들어가며
이 글은 DETR와 Deformable Convolution에 대한 사전지식이 있다는 가정하에 작성되었습니다.
[논문리뷰] DETR: End-to-End Object Detection with Transformer
들어가며 본 논문은 Object Detection과 Transformer의 사전 지식이 있다는 가정하에 작성되었습니다. 오늘 리뷰할 논문은 DETR입니다. 이 논문은 Object Detection에 Transformer를 적용시킨 최초의 논문입니다.
lcyking.tistory.com
본 논문은 DETR의 후속 연구입니다. 후속 연구인만큼 기존 DETR의 제한점을 극복하고 더 나은 차별점을 내세운 논문이겠지요.
기존 DETR은 Transformer 구조를 Object Detection에 도입하면서, CNN으로 구성되는 Object Detection의 패더라임을 전환하였습니다. 하지만 기존 DETR은 2가지 제한점이 존재하였습니다.
- 수렴속도가 너무 느림
- 작은 Object에 대한 낮은 성능
DETR을 수렴하려고 학습시키면 적어도 500Epoch정도는 돌아야 합니다. 이에 따른 낮은 수렴 속도에 대한 제한점은 DETR 원문에도 작성되어 있습니다.
그리고 CNN에서도 그랬듯이, 높은 해상도에서 Feature를 추출해야 작은 객체에 대한 Detection 성능이 올라가는데, Transformer 구조상 높은 해상도에서 Attention을 수행하면 계산복잡도와 메모리 사용량이 기하급수적으로 올라갑니다.
본 논문에서는 이러한 제한점을 극복하기 위해, Deformable Convolution에 대한 메커니즘을 도입하였습니다.
Deformbable Convolution Review
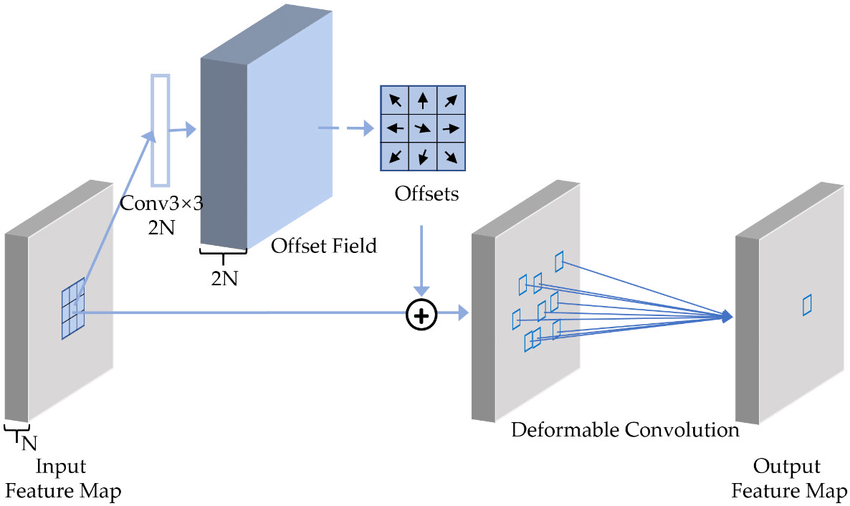
Deformable에 대한 설명을 간단하게 드리자면, 기존 Convolution layer는 3*3이든 2*2든 고정된 커널을 가지고 Feature map을 추출하는 과정입니다. 그런데 이 고정된 커널을 가지고 Feature를 추출하는 건 너무 제한적인 Representations만 추출한다고 합니다.
그래서, 위 그림같이 커널 자체를 Convolution으로 학습시켜, Offsets(커널의 각 Cell이 이동할 위치)를 구하고, 커널에 이 Offsets을 더해 새로운 커널을 탄생시키는 것입니다. 이 새로운 커널들은 기존 커널과 같이 정수의 좌표가 아닌, 소수의 좌표이므로, 주변 픽셀들의 Feature 값들과의 Bilinear Interpolation으로 값을 추출합니다. Bilinear Interpolation에 대한 설명은 생략하겠습니다. 이렇게 변형된 Convolution에 서 Features 값을 추출하는 것이 Deformable Convlution입니다.
