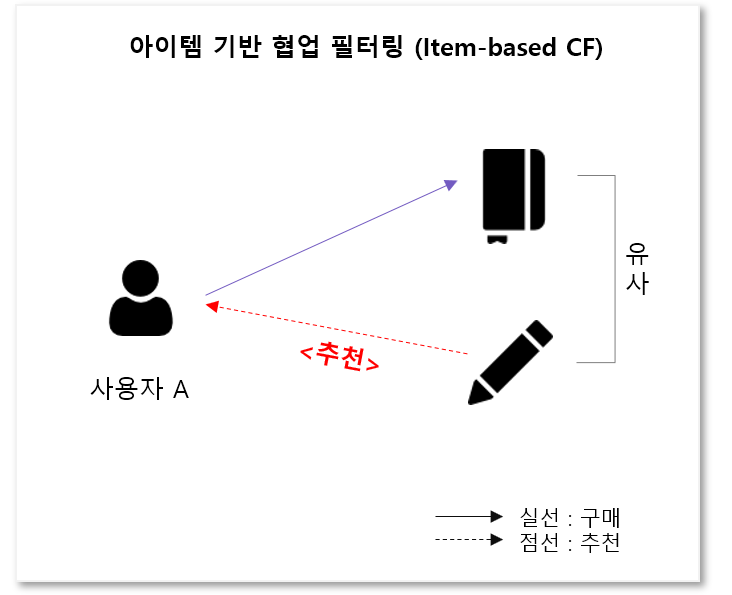
아이템 기반
유저들의 선호도가 비슷한 아이템을 탐색하고, 유저가 기존에 선호한 아이템과 유사한 아이템 추천
KNN 협업 필터링
1. KNN Basic
유저 기반
아이템 i에 대한 유저 u의 선호도 예측
- 유저 간의 유사도를 계산합니다.
- 아이템 i를 평가한 유저들 중에서 유저 u와 비슷한 유저 k명을 찾습니다.
- k명의 유사한 유저들이 아이템 i에 평가한 선호도를 유사도 기준으로 가중 평균합니다.
- 예측 선호도가 높은 아이템을 유저에게 추천합니다.
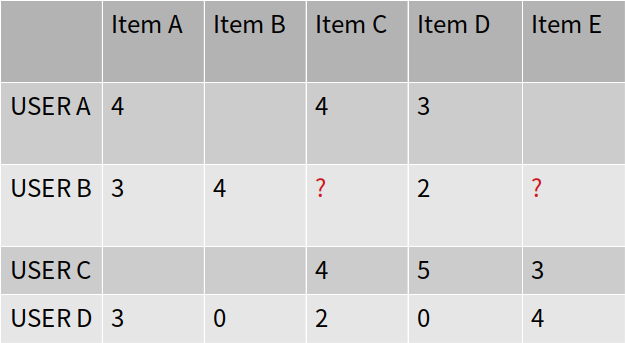
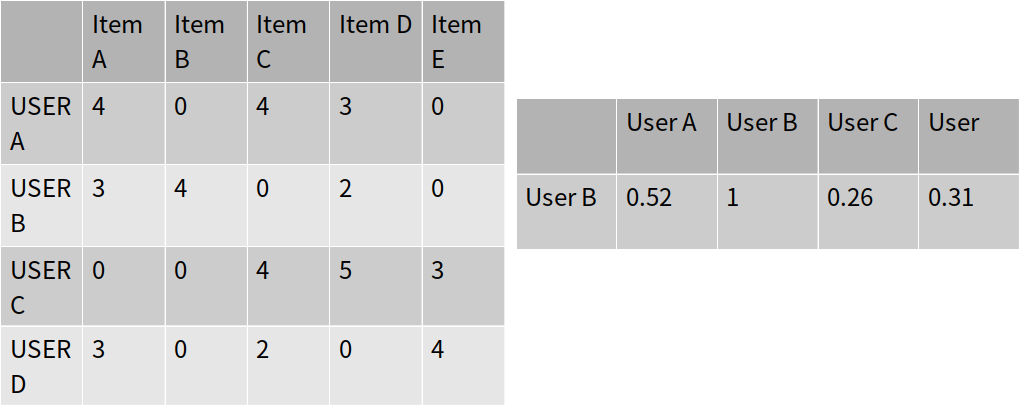
Step 1) 유저 간의 유사도를 계산합니다.(코사인 유사도)
Step 2) 아이템을 평가한 유저들 중에서 유저 u와 비슷한 K명을 찾습니다.

