
Localizaion : 이미지 내의 Object의 위치를 Bounding Box로 찾습니다.
Detection : 이미지 내의 두 개 이상의 Object의 위치를 Bounding Box로 찾고, Bounding Box내의 오브젝트를 분류합니다.
두 개 두 개 다 Box의 좌표값과 그 Box의 Classification 두 개의 문제가 합쳐져 있어 일반 이미지 분류보다 더 복잡한 문제가 있습니다. Detection은 두 개 이상의 Object를 이미지의 임의 위치에서 찾아야 하므로 상대적으로 더 어려운 문제에 봉착하게 됩니다.
문제
- Bounding Box 좌표의 Regression과 그것이 무엇인가를 판별하는 Classification을 동시에 진행해야 합니다.
- 다양한 크기의 유형의 박스들을 Detect해야 합니다.
- 실시간 영상 기반에서는 Detect 시간도 신경써야합니다.
- 데이터 세트가 부족합니다. 이미지를 구하기도 힘든뿐더러, 이미지 안에 box들을 일일이 만들어 주어야 하기 때문에 생성이 매우 까다롭습니다.
1-Stage Detector VS 2-Stage Detector
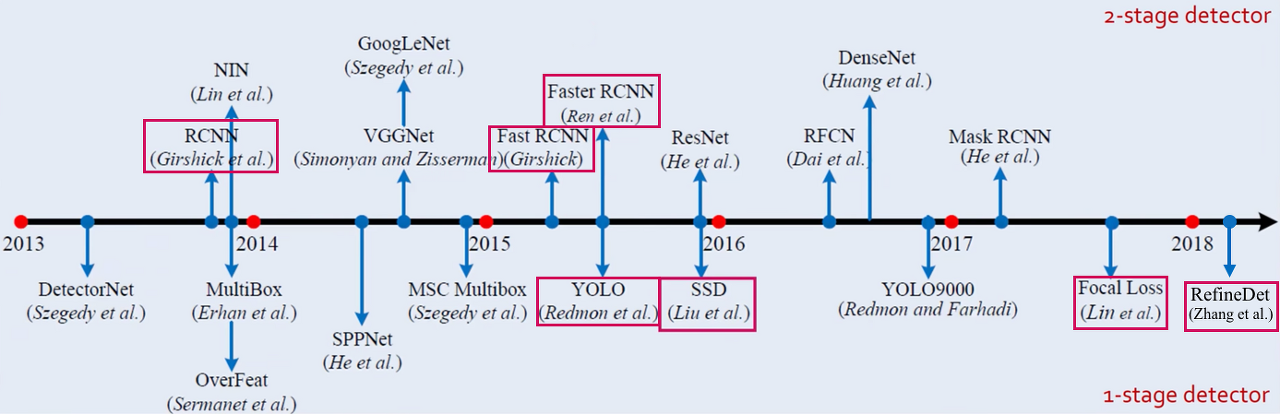
화살표 아래의 영역이 1-Stage 영역이고, 위의 영역이 2-Stage 영역입니다. 앞서 말했듯이 Object Detection은 Localization 문제와, 그 물체가 무엇인지 식별하는 Classification 두 문제 둘 다 행하여야 하는 것인데
- 1-Stage Detector는 Localization, Classification 두 문제를 동시에 행하는 방법이고
- 2-Stage Detector는 이 두 문제를 순차적으로 행하는 방법입니다.
어느 것이 더 좋다보다, 1-Stage는 두 문제를 동시에 하는 만큼 빠르지만 정확도가 낮고, 2-Stage는 반대로 느리지만 정확도는 좋습니다.
영역 추정(Region Proposal)
Sliding Window
영역 추정의 초기 방식으로는 Sliding Window 방식이 있습니다. Window를 왼쪽 상단에서부터 오른쪽 하단으로 이동시키면서, 다양한 크기의 박스와 이미지 크기 조절 등으로 Object를 Detection 하는 방식입니다.
하지만, 오브젝트 없는 영역도 무조건 슬라이딩하여야 하며, 그에 따른 수행 시간도 오래 걸리며 검출 성능도 상대적으로 낮습니다. 그래도 Region Proposal 기법의 등장의 밑거름이 되었습니다.