Deformbable Attention
위 메커니즘을 DETR에 도입한 것이 Deformable DETR입니다. 그럼 이 매커니즘을 어떻게 도입했느냐 하면, 아래 그림과 같습니다.
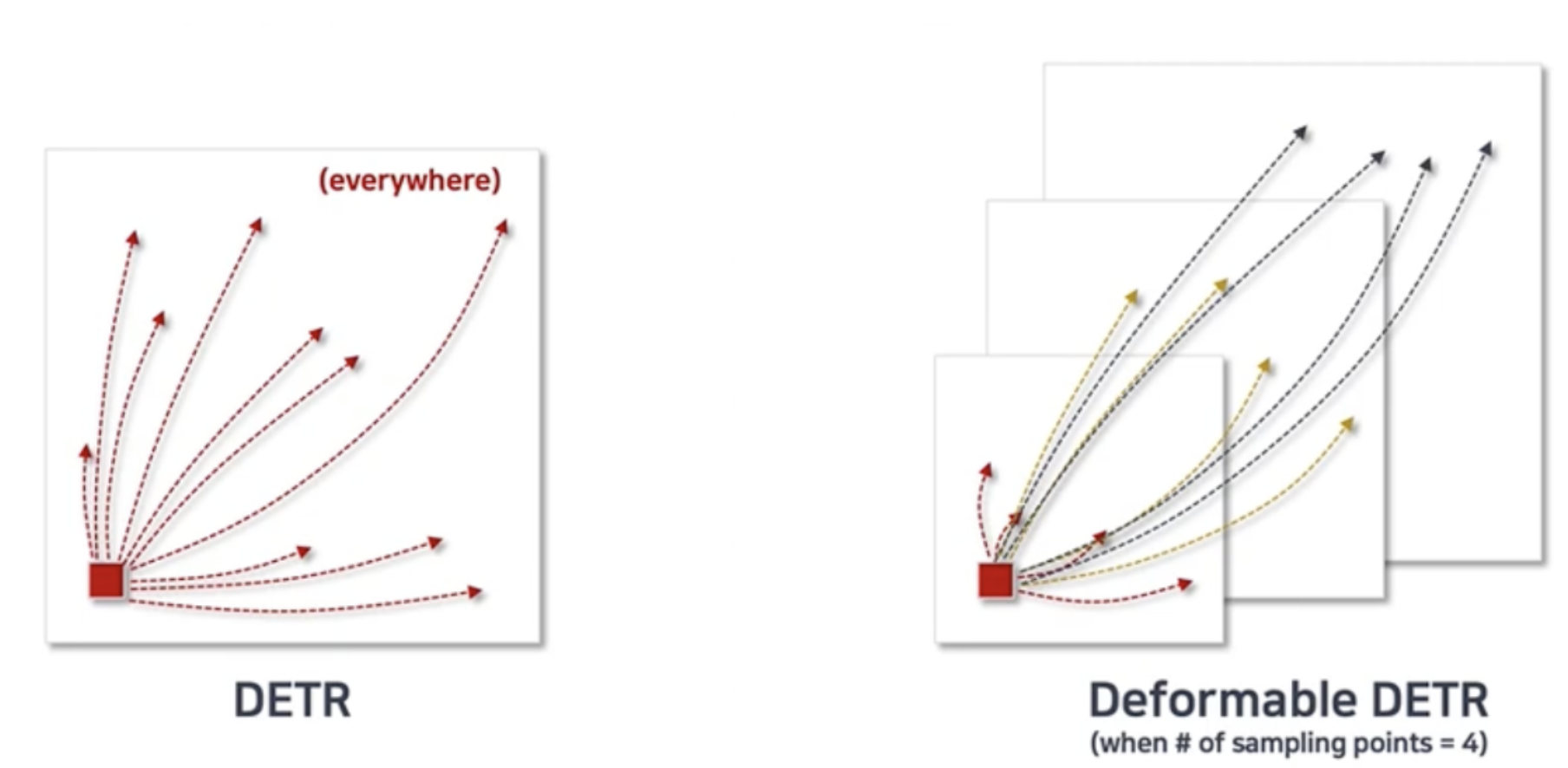
왼쪽이 기존 DETR이고, 오른쪽이 Deformable DETR입니다.
