Datasets
tf.keras의 내장되어있는 datasets인 fashion_mnist로 예를 들겠다.
import numpy as np
import pandas as pd
from tensorflow.keras.datasets import fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
print('train dataset shape:', train_images.shape, train_labels.shape)
print('test dataset shape:', test_images.shape, test_labels.shape)
import matplotlib.pyplot as plt
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
figure, axs = plt.subplots(figsize=(22, 6), nrows=1, ncols=8)
for i in range(8):
axs[i].imshow(train_images[i], cmap='gray')
axs[i].set_title(class_names[train_labels[i]])
위의 그림을 보면 train dataset의 shape가(60000, 28, 28)인 것을 확인할 수 있다. 이미지 배열에서 흑백은 2차원(x, x)으로, 컬러는 3차원(x, x, 3)으로 0~255 값으로 채워져 있다. 위의 그림은 흑백이므로 28 x 28의 흑백사진이 60000개 있다는 의미이다. 딥러닝의 모델은 0~1 사이의 값으로 변환해야 모델이 더 좋게 나오므로 아래와 같이 전처리를 해준다.
def get_preprocessed_data(images, labels):
images = np.array(images/255.0, dtype=np.float32)
labels = np.array(labels, dtype=np.float32)
return images, labels
train_images, train_labels = get_preprocessed_data(train_images, train_labels)
test_images, test_labels = get_preprocessed_data(test_images, test_labels)tf.keras는 자동으로 float32 형식으로 변환해 주지만 명시적으로 타입을 변경해주었다.
Sequantial
딥러닝의 모델은 Sequantial기반과 Functional Api기반이 있는데 먼저 Sequantial의 코드를 보겠다.
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import Sequential
INPUT_SIZE = 28
model = Sequential([
Flatten(input_shape=(INPUT_SIZE, INPUT_SIZE)),
Dense(100, activation='relu'),
Dense(30, activation='relu'),
Dense(10, activation='softmax')
])
model.summary()
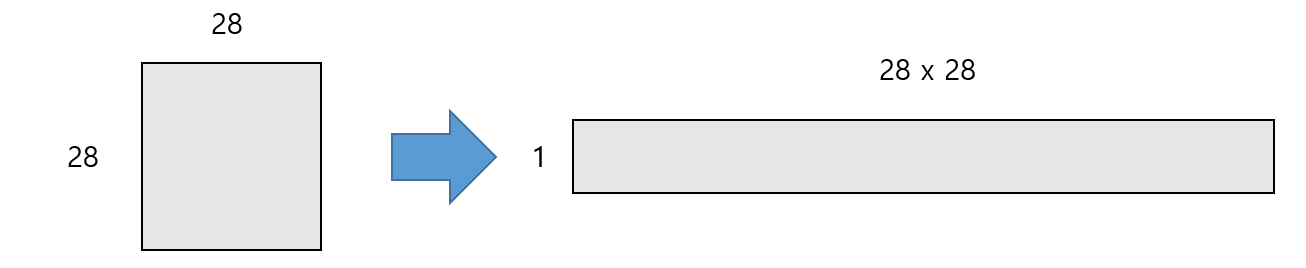
위의 첫번째 Flatten의 input_shape를 살펴보면 2차원 형식으로 되어있다. 이것은 데이터가 28 x 28 인 2차원 형식이기 때문이다. 만약 컬러면 input_shape=(INPUT_SIZE, INPUT_SIZE, 3)으로 입력이 되어야 한다. flatten의 의미는 다차원 데이터를 1차원으로 변경하는 것이다. Sequential 모델은 input데이터가 들어갈 자리를 input_shape로 명시해주어야 한다.
dense(Dense)는 100개의 뉴런과 relu로 구성된 Hidden Layer, dense_1(Dense)는 30개의 뉴런과 relu, 마지막 dense_2(Dense)는 10개의 뉴런과 softmax로 분류된다. Param은 가중치의 개수로 784 x 100 + 100(절편), 100 x 30 + 30, 30 * 10 + 10으로 구성된다.

다음 모델의 학습의 optimizer를 Adam으로 설정하고 학습률은 0.001(default), loss는 categorical_crossentropy, 평가는 accuracy로 할 것이다. 다만 categorical_crossentropy를 해줄 때에는 label을 원핫 인코딩을 무조건 시켜주어야 한다.
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
train_oh_labels = to_categorical(train_labels)
test_oh_labels = to_categorical(test_labels)
print(train_oh_labels.shape, test_oh_labels.shape)
이제 모델을 학습시킬 건데 배치 사이즈는 64로 반복수는 20으로 설정할 것이다. 배치 사이즈를 너무 적게 하면 시간이 오래 걸리고 너무 크게 하면 메모리가 터질 수 있으므로 적절히 조절하자.
result = model.fit(x=train_images, y=train_oh_labels, batch_size=64, epochs=20, verbose=1)

학습 데이터로 평가를 하였기 때문에 과적합이 일어날 수밖에 없다. 결과는 result안에 history에 loss, accuray가 각각 있다. epoch 수만큼 저장되어있음을 알 수 있다.
print(len(result.history['loss']))
print(len(result.history['accuracy']))
학습 데이터로 평가를 하였기 때문에 이 모델이 다른 데이터가 들어왔을 때 좋은 모델인지 알 수가 없다. 그러므로 검증 데이터를 이용하여 모델을 다시 평가한다. 먼저 테스트 데이터의 15%를 검증 데이터로 분리한다. 마찬가지로 categorical_crossentropy로 loss를 정할 것이기 때문에 원핫 인코딩을 시켜준다.
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
tr_images, val_images, tr_labels, val_labels = train_test_split(train_images, train_labels, test_size=0.15, random_state=2021)
tr_oh_labels = to_categorical(tr_labels)
val_oh_labels = to_categorical(val_labels)
print('train, validation shape:', tr_images.shape, tr_labels.shape, val_images.shape, val_labels.shape)
print('after ohe shape:', tr_oh_labels.shape, val_oh_labels.shape)
학습 데이터를 분리시켜 label을 원핫인코딩까지 해 주었으므로 모델을 학습시키면서 검증을 한다. validation_data는 넣어주지 않아도 되지만 명시적으로 넣어주었다.
result = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, validation_data=(val_images, val_oh_labels),
epochs=20, verbose=1)