Step 3) K명이 유사한 유저들의 선호도를 유사도 기준으로 가중 평균합니다.

Step 4) 예측 선호도가 높은 아이템을 유저에게 추천함.

아이템 기반
- 아이템 간의 유사도를 계산한다.
- 아이템 i와 비슷한 아이템을 k개 찾는다.
- 유저가 평가한 K개의 아이템의 선호도를 유사도 기준으로 가중 평균한다.
- 예측 선호도가 높은 아이템을 유저에게 추천한다.
2. KNN with Means
- 선호도의 평균에 선호도 편차를 유사도 기준으로 가중 평균을 더하는 방법
- 유저나 아이템의 평균 선호도를 반영함
유저 기반
- 유저 간의 유사도를 계산합니다.
- 아이템 i를 평가한 유저들 중에서 유저 u와 비슷한 유저 k명을 찾습니다.
- 아이템 i의 평균 선호도를 계산합니다.
- K명의 유사한 유저들이 아이템 i에 평가한 선호도의 편차를 유사도 기준으로 가중평균을 구합니다.
- 예측 선호도가 높은 아이템을 유저에게 추천합니다.
아이템 기반
- 아이템 간의 유사도를 계산합니다.
- 아이템 i와 비슷한 아이템 k개를 찾습니다.
- 아이템 i의 평균 선호도를 계산합니다.
- 유저가 평가한 k개의 아이템의 선호도의 편차를 유사도 기준으로 가중 평균합니다.
- 예측 선호도가 높은 아이템을 유저에게 추천합니다.

Step 1) 아이템간의 유사도를 계산합니다.
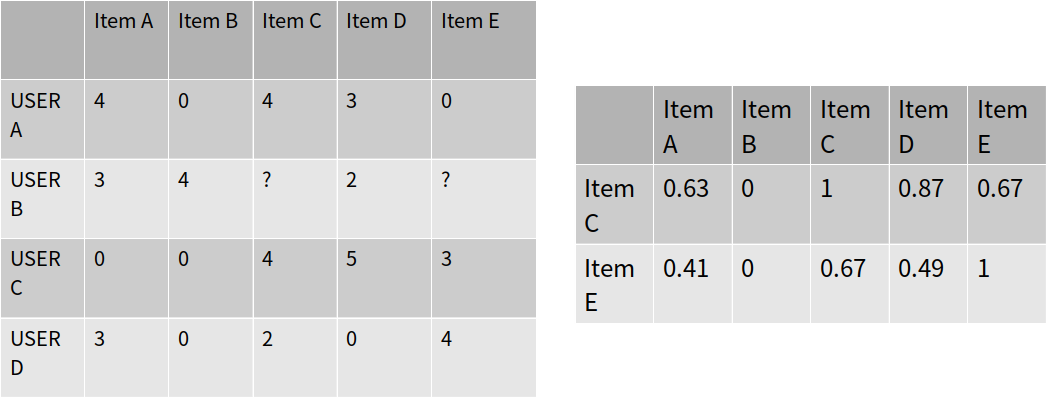
Step 2) 유저 u가 평가한 아이템들 중에서 비슷한 아이템 K개를 찾습니다.


Step 3) 아이템의 평균 선호도를 계산합니다.

Step 4) 유저가 평가한 K개의 아이템의 선호도의 편차를 유사도 기준으로 가중 평균합니다.

