참조
[논문리뷰] DETR: End-to-End Object Detection with Transformer
들어가며 본 논문은 Object Detection과 Transformer의 사전 지식이 있다는 가정하에 작성되었습니다. 오늘 리뷰할 논문은 DETR입니다. 이 논문은 Object Detection에 Transformer를 적용시킨 최초의 논문입니다.
lcyking.tistory.com
https://lcyking.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-MaskFormer
들어가며
본 글은 DETR과 MaskFormer에 대한 사전 지식이 있다는 가정 하에 작성되었습니다.
이 논문은 MaskFormer의 후속 모델입니다. 기존 MaskFormer는 Instance Segmentation, Semantic Segmentation, Panoptic Segmentation 세 가지 작업을 하나의 모델로 통합한 모델입니다.
MaskFormer가 세 가지 작업에서 각각 독립적으로 연구되어야 하는 노력을, 하나의 모델로 통합하며 많은 각광을 받고 있었습니다. 하지만, 성능 면에서는 모든 작업에서 뛰어나지는 못했습니다. 아울러 DETR 베이스로 설계된 모델이므로 수렴에도 300 Epoch 정도의 긴 시간을 가지는 제한점이 존재하였지요.
따라서, 본 논문은 위와 같은 제한 사항을 개선하는 Mask2 Former를 제안하였습니다. 그 결과로 세 가지 작업 모두에서 가장 우월한 성능을 기록하였습니다.
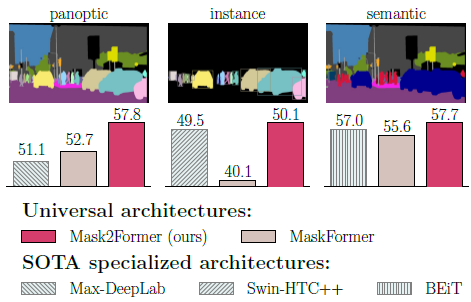
이 논문이 제안하는 기술은 크게 3가지입니다.
- Masked Attention: 기존 Attention과 같이 모든 픽셀에 대해 연산하는 것이 아니라, 특정 의미 있는 영역에만 부분적으로 연산하여 수렴의 가속
- Multi-Scale 구조: 고해상도 피처를 활용하여 작은 객체에 대한 높은 성능
- 최적화 향상: Self, Cross-Attention의 위치 변화, 쿼리 피처에 대한 학습, 드롭아웃 제거
제 생각엔 위에서 가장 주목할 점은 Masked Attention이 아닌가 싶습니다. 그럼 이 세부 구조가 어떻게 동작하는지 살펴보겠습니다.
Mask2 Former
기본적인 구조는 MaskFormer와 동일하게 Backbone, Pixel Decoder, Transformer Decoder로 구성되었고, 내부 구조의 약간의 변형만이 이루어졌습니다.

Backbone & Pixel Decoder
먼저 백본은 ResNet을 사용하였고, 해상도를 복원하는 Pixel Decoder는 multi-scale Deformable Attention Transformer(MSDeformAttn)를 사용하였습니다.
위 MSDeformAttn이 동작하는 방식은 ResNet의 multi-scale(1/8, 1/16, 1/32)의 Feature map들을 1차원 형태로 결합하여 전체 해상도에 대한 Deformable Self-Attention이 이루어지고, 다시 1/8, 1/16, 1/32 Scale의 feature map으로 복원하는 방식입니다. 그리고, 기존 MSDeformAttn과 같이 Position embedding \( e_{pos} \in \mathbb {R}^{H_lW_l * C} \)과 Scale-Level embedding \( e_{lvl} \in \mathbb {R}^{1 * C} \)이 포함됩니다. \( e_{lvl} \)는 C채널이 현재 레벨의 해상도만큼 반복되어 \( e_{lvl} \in \mathbb {R}^{(H_lW_l) * C} \)를 생성하여 Level Position으로 입력됩니다.