기존 방식은 모든 Pixels에 대한 Query, Key의 Attention 연산을 수행되는데, 결국 학습이 다 이루어지고 나면 Query와 Attention값이 높은 Key들은 결국 아주 극 소수일 것입니다.
이렇게 최종 학습 후에는 소수의 Key들만 Attention 값이 높아 쓸모가 있는데, "처음부터 모든 Key에 대한 Attention값을 구하면 수렴 속도만 오래 걸리고, 계산 복잡도와 메모리도 많이 잡아먹으니 차라리 처음부터 소수의 Key에 대한 Attention 값만 구하자. 근데 이 Key들의 위치는 Deformable Convolution처럼 Offset을 구하는 것" 이 오른쪽 그림입니다.
또한, 현재 Query가 속해있는 Feature map의 해상도에 대해서만 Deformable Attention을 구하는 것이 아니라, 여러 해상도의 Feature map에 대한 Attention을 수행하면, Feature pyramid와 같은 역할을 할 것이고 따라서, 두 번째 제한점인 작은 객체도 잘 Detection 할 것이라고 주장하고 있습니다.
전체적인 개요는 이렇고 이제 세부 구조에 대해 알아보도록 하겠습니다.
Deformable DETR
Deformable DETR의 전체 구조는 아래와 같습니다.
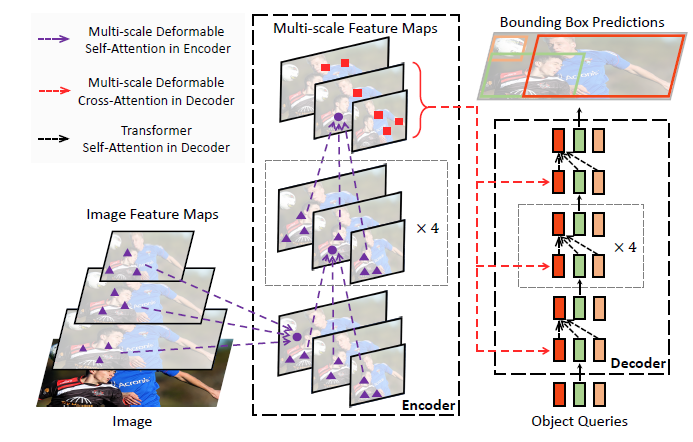
DETR과 동일하게 Transformer로 Encoder-Decoder를 구성하고, 최종적으로 Object Queries가 이분 매칭으로 Object Detection을 수행합니다. 달라진 점이라면 Multi-Scale 구조를 사용한 것과 Deformable Attention을 사용한 것입니다.
Deformable Attention Module(Single-Scale)
이 논문의 핵심인 Deformable Attention을 Single-Scale에서 어떻게 이루어지는지 보면
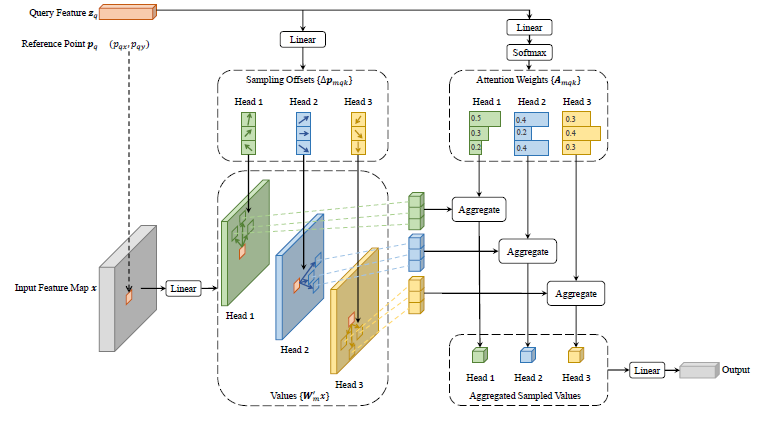
위와 같은 구조가 나옵니다. 이 구조에서 Attention Score를 구하는 절차는 아래와 같습니다.
