들어가며
이 글은 DETR에 대한 사전지식이 있다는 가정하에 작성되었습니다.
[논문리뷰] DETR: End-to-End Object Detection with Transformer
들어가며 본 논문은 Object Detection과 Transformer의 사전 지식이 있다는 가정하에 작성되었습니다. 오늘 리뷰할 논문은 DETR입니다. 이 논문은 Object Detection에 Transformer를 적용시킨 최초의 논문입니다.
lcyking.tistory.com
기존 DETR은 Transformer를 Object Detection에 적용하여 많은 Hand-Crafted Module(NMS, Anchor) 등을 없앴지만, 수렴하는데 500 Epoch정도 학습해야 하는 낮은 수렴속도를 가졌습니다.
본 논문은 이 문제점을 개선하여, 수렴속도를 높인 논문입니다. 그럼 어떤 방법으로 이 문제점을 개선했냐 하면 평소에 Decoder의 Cross-Attnetion 부분에서 사용되는 Position Embedding을 약간 변형시키고, Query Embedding에 잘 주입하였습니다.
그럼 왜 이 Position Embedding에 대한 필요성이 제기됐냐 하면 아래 그림을 보면 알 수 있습니다.

일단 행은 순서대로 Conditional DETR(50Epoch), DETR(50 Epoch), DETR(500 Epoch)로 학습된 것이고, 열은 Multi-Head Attention Weight의 각각의 Head가 나타내는 서로 다른 영역입니다(노란색 광선 같은 것). 각각 학습된 모델의 Head 들이 Object Bounding Box(BBox)에 잘 위치하는지 확인하는 것이죠.
먼저, 2행부터 보면 역시 수렴에 오래 걸리는 DETR이 50 Epoch 정도만 학습시키니, 각 Head들이 BBox 경계선에 대해 잘 학습하지 못했네요. 반면 3행을 보시면 학습이 많이 된 DETR의 Head를 볼 수 있습니다. 여기서는 각 Head들이 BBox 주변에 대해 잘 학습이 이루어졌습니다.
"이렇게 학습이 500Epoch나 돌아하는 이유가 뭘까?" 하다가 그 이유가 기존 DETR Decoder의 Cross-Attentiond이 모든 학습이 Content Embedding에만 심하게 의존한다는 것입니다. 여기서 Content Embedding은 기존 DETR의 객체의 쿼리들의 임베딩이 Encoder와 Cross-Attention으로 학습이 이루어지면서, 이미지와 관련된 Features를 학습해 나가는 것을 의미합니다.
이 Content Embedding이 학습이 적게 돌면, BBox의 위치에 대한 정보에 대한 학습이 이루어지지 않아 위와 같은 현상이 발생한다고 하죠. 아울러 DETR에서 Position Embedding을 빼면 성능이 크게 저하한다는 증거로 이 객체에 대한 공간 정보에 대한 필요성이 시급하다고 제시하고 있습니다.
그래서 이 "객체 공간을 학습할 수 있는 Embdding을 만들어서, 이 Content Embedding과 따로 학습시키고, Decoder Layer 중간중간에 적절하게 주입해 주면 Content Embedding의 짐을 덜어줄 수 있겠다"라는 생각으로 Spatial Embedding을 도입하였습니다.
이제 이 Spatial Embedding이 어떻게 구성되고, 어떻게 주입되는지 자세히 살펴보겠습니다.
Conditional DETR
먼저 기존 DETR Decoder에서 Cross-Attention이 동작하는 방식을 보면 아래와 같습니다.

여기서 c가 Content Embedding이고, p가 Position(Spatial) Embedding입니다. 이렇게 단순하게 Summation 하는 방식으로 Content Embedding을 구성하여, Content Embedding에 Position 정보가 내장되고 한 번에 학습하니 당연히 수렴에 오래 걸렸다고 합니다. 본 논문은 아래와 같이 심플하게 Cross-Attention을 연산합니다.