아울러 마지막 1/4 Scale의 Feature map은 단순하게 1/8를 선형 보간하여 생성하여, 그림과 같이 총 4개의 해상도(보라색)를 가지는 Feature map들이 형성됩니다.
Transformer Decoder
앞서 설명했듯이 Transformer Decoder의 쿼리들은, Pixel Decoder의 Feature map과 Cross-Attention 연산을 할 때, 부분적으로 연산을 진행한다고 하였습니다. 이러기 위해서 가설을 세웁니다.
이 네트워크의 목적은 쿼리가 각 객체에 대한 영역을 학습하는 것입니다. 다시 말해, 객체에 대한 지역적인 부분을 학습하는 것인데 기존 Transformer와 같이 전역적인 연산은 지역적인 부분을 학습하기에 수렴속도가 너무 느리기 때문에, "처음부터 지역적인 부분에 대한 연산만 진행하면 수렴속도는 물론 성능 또한 잘 나오지 않을까"라는 것입니다.
이 가설은 수렴 속도와 성능이 잘 나오면 증명이 되는 것이겠죠. 그럼 이 지역적인 부분에 대한 Attention 연산은 어떻게 하냐? 본 논문에서는 Masked Attention을 제안하였습니다.
- Masked Attention
Masked Attention은 이름 그대로 마스크 된 영역에만 Attention을 하겠다는 것입니다. 설명의 이해를 돕기 위해, 기존 Transformer에서 쿼리와 Feautre map 간에 Cross-Attention이 어떻게 동작하는지 보면 아래와 같습니다.
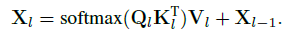
여기서 \( l \)은 Pixel Decoder의 각 Layer 인덱스이고, \( X_l \in \mathbb {R}^{N*C} \)는 Cross-Attention 연산 후 결과입니다. 그렇다면 \(X_0 \)는 가장 초기의 객체에 대한 쿼리가 될 것이고, \( K_l, V_l \in \mathbb {R}^{H_lW_l * C} \)는 Feature map이 됩니다.
위에서 모든 Term은 유지하고, Attention mask \( \mathcal {M} \)만 추가한다면 아래와 같이 Masked Attention입니다.

그렇다면, 이제 \( \mathcal {M} \)만 구하면 되는데, 아래와 같은 과정으로 구해집니다.
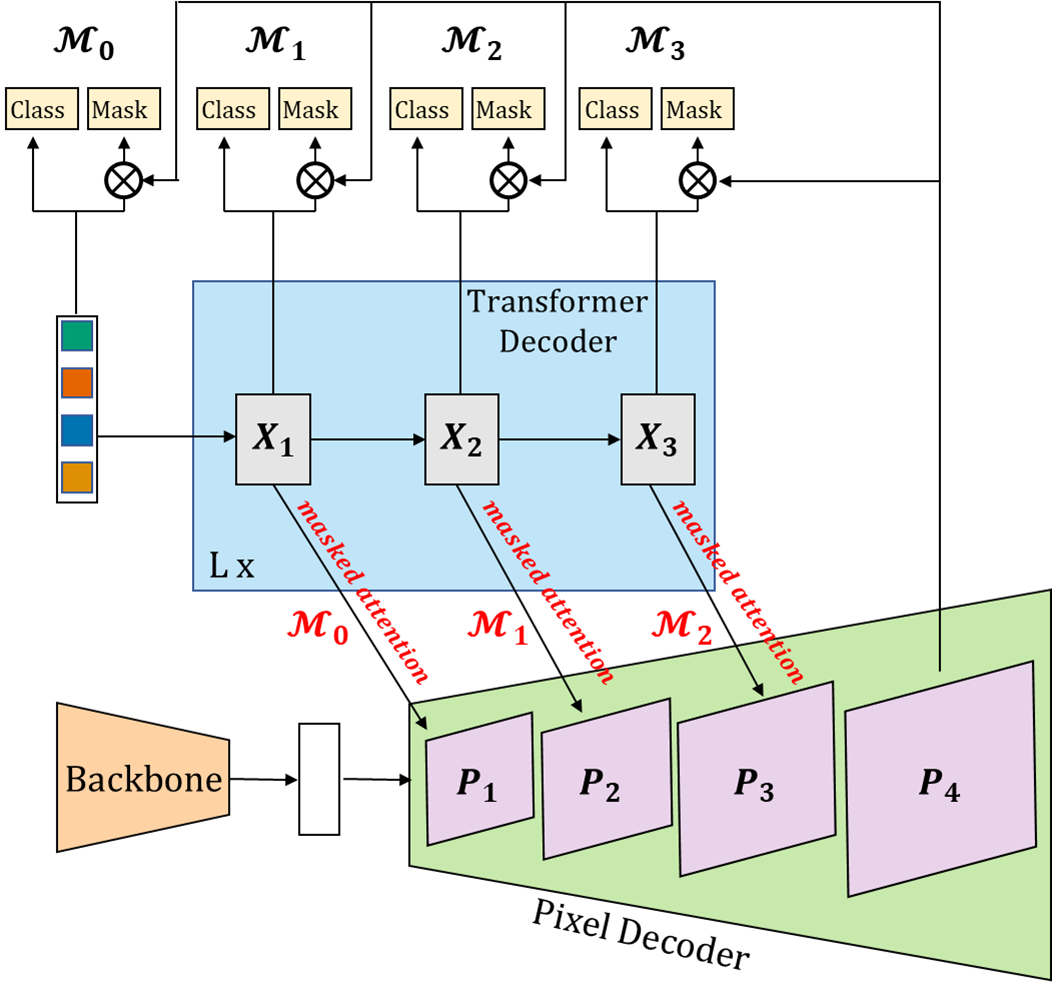
