들어가며
오늘은 Transformer 구조를 semantic segmentation에 사용한 SegFormer를 리뷰하려고 합니다.
이 모델을 네트워크 속도 향상에 중점을 두면서도 성능을 최소한의 파라미터로 극대화한 모델입니다. 단순히 속도만 끌어올린 것이 아닌, 성능 또한 최소한의 파라미터로 개선하였습니다. 그렇게 하여 동일한 파라미터 대비 CNN, Transformer 기반의 모든 모델들의 성능을 능가하였으며, 심지어 제일 가벼운 버전의 Segformer(파라미터 수에 따라 여러 버전이 있음)는 real-time도 가능하다고 합니다. 이런 것을 가능하게 해 준 몇 가지 기법이 있습니다:
- 계층적인 Transformer 인코더: CNN은 이미 이러한 계층적인 구조를 사용하고 있습니다. 그렇다면 왜 계층적인 구조를 사용하느냐?

위는 기존 CNN의 백본이 동작하는 방식입니다. 고정된 Kernel size를 가져가고 중간에 Maxpooling으로 이미지의 해상도를 줄여가며 수용 필드를 늘려가는 구조입니다. 이렇게 함으로써 더 많은 Representations을 학습할 수 있고, 더 나은 정확도를 가져왔었죠.이처럼 CNN은 semantic segmentation에서 수용 필드를 늘리려고 이뿐만 아니라 여러 가지 기법을 활용하고 있습니다.
Transformer는 애초에 전체 픽셀에 대해 전역적으로 attention 값을 구하기 때문에 수용 필드가 기본적으로 큽니다. 그래서 이 구조를 도입하면 다양한 해상도에서 큰 수용 필드로 풍부한 표현력을 학습할 수 있습니다. 그리고 기본적으로 Transformer를 사용하는 구조는, 입력과 출력의 차원이 같아 계속해서 전역적인 수용 필드를 가지는데, 이 것은 해상도가 올라갈수록 attention 값을 구해야 하는 영역도 넓어져 계산량이 기하급수적으로 올라갈 것입니다.
반면에, 계층적인 구조는 계속해서 해상도를 줄여가기 때문에 줄어든 해상도에 대한 attention 값을 구하여, 다양한 해상도의 다양한 Representations뿐만 아니라 계산속도에도 이점이 있습니다.
여러 해상도에서 다양한 Representations를 학습하고, 연산속도에도 이점이 있으니 당연 도입할 수 밖에 없습니다. - Lightweight MLP 디코더: 기존 모델들의 디코더는 CNN으로 구성되어, 인코더에 출력한 features들로부터 segmentation mask를 복원하는 구조를 따릅니다. 하지만 본 논문은 아주 가벼운 MLP 레이어 몇개만으로 디코더를 구성하였다고 합니다. 이게 가능한가 싶은데, 계층적인 인코더의 고해상도에서 global context, 저해상도에서 local context를 결합하여 풍부한 표현력을 가지면 디코더에서 딱히 할 것도 없이 이 표현들만 활용하여 충분히 Segmetation mask에 대한 형성이 가능하다고 합니다.
- Mix-FFN: 실험적으로 기존의 Positional encoding는 오히려 성능을 저하하였고, 이는 훈련하는 이미지 해상도와 테스트하는 해상도가 차이가 있기 때문이라고 합니다. 그래서 Mix-FFN 이라는 다른 기법을 사용합니다.

실험 파트에 있는 어느 부분을 가져왔습니다. 왼쪽에 보시면 PE가 Positional encoding인데 확실히 성능 차이가 많이 나죠? 근데 막 엄청난 기술이 사용된 것 같겠지만, 진짜 별 거 없습니다. "오히려 이게 된다고?" 하실 수도 있습니다.
오른쪽도 디코더 레이어의 파라미터 수를 보면 인코더에 비해 아주 낮은 것을 볼 수 있습니다. 그래도 성능이 아주 잘나옵니다.
대략적인 흐름은 이렇고 이제 아래에서 자세히 설명하겠습니다.
Method
SegFormer는 어떠한 많은 계산양을 요구하는 모듈이 없습니다. 전체적인 구조는 아래와 같습니다.

위에서 설명한 계층적인 Transformer 인코더와 lightweight MLP 디코더로 설계되었습니다. 네트워크의 흐름은 아래와 같습니다.
1. 16 x 16 크기의 패치들을 사용하는 ViT와 대조적으로 4 x 4 크기의 패치들을 사용(인코더에서 더 풍부한 표현력을 학습하기 위해 패치 크기를 작게 가져간 것으로 보임).
2. 위 패치들을 계층적인 Transformer 인코더의 입력으로 사용하고, 오리지널 입력 해상도의 {1/4, 1/8, 1/16, 1/32}의 multi-level features를 획득한다.
3. 이 multi-level features를 MLP decoder로 입력한다. 결과적으로, \( H/4 * W/4 * N_{cls} \)의 해상도를 가지는 segmentation mask를 예측한다(\(N_{cls}\)는 데이터 세트의 클래스 개수).
흐름은 대충 이렇습니다.
Trasnformer 인코더
계층적인 Feature Representation
오직 하나의 해상도의 feature map만 활용하는 ViT와는 달리, multi-level features를 생성합니다. 보통 계층적 구조와 같이 고해상도에서는 거친 표현들을, 저해상도에서는 좀 더 세밀한 표현들을 제공합니다.
위와 같이 계층적인 구조를 실현할 수 있는 것은, 중간중간에 patch merging을 하여 해상도를 줄이기 때문입니다. 각가의 계층적인 각 feature map \( F_i \)의 해상도는 \( \frac {H} {2^{i+1}} \) x \( \frac {W} {2^{i+1}} \) x \( C_i \) , \( i \in \left\{ 1, 2, 3, 4 \right\} \)입니다.
Overlapped Patch Merging
기존 patch merging은 \( 2 \) x \( 2 \) x \( C_i \)의 해상도를 가지는 하나의 패치가 \( 1 \) x \( 1 \) x \( C_{i+1} \)로 사영되어 해상도를 줄입니다. 이 과정에서, 각 패치들의 해상도가 줄어들면서, 예를 들어 \( F_1 \) (\( \frac {H} {4}\) x \( \frac {W} {4} \) x \( C_1\))가 \( F_2 \) (\( \frac {H} {8} \) x \( \frac {W} {8} \) x \( C_2 \)) 로 해상도가 감소합니다. 이러한 과정은 모델의 모든 계층적 구조에서 일관되게 적용되며, 이를 통해 효율적으로 특징 추출을 수행하고, 네트워크의 깊이를 증가시키면서도 계산 비용을 절감합니다. 이 방식은 SegFormer가 높은 해상도의 이미지에서도 효과적으로 작동할 수 있도록 돕습니다.
하지만 이렇게 패치들을 겹치지 않게 독립적으로 해상도를 줄이는 방식은 local continuity를 보존하는 것이 어렵다고 합니다. 아래 그림(a)과 같이 패치와 패치사이에 경계선이 생기는은 현상을 말하는 것 같습니다. 따라서, 본 논문에는 이러한 patch merging 과정을 그림(b)과 같이 약간식 겹치게 하여 진행하였다고 합니다. K, S, P가 각각 patch size, stride, padding이라 하면 [K=7, S=4, P=3], [K=3, S=2, P=1]의 커널을 활용하여 진행했다고 하네요.

Effcient Self-Attention

위 식은 기존 Transformer에서 attention을 구하는 식입니다. Q, K, V는 각각 같은 차원인 \( N \) x \( C \) 차원이고, 이 연산의