- Input Feature Map \( x \)의 한 픽셀에 출력 차원이 3MK인 Linear Layer를 적용하여 Query Feature \( z_q \)를 출력하고(M: Multi-Head의 수, K: Keys의 수), 2MK, MK를 각각 분할해서 적용
- 2MK는 Keys에 대한 Offsets(\( \Delta p_{mqk} \))로 활용. 이 Offsets은 정수가 아닌 소수
-> Reference Point \(p_q\) (\( p_{qx}, p_{qy} \))에 이 Offsets을 더하여, Keys의 좌표(x, y)를 구함.
-> 위 그림에서 \(p_q\)는 Query의 x, y 좌표와 동일함 - MK에 K를 기준으로 Softmax를 취한 값이 Attention Weights(\( A_{mqk} \))이고, \( \sum_{k=1}^K A_{mqk} = 1 \)
-> 기존 Transformer에서는 \( A_{mqk} \) Query와 Key의 Dot-Product와 Softmax로 구했지만, 본 논문에서는 단순하게 Linear Layer에 대한 Softmax로 구함
- 2MK는 Keys에 대한 Offsets(\( \Delta p_{mqk} \))로 활용. 이 Offsets은 정수가 아닌 소수
- Input Feature Map \( x \)에 Linear layer를 적용하여 Values(\( W^{'}_m x \))를 출력
위에서 Attention Weight와 Query, Key, Value에 대한 정보가 다 있으니 이제 Attention Score를 구합니다.

위 Values \( W^{'}_m x \)를 소수점 좌표 \( p_q + \Delta p_{mqk} \)를 추출하기 위해 Bilinear Interpolation을 적용합니다. 이후 Attention Weights \( A_{mqk} \)를 곱하고 모든 K에 대한 합을 구하고, 최종 Linear Layer \( W_m \)를 적용시켜 Attention Score를 구합니다.
위 과정은 하나의 Head에 대한 과정이고, 이 모든 과정을 Multi-Head에 대해 구하면 위와 같은 DeformAttn \((z_q, p_z, x) \)의 식이 나옵니다.
Deformable Attention Module(Multi-Scale)
본 논문은 Multi-Scale Feature maps에 대해 Deformable Attention을 진행하였기 때문에, 위 Single-Scale를 Multi-Scale로 확장해 줍니다. 그럼 아래와 같은 식이 나옵니다.

추가된 것이 각 Scale Feature map에서 level인 L만 추가되었습니다. Multi-Scale Feature maps을 \( \left\{ x^l \right\}^L_{l=1} \)라 하면, 각 \( x^l \in \mathbb {R}^{C * H_l * W_l} \)입니다.
그리고 Single-Scale에서는 하나의 Query가 각 Head에서 K개의 샘플링 개수만큼 Attention이 이루어지며, 이로 인해 2MK개의 Offsets와 MK개의 Attention Weight \( A_{mqk} \)를 계산합니다. Multi-Scale에서는 이와 유사하게 하나의 Query가 각 Head에서 K개의 샘플링 개수만큼 Attention을 수행하지만, 여러 Level에서도 동일한 K개의 샘플링 개수만큼 Attention이 이루어지기 때문에 총 2 MLK개의 Offsets과 MLK 개의 Attention Weight \( A_{mqlk} \)를 구합니다.
그리고 각 Level은 서로 다른 해상도를 가지기 때문에, \( \phi_l \)는 해상도에 맞는 정규화라고 보시면 됩니다.
Deformable Transformer Encoder-Decoder
앞서 설명한 과정이 Deformable Transformer Encoder의 Self-Attention에서는 앞서 동일하게 적용되었습니다.
그리고, Deformable Transformer Decoder는 Self-Attention과 Cross-Attention으로 이루어져 있습니다. 먼저, DETR과 동일한 방식으로 N개의 Object Queries에 대한 Embedding을 설정하고, Self-Attention은 Deformable Transformer가 적용된 것이 아니라, N개의 Object Query Embeddings는 차원이 얼마 되지 않기 때문에 Standard Tranformer가 적용되었습니다.
Decoder의 Cross-Attention 부분은 Deformable Transformer Encoder의 출력을 Keys로 N개의 Object Query Embedding을 Queries로 연산을 진행합니다. 여기서는 Keys의 부분이 Multi-Scale Feature maps이기 때문에 연산량이 많아 Deformable Transformer를 적용합니다.