먼저, Pixel Decoder 1/4 해상도의 Feature map과 각각의 Transformer Decoder의 출력 쿼리들이 채널을 기준으로 행렬곱을 하여 Instance Segmentation과 같이 Mask \( \mathcal {M}_l \in \mathbb {R}^{\frac {H} {4} * \frac {W} {4} * N_q} \)를 생성합니다. 그 후, \( \mathcal {M}_l \)에 sigmoid를 취하고 0.5의 임계 값을 기준으로 이상의 값들만 True로 Attention 연산을 진행합니다.
모든 Mask의 해상도는 \( \frac {H} {4} * \frac {W} {4} \)인데, Cross-Attention을 진행할 Feature map의 해상도에 따라, Bilinear interpolation으로 크기를 맞춰주는 방식으로 Masked Attention을 진행합니다.
- Multi-Scale 구조
위와 같이 Masked Attention이 어떻게 진행되는지 보았고, Multi-Scale 구조에 대해 이 Masked Attention이 어떻게 진행되는지 확인하겠습니다. 전술했듯이, 고 해상도의 피처가 작은 객체에 대한 좋은 성능을 보이는 것은 예전부터 증명되어 왔습니다. 하지만, 이 고해상도를 모든 Transformer Decoder에서 Cross-Attention 연산을 진행하면 계산량이 너무 많이 듭니다.
따라서 본 논문은 Pyramid 구조로 저해상도부터 고해상도까지 활용하되, 한 해상도의 Feature map과 한 Transformer Decoder layer의 Cross-Attention 연산만 진행되게 구성하였습니다. 다시 말해, Feature Map과 Transformer Decoder layer의 1:1 매칭 구조를 만들었고, [(\( X_1, P_1 \)), (\( X_2, P_2 \)), (\( X_3, P_3 \))]를 하나의 Decoder Layer로 이것을 L번 반복하였습니다. 그리하여 총 Layer는 3L이 됩니다.
이 연산에서 Transformer Decoder 쿼리들은 inusodial Positional Embedding을, Pixel Decoder의 Feature Map은 앞서 말한 Level Position Embedding을 위치 정보로 활용합니다.