이 식이 가능하게 된 이유는 Content query \( c_q \)와 Spatial query \( p_q \)를 summation 하는 것이 아닌 concatenation 해주고, 마찬가지로 Content key \( c_k \)와 Spatial key \( p_k \)도 concatenation 해주어 Content와 Spatial의 독립적인 연산이 가능하게 되었습니다.
위 식에서 \( c_k \)와 \( p_k \)는 Transformer Encoder의 값, \( c_q \)도 Self-Attention의 출력으로 아는 값이니 Spatial query \( p_q \)만 어떻게 구성되는지 알아보면 될 것 같습니다.
Spatial Query
Spatial Query에 대한 이야기를 하기 전에, 기존 방식에서 BBox를 예측하는 수식을 보면,

Transformer Decoder를 통과한 Content Embedding \( f \)에 최종적으로 Feed Forward Network(FFN)를 통과시켜 Offsets (\( \Delta x, \Delta y, \Delta w, \Delta h \))를 구하고 Reference Point (\(s(x, y) 0(w) 0(h) \))에 이 값을 더한 뒤 Sigmoid를 취해 BBox의 x, y, width, height를 구합니다.
여담으로 DETR은 \( s \)가 (0, 0)으로 고정되어 이 값이 Sigmoid를 취하면 (0.5, 0.5)가 되어 Reference Points가 중앙이고 이에 따른 Offset을 구하고, Deformable DETR은 \(s \)가 고정된 값이 아닌 학습시킵니다.
여하튼 중요한 건 이게 아니라, Spatial Query를 구성하기 위한 정보가 Reference Points(x, y)와 이동량(Offset)이 필요하다는 것입니다. 이동량에 대한 정보는 Content Embedding \( f \)가 가지고 있고, Reference Point \(s \)에 대한 정보는 Object Query로부터 가져옵니다.
Referece Point \( s \)는 아래와 같이 구합니다.

- FFN에 Object Query를 입력하여 출력이 2차원인 비정규화된 공간의 Reference Point \( s \)를 구하고, Sigmoid를 취해 [0, 1]의 값으로 정규화
-> FFN: Linear Layer + ReLU + Linear Layer - 학습에 사용될 Position Embedding으로 변환하기 위해, 2차원의 \( s \)를 256차원의 sinusoidal positional embedding 공간 투영
다음, 이동량 \( T \)도 마찬가지로 FFN으로 구하는데, Content Embedding \( f \)를 입력으로 받습니다.

최종적으로 Spatial Query \( p_q \)는 Reference Point Embedding \( p_s \)와 이동량 \(T \)에 대한 곱으로 구합니다.

여기서 \( \lambda_q \)는 \( T \)의 대각행렬인데, 이렇게 하니 성능이 잘 나왔다고 합니다(근데 뭐 전체 다 곱해도 별 차이 없어서, 코드에는 전체 Matrix를 다 곱했네요). 이렇게 해서 최종 네트워크는 아래와 같이 구성됩니다.
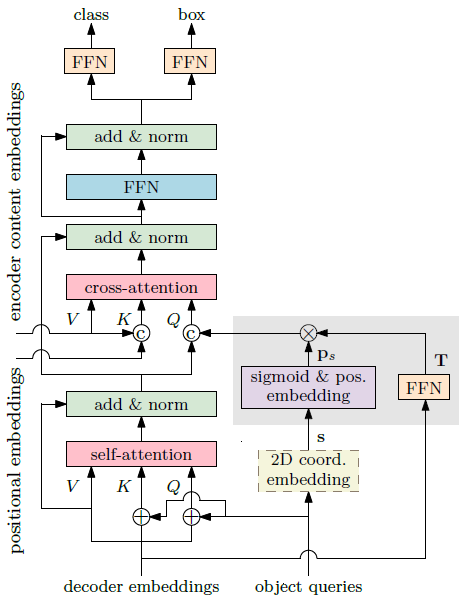
학습 과정에서 첫 Decoder layer에서는 \( T \)를 곱하지 않고, \( p_s\)만 사용하였습니다. 이유는 말해주지 않네요... 아마 성능이 잘 나오니 그랬겠죠.
결론
이렇게 학습된 Conditional DETR이 각 Head에서 객체에 대한 정보를 잘 학습했는지 확인해 보면 아래와 같습니다.

첫 번째 행은 Spatial Attention, 두 번째 행은 Content Attention, 세 번째 행은 둘 다 결합한 것입니다. 각자에 따라 학습이 잘 된 것을 확인할 수 있습니다.
이상 Conditional DETR의 포스팅을 마치겠습니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Object Detection' 카테고리의 다른 글
| [논문리뷰] DAB-DETR (0) | 2024.04.07 |
|---|---|
| [논문 리뷰] Denoising DETR(DN-DETR) (0) | 2024.04.04 |
| [논문 리뷰] Deformable DETR (0) | 2024.03.28 |
| [논문리뷰] DETR: End-to-End Object Detection with Transformer (0) | 2024.03.22 |
| [논문리뷰] Cascade R-CNN (0) | 2024.03.18 |




댓글