참조
[논문리뷰] DETR: End-to-End Object Detection with Transformer
들어가며 본 논문은 Object Detection과 Transformer의 사전 지식이 있다는 가정하에 작성되었습니다. 오늘 리뷰할 논문은 DETR입니다. 이 논문은 Object Detection에 Transformer를 적용시킨 최초의 논문입니다.
lcyking.tistory.com
[논문 리뷰] Conditional DETR
들어가며 이 글은 DETR에 대한 사전지식이 있다는 가정하에 작성되었습니다. [논문리뷰] DETR: End-to-End Object Detection with Transformer 들어가며 본 논문은 Object Detection과 Transformer의 사전 지식이 있다는
lcyking.tistory.com
들어가며
DETR에는 최초로 Transformer 구조를 Object Detection에 적용하며 크게 각광을 받았지만, 500 Epoch 정도 돌아야 하는 낮은 수렴 속도에 대한 제한점이 있었습니다.
이 근본적인 원인은 Transformer 디코더 레이어에서 Cross-Attention하는 과정에 있고, 실제로 디코더를 제외하고 인코더만 구성했을 시 빠른 수렴속도를 가진다고 합니다. 그래서 이 디코더에서 낮은 수렴속도를 초래하는 것은 2가지 가설 중 하나 일 것이라고 정의하였습니다:
- 객체에 대한 쿼리를 학습하는 것 자체의 어려움(최적화의 어려움)
- 쿼리의 위치 정보와 Image Features의 sinusoidal 위치 정보가 다른 방식으로 인코딩 됨(위치 정보의 모호성)
먼저 수렴 속도에 제한을 거는 것이 최적화의 어려움인지 확인하기 위해, 본 논문에서는 잘 학습된 쿼리 가져와 고정시키고, 학습하여 성능을 확인해보았습니다.
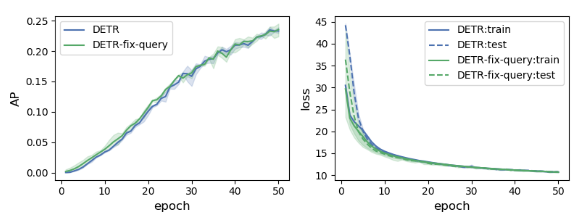
성능에 대한 변화가 눈에 띄게 나타나지를 않았습니다.
그럼 이제 나머지 가설인 위치 정보의 모호성을 확인해보기 위해 학습된 쿼리들과 Feature map의 위치 임베딩을 dot product를 취해 유사도를 분석한 결과를 시각화하였습니다.

왼쪽부터 (a) DETR, (b) Conditional DETR, (c) DAB-DETR인데 진할수록 객체의 위치를 표시한 결과라고 보시면 됩니다.
먼저 DETR을 보면 객체 쿼리와 Image Features의 Positional Encoding이 동일하지 않으니 한 장면에서 위치 정보가 들쭉날쭉하여 제대로 객체를 참조하지 못하는 것을 알 수 있습니다.
반면, Conditional DETR은 2D 좌표(x, y)에 대한 Prior를 삽입해 주었기 때문에 한 장면에 한 객체에 대한 위치 정보가 잘 학습된 것을 볼 수 있습니다. 그러나, 오로지 2D 좌표만 삽입해주었기 때문에 동일한 크기의 가우시안 형태를 띠고, 객체에 대한 스케일은 따로 고려하지 못한다는 점에서 제한점이 존재한다고 합니다.
위와 같이 기존에는 위치 정보에 대한 모호성이 있었습니다. 본 논문에서는 이 위치 정보 모호성에 대한 가설이 수렴 속도를 제한한다는 것을 확인하기 위해, 기존 2D에서 스케일을 고려한 4D(x, y, width, height)의 앵커 박스 형태를 Prior로 삽입해 주고 그 결과를 확인해 보았습니다.

+DAB(Dynamic Anchor Box)가 붙은 게 본 논문에서 제안하는 4D 앵커 박스 형태를 Prior로 삽입한 것이고, 성능이 눈에 띄게 좋아진 것을 확인할 수 있습니다. 이러한 결과로 4D 앵커 박스 형태를 Prior로 주입하는 것이 위치 정보의 모호성을 극복 및 수렴 속도를 가속화시킬 수 있다는 것이 증명되었습니다.
아울러 DAB의 Dynamic Anchor Box라는 어원에서 볼 수 있듯이, 이 앵커 박스는 Layer-by-Layer에서 동적으로 업그레이드됩니다. 이렇게 객체의 위치와 크기를 잘 고려한 위치 정보로 인한 성능 향상은 CNN의 RoI Pooling과 비슷한 역할을 하기 때문에 이라고 주장합니다.
그럼 이제 세부 구조가 어떻게 작동하는지 살펴보겠습니다.
DAB-DETR
전체적인 구조는 아래와 같습니다.
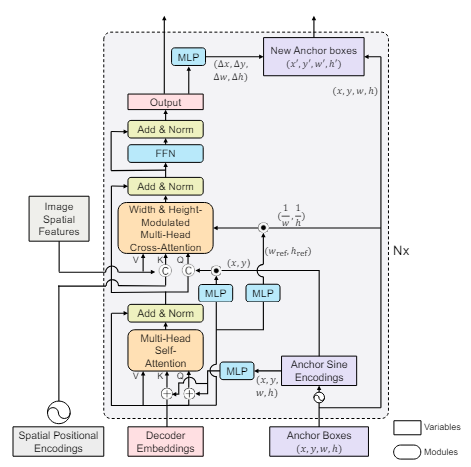
전체 구조는 CNN 백본, Transformer 인코더와 디코더로 구성되어 있고, 디코더의 쿼리는 Positional 쿼리와 Content 쿼리로 나누어진 구조로 Conditional DETR과 아주 유사합니다. 다만, 크게 다른 점이 있다면 Positional 쿼리가 2D 좌표에서 4D 앵커 박스로 바뀐 것과, 이 앵커가 각 레이어에서 점진적으로 GT와 가깝게 변한다는 것입니다.
4D 앵커 박스 학습
먼저, Content 쿼리는 \( C_q \in \mathbb {R}^D \)로 표기하고, Positional 쿼리는 \( P_q \in \mathbb {R}^D \)로 표기하고, \( P_q \)는 아래와 같이 구해집니다.