위의 그림은 다양한 형태의 Window를 각각 Sliding 시키는 방식입니다.

위의 그림은 이미지의 크기를 변경하면서 사용하는 방식입니다.
Selective Search
Region Proposal의 대표적인 방법으로, 빠른 Detection속도와 높은 예측 성능을 동시에 만족하는 알고리즘입니다.
컬러, 무늬, 크기, 형태에 따라 유사한 Region을 계층적으로 그루핑 하여 계산합니다.
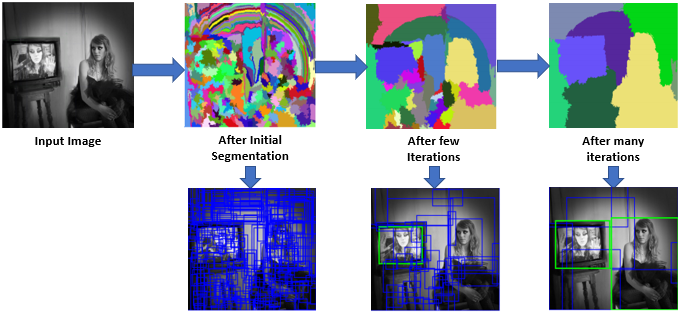
- 개별 Segment 된 모든 부분들을 Bounding box로 만들어서 Region Proposal 리스트로 추가합니다.
- 컬러, 무늬, 크기, 형태에 따라 유사도가 비슷한 Segment들을 그루핑 합니다.
- 1, 2번 과정을 계속 반복하면서 Region Proposal을 수행합니다.
평가
Intersection Over Union(IOU)
모델이 예측한 결과와 실측(Ground Truth) Box가 얼마나 정확하게 겹치는가를 나타내는 지표

NMS(Non Max Suppression)

NMS는 Detected 된 Object의 Bounding box 중에 비슷한 위치에 있는 box를 제거하고 가장 적합한 box를 선택하는 기법입니다.
- Detected 된 bounding box별로 특정 Confidence threshold 이하 bounding box를 먼저 제거합니다.
- 가장 높은 confidence score를 가진 box 순으로 내림차순 정렬합니다.
- 높은 confidence score를 가진 box와 겹치는 다른 box들의 IOU를 조사하여 threshold이상인 box를 모두 제거합니다.
Confidence score가 높을수록, IOU Threshold가 낮을수록 많은 Box가 제거됩니다.

mAP(mean Average Precision)
Object가 Detected 된 재현율(Recall)의 변화에 따른 정밀도(Precision)의 값을 평균한 수치입니다.
정밀도와 재현율은 주로 이진 분류에서 사용되는 성능 지표입니다.
- 정밀도는 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율입니다.
- 재현율은 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 말합니다.
또한 예측이 성공하였다 하더라도 IOU값이 Threshold값을 넘지 못하면 실패한 것으로 간주합니다.

- TP에 있는 그림은 예측도 bird로 잘했고 IOU값도 임계값을 넘었습니다.
- FP-1 그림은 Bounding Box는 맞았지만, cat으로 잘못 예측하였습니다.
- FP-2 그림은 IOU값이 넘지 못했습니다.
- FP-3 그림은 아예 다른 곳을 예측하였습니다.
- FN은 아예 예측을 하지 않았습니다.

왼쪽 그림에서는 예측해야 될 것이 3개이고, 예측한 것은 2개이고, 제대로 예측한 것은 2개입니다.
오른쪽 그림에서는 예측해야 될 것이 3개이고, 예측한 것은 5개이고, 제대로 예측한 것은 2개입니다.