소제목 1
Step 5) 예측 선호도가 높은 아이템을 유저에게 추천합니다.
C, E 중 아이템 E 가 예상 점수가 높아 추천되지만, 모두 평균 점수보다 낮아 추천하지 않습니다.
협업 필터링(모델 기반)
여러 유저의 과거 아이템 상호작용 정보를 이용해 추천을 위한 모델을 학습하고, 학습된 모델을 이용해 추천
유저 - 아이템 행렬을 유저와 아이템 행렬로 분해하는 방법
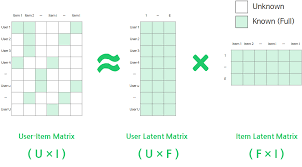
F : 유저와 아이템 행렬이 공유하는 잠재요인
Matrix Factorization
유저가 평가하지 않은 아이템에 대한 선호도를 예측 가능

유저-영화 평점 이력


유저-영화를 장르 선호도 요인으로 분해
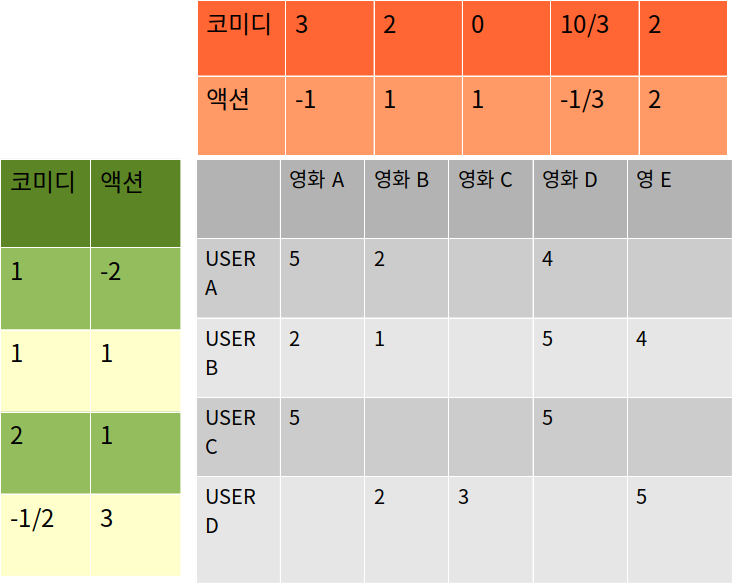
잠재요인을 이용해 영화 평점 예측

방법
Gradient Descent를 이용한 Matrix Factorization 학습
- P와 Q를 랜덤 값으로 초기화
- R^ 계산
- R과 R^의 오차 계산
- Gradient Desent를 이용해 P와 Q를 업데이트
- 2~4 과정 반복
Step 1) P와 Q를 랜덤 값으로 초기화
k = 2
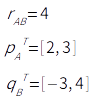
Step 2) R^ 계산

Step 3) R과 R^ 오차 계산

Step 4) Gradient Descent를 이용해 P와 Q를 업데이트
r = 0.005
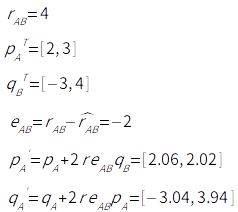
Step 5) 2~4 과정 반복
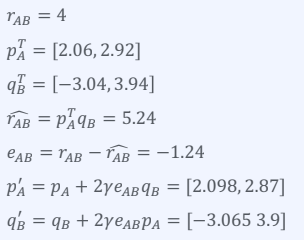
'머신러닝' 카테고리의 다른 글
| [머신러닝] 이상 탐지(Anomaly Detection) (0) | 2022.05.11 |
|---|---|
| [머신러닝] 차원축소 (0) | 2022.05.10 |
| [머신러닝] 군집화 (0) | 2022.05.06 |
| [머신러닝] SVM (0) | 2022.05.06 |
| [머신러닝] K-Nearest Neighbors (0) | 2022.05.06 |




댓글