위의 검증 결과에 추가로 val_loss, val_accuracy가 생겼다. validation data의 loss와 accuracy이다. 위와 같은 방식으로 history안에 val_loss, val_acccuray로 값에 접근할 수 있다.
Functional API
from tensorflow.keras.layers import Input, Flatten, Dense
from tensorflow.keras.models import Model
INPUT_SIZE = 28
input = Input(shape=(INPUT_SIZE, INPUT_SIZE))
a = Flatten()(input)
b = Dense(100, activation='relu')(a)
c = Dense(30, activation='relu')(b)
output = Dense(10, activation='softmax')(c)
model = Model(inputs=input, outputs=output)
model.summary()
Functional API는 Sequential처럼 하나의 Sequential에 Layer들을 쭉 나열하는 형식이 아니라 Input과 Ouput형식을 Model에 넣어 모델을 만든다. 현재 Layer에 input이 들어오면 내부적으로 call이라는 메서드를 호출해 그 결과를 반환한다.

Flatten에 대한 output은 a이고, 다음 Dense의 input으로는 a가 들어간다. 이 Dense의 output은 b이고 다음 Dense에 input으로 들어간다. 이런식으로 내부적으로 call이라는 메서드를 호출하여 output을 반환한다. keras에서는 Sequential을 잘 안 쓰고 Functional API를 자주 사용한다.
Callback
모델이 학습하는중에 모델의 성능이 일정 횟수 내에 더 이상 좋아지지 않으면 강제 종료하거나, Learning Rate를 조정하여 모델의 성능을 늘리거나, 중간중간 모델을 저장할 때 사용한다.
ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
- filepath: epoch값과 logs의 키로 채워진 이름 형식 옵션을 가질 수 있음. 예를 들면 weights.{epoch:02d}-{val_loss:.3f}.hdf5면, 파일 이름에 epoch번호와 검증 손실을 넣어 저장
- monitor: 모니터할 지표(loss 또는 평가 지표, 단 overfitting 된 학습 데이터를 넣는 것이 아니라 검증 데이터를 넣는 것)
- save_best_only: 가장 좋은 성능을 나타내는 모델만 저장
- save_weights_only: 가중치만 저장할지 여부(권장)
- mode: monitor지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 자동으로 유추
- period: 몇 번에 한 번씩 작동할지
from tensorflow.keras.callbacks import ModelCheckpoint
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
mcp_cb = ModelCheckpoint(filepath='weights.{epoch:02d}-{val_loss:.2f}.hdf5', monitor='val_loss',
save_best_only=True, save_weights_only=True, mode='min', period=3, verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=10, validation_data=(val_images, val_oh_labels),
callbacks=[mcp_cb])

monitor는 val_loss로 주었고 loss는 줄어들수록 좋은 모델이므로 mode='min'으로 주었다. callback함수는 fit에 callbacks파라미터로 주면 된다. 위의 지표를 보면 3, 6번째는 성능이 좋아졌으므로 저장을 하였고, 9번째는 성능이 향상되지 않았으므로 저장하지 않는다.
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', min_delta=0.0001, cooldown=0, min_lr=0)
- 특정 epochs 동안 성능 개선이 되지 않을 시 Learning Rate를 동적으로 감소시킨다
- monitor: 모니터 할 지표(loss 또는 평가 지표)
- factor: 학습 속도를 줄일 인수
- patience: monitor 할 epochs 수
- mode: monitor지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 자동으로 유추
from tensorflow.keras.callbacks import ReduceLROnPlateau
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=3, mode='min', verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels),
callbacks=[rlr_cb])
자세히 보면 epoch가 9부터 10, 11, 12 val_loss가 늘어나 성능이 저하된 것을 볼 수 있다. patience를 3으로 설정해주고 factor를 0.3으로 설정해 주었기 때문에 3회 성능 향상이 없어 학습률을 0.3 낮춘것을 볼수있다.
EarlyStopping(monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False)
- 특정 epochs 동안 성능이 개선되지 않으면 학습을 조기 중단시킨다.
- monitor: 모니터 할 지표
- patience: monitor 할 epochs 수
- monitor지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 자동으로 유추
from tensorflow.keras.callbacks import EarlyStopping
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
ely_cb = EarlyStopping(monitor='val_loss', patience=3, mode='min', verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels),
callbacks=[ely_cb])

3회 동안 성능이 개선되지 않아 종료된 것을 볼 수 있다.
'컴퓨터비전' 카테고리의 다른 글
| [딥러닝] Object Detection이란? (0) | 2022.03.22 |
|---|---|
| [딥러닝] 가중치 초기화(Weight Initialization) (0) | 2022.03.13 |
| [딥러닝] 딥러닝의 Optimizer (0) | 2022.03.08 |
| [딥러닝] 딥러닝의 손실 함수 (0) | 2022.03.08 |
| [딥러닝] 활성화 함수( Activation Function) (0) | 2022.03.08 |




댓글