앞에서 설명한 방식은 Deformable Attention 연산을 위해, Reference Points \( p_q \)를 Query의 좌표와 동일한 고정된 좌표에서 Offsets 구하는 방식이었습니다. 하지만, 이 부분의 Reference Points \( p_q \)는 Object Query Embedding에서 Linear Layer를 태우고 Sigmoid를 취해 학습 가능한 좌표를 출력합니다. 이렇게 하는 이유는 \( p_q \)를 디렉트 하게 객체의 위치를 예측하게 학습하게 해서 최적화와 수렴의 가속화를 위해서라고 합니다.
기존 DETR에서는 최종적으로 Decoder의 최종적 출력에 Detection head로 각 쿼리들의 각 쿼리들의 Bounding Box(x, y, w, h)를 구했는데, 이 방식에서는 Detection head에 \( p_q \)의 좌표 정보를 활용하자는 것입니다.

Reference Points를 좌표나 박스에 활용할 때는 Sigmoid를 해주고, 학습이나 연산에 적용할 때는 이 Inverse Sigmoid를 해줍니다. 이렇게 해서 최종 출력되는 BBox의 식은 아래와 같습니다.

성능 향상 기법
본 논문은 위 방법뿐만 아니라 더 성능을 끌어올리기 위해 Iterative Bounding Box Refinement와 Two-Stage Deformable DETR을 추가적인 기법으로 제시하였습니다. 두 방법 다 Reference Points를 (x, y) 좌표가 아닌, (x, y, w, h) 박스 형태로 예측하였습니다.
Iterative Bounding Box Refinement
기존 방법은 Reference Points를 첫 쿼리에서만 Linear layer & Sigmoid로 예측했는데, 이 방법은 모든 Decoder 레이어에서 점진적으로 Reference Points를 예측하고 Refinement 하는 기법입니다.
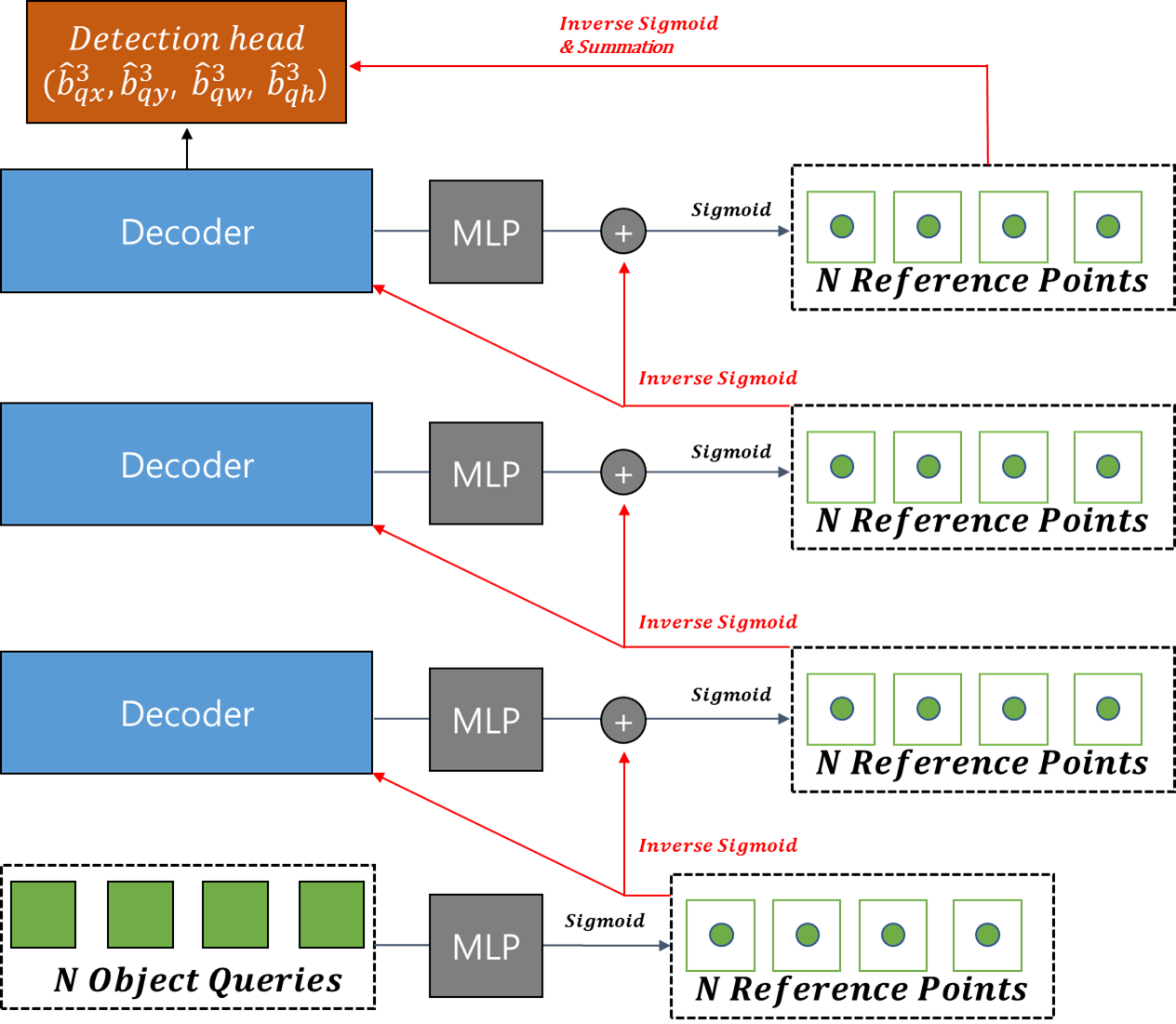
이런 식으로 구성됩니다. 현재 Decoder 레이어에서 Reference Points를 예측할 때 이전 Decoder 레이어의 Reference Points를 활용하는 것입니다.

초기 쿼리에서 Box를 예측할 때 width와 height 값은 0.1로 주었습니다(다른 값들 실험해봤지만 결과는 다 비슷했음).
그리고 여기서 주의할 점은 이 Reference Points의 정보들이 Decoder의 샘플링되는 Keys에도 사용되는데, 이 Keys는 좌표의 정보가 주어져야 합니다. 그러므로, 박스의 정보가 입력으로 주어질 수 없기 때문에, Reference Point의 정보를 (x, y) 좌표로 아래와 같이 변환시킵니다.