위의 구조를 생각하면 재현율이 더 중요한 경우가 있을 것이고, 정밀도가 더 중요한 경우가 있을 것입니다.
- 재현율이 더 중요한 경우는 사기전화인데, 사기전화가 아니라고 예측을 하면 안심하고 받아서 모든 정보를 빼줄 것입니다.
- 정밀도가 더 중요한 경우는 중요한 전화인데, 사기전화라고 예측하면 이 중요한 전화를 못 받아서 불이익이 생길 것입니다.
재현율이나 정밀도 한쪽만 치우친다고 해서 좋은 모델이 절대 아닙니다.
- 확실한 데이터 한 개를 잡아서 예측하고 나머지는 예측하지 않으면 정밀도 = 1 / (1 + 0) = 1입니다, 반면에 재현율은 예측하지 않은 데이터만큼 줄어들겠죠.
- 반대로 모든 데이터를 TP로 예측하면 FN은 0이 되니까 재현율 = x / (x+0) = 1입니다. 나머지 잘못 예측한 만큼 정밀도는 줄어들겠죠.
위와 같은 극단적인 경우가 있을 수 도 있기 때문에 mAP가 필요한 것입니다.
mAP는 여러 오브젝트들의 AP를 평균한 값입니다. 그럼 mAP이전에 AP를 구하는 방법을 알아보겠습니다.
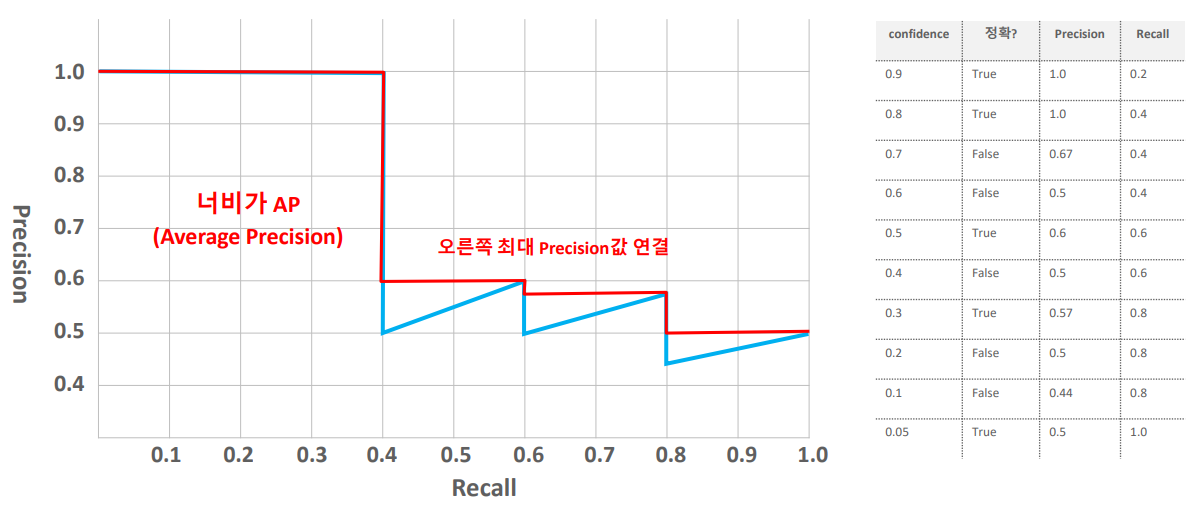
AP는 Precision-Recall 그래프의 아래 면적을 의미합니다. 이게 무슨 말이냐면 x축에는 Recall, y축에는 Precision을 두어 생기는 그래프 아래 면적을 구한다는 의미입니다.

위 그림을 보면 Threshold의 변화율에 따른 Recall과 Precision의 변화입니다.
Threshold가 낮을수록 Recall이 증가, 높을수록 Precision이 증가합니다.
그럼 Threshold를 변화시키면서 Recall변화에 따른 Precision도 구할 수도 있을 것 같습니다.


'컴퓨터비전' 카테고리의 다른 글
| [딥러닝] SPPNet(Spatial Pyramid Pooling Network) 논문 리뷰 (0) | 2022.03.23 |
|---|---|
| [딥러닝] R-CNN 논문 리뷰 (0) | 2022.03.23 |
| [딥러닝] 가중치 초기화(Weight Initialization) (0) | 2022.03.13 |
| [딥러닝] 딥러닝의 모델 (0) | 2022.03.10 |
| [딥러닝] 딥러닝의 Optimizer (0) | 2022.03.08 |




댓글