여기서 \( A_q = (x_q, y_q, w_q, h_q) \)는 sigmoid가 취해진 [0, 1] 범위의 앵커 박스의 좌표들이고, 이 좌표들을 sinusoidal 임베딩시키는 것이 PE이며, MLP는 Linear Layer(모든 레이어에서 파라미터를 공유)입니다.
\( A_q \)는 4D의 좌표(\( x_q, y_q, w_q, h_q \))로 구성되어 있어 아래와 같이 다시 풀어서 정리합니다.
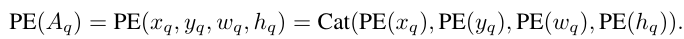
여기서 Cat은 concatenation 함수입니다. 각각의 좌표들은 D/2의 차원의 sinusoidal 임베딩(PE: \( \mathbb {R} -> \mathbb {R}^{D/2} \)) 시키고 총 4개의 좌표들을 Cat 하기 때문에 2D의 차원이 구성됩니다. 이어서 2D차원을 D차원으로 사영(MLP: \( \mathbb {R}^{2D} -> \mathbb {R}^D \))시킵니다.
수정된 Attention 모듈
위와 같은 과정으로 Positional 쿼리 \( P_q \)는 D차원으로 구성되고, Content 쿼리 Self-Attention의 연산 과정에 summation으로 위치 정보가 입력됩니다.

Cross-Attention도 Conditional DETR과 동일하게 Content 쿼리와 Postional 쿼리를 나누어 연산하는 방식으로 진행됩니다. 기존과 똑같으니 설명을 생략하겠습니다.
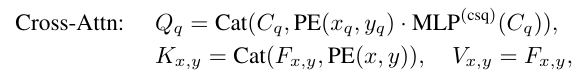
그리고 기존 Conditional DETR의 Positional 쿼리에 대한 Cross-Attn의 연산은 아래와 같이 계산됩니다.

위 연산은 x, y에 대한 Attention만 진행하기 때문에, 앞서 전술한 그림 1과 같이 스케일을 고려하지 못한 가우시안 형태가 되므로, 본 논문에서는 아래와 같이 스케일을 고려하여 가우시안의 크기가 객체의 크기에 잘 맞춰질 수 있게 수정하였습니다.


앵커박스 동적 업데이트
마지막으로, 앵커 박스는 Layer-by-Layer에서 동적으로 업그레이드된다고 하였습니다. Self-Attn, Cross-Attn의 연산이 끝나고, Prediction head에서 상대적인 좌표, 즉 Offset(\( \Delta x, \Delta y, \Delta w, \Delta h \))를 구하여, 기존 앵커의 좌표와 Summation 하여 업데이트합니다.
마치며
위에서 설명한 것 외에, sinusoidal 함수의 temperature T값도 수많은 문장과 단어로 구성된 자연어의 경우에 10000이 적당하지, DETR과 같이 객체에 대한 BBox는 20이면 충분하다고 합니다. 이 부분은 아마 실험으로 더 나은 성능을 기록했기 때문일 겁니다.
그리고 아래는 기존 모델들과 네트워크를 비교한 것입니다.

주관적인 생각으로는 Conditional DETR과 거의 비슷한 네트워크 구조를 가지지만, width와 height의 정보를 집어넣으려고 네트워크를 복잡하게 구성하여 어떻게든 성능을 이끌어 낸 것 같습니다. 기존 모델보다 연산이 확연하게 많아졌네요.
이상 DAB DETR의 포스팅을 마치겠습니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Object Detection' 카테고리의 다른 글
| [논문리뷰] Anchor DETR (2) | 2024.04.17 |
|---|---|
| [논문 리뷰] Denoising DETR(DN-DETR) (0) | 2024.04.04 |
| [논문 리뷰] Conditional DETR (0) | 2024.03.29 |
| [논문 리뷰] Deformable DETR (0) | 2024.03.28 |
| [논문리뷰] DETR: End-to-End Object Detection with Transformer (0) | 2024.03.22 |




댓글