- 최적화 향상
최적화 향상에서는 첫 번째로 Cross-Attention 진행 후 Self-Attention을 진행하는 것으로 기존의 Self 후 Cross-Attention을 진행하는 순서를 변경하였습니다. 이렇게 한 이유는 처음에 Transformer Decoder의 쿼리들만으로 독립적인 Self-Attention을 진행하면, 이미지 Feature map에 대한 풍부한 정보를 학습하지 못한다고 주장합니다.
두 번째로 처음 쿼리 피처(\(X_0 \))이 0으로 초기화되어 있고 여기에 위치 정보를 주입하는 식으로 설계되어 있는데, 이 쿼리 피처를 학습가능하게 변경했다고 합니다. 이게 무슨 말이냐면 기존 Transformer Decoder에서 쿼리 피처가 연산하는 방식이 아래와 같습니다.

대충 저런 식으로 되는데, 본 논문에서는 첫 쿼리 피처 \(X_0 \) 첫 마스크 \(M_0 \)를 예측해야 하기 때문에, 고정값인 0으로 초기화하는 것은 적절하지 않다고 하네요. 아울러 이러한 구조가 CNN의 Region Proposal network와 유사한 기능을 한다고 합니다.
그리고 성능 저하를 초래하는 Dropout을 모두 제거했다고 합니다. 또한, 학습의 효율성을 위해 PointRend(추후에 다룰 예정)의 아이디어를 빌려 전체 해상도(GT는 1024 * 1024)에 대한 학습이 아니라, 112 * 112 해상도를 랜덤 하게 추출하여 학습하는 방식을 채택하였습니다. 메모리를 18GB에서 6GB까지 아낄 수 있게 되었다고 하네요.
마치며
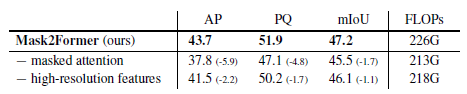
Masked Attention이 성능에 크게 좌우하고 있는 것을 볼 수 있습니다. 이리하여 " 처음부터 지역적인 부분에 대한 연산만 진행하면 수렴속도는 물론 성능 또한 잘 나오지 않을까"라는 가설이 증명되었습니다.
그리고 아래를 보시면, 첫 쿼리 피처를 학습가능하게 했을 때, 생각보다 성능이 잘 나온 것을 확인할 수 있습니다.
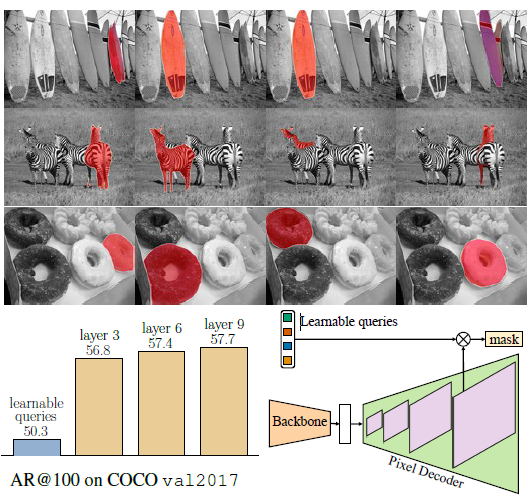
오늘은 Mask2 Former의 리뷰를 해보았습니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Semantic segmentation' 카테고리의 다른 글
| [논문리뷰] Twins: Revisiting the Design of Spatial Attention inVision Transformers (0) | 2024.05.12 |
|---|---|
| [논문리뷰] Segmenter: Transformer for Semantic Segmentation (0) | 2024.04.29 |
| [논문리뷰] SETR: SEgmentation TRansformer (0) | 2024.04.29 |
| [논문리뷰] MaskFormer (0) | 2024.03.21 |
| [논문리뷰] SegFormer: Simple and Efficient Design for SemanticSegmentation with Transformers (0) | 2024.01.10 |




댓글