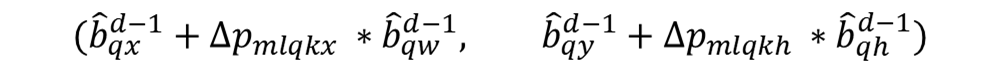
Two-Stage Deformable DETR
성능을 올리기 위해 Two-Stage 방법도 도입하였습니다.
Deforable Transformer Encoder의 마지막 레이어의 출력에 모든 픽셀에 Linear Layer를 통과하여, Detection head를 예측합니다. Box에 대한 Binary Classification과 Offsets( \( \Delta b_{ix}, \Delta b_{iy}, \Delta b_{iw}, \Delta b_{ih}\))을 구합니다. 그리고 사전 정의된 Anchor Box와 연산합니다.

본 논문에서는 s를 0.05로 설정하였습니다. 여기서 Classification의 Score가 높은 N개의 BBox를 추출합니다. 추출한 N개의 BBox는 Decoder에서 Reference Points로 사용되고, 이 N개의 BBox 4개 좌표를 Embedding 할 차원(C)만큼 Position Embedding을 시키고 동일한 차원으로 Linear layer(C, C)를 통과시켜 (N, C) 차원 형태의 Object Query Embeddings을 만듭니다.
여기서 만들어진 N Object Queries와 N Reference Points는 위 Iterative Bounding Box Refinement의 초기 입력 값이고 전술한 것과 동일하게 네트워크를 통과합니다.
이상 Deformable DETR의 포스팅을 마치겠습니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Object Detection' 카테고리의 다른 글
| [논문 리뷰] Denoising DETR(DN-DETR) (0) | 2024.04.04 |
|---|---|
| [논문 리뷰] Conditional DETR (0) | 2024.03.29 |
| [논문리뷰] DETR: End-to-End Object Detection with Transformer (0) | 2024.03.22 |
| [논문리뷰] Cascade R-CNN (0) | 2024.03.18 |
| [논문리뷰] Exploring Plain Vision Transformer Backbones for Object Detection (0) | 2024.01.16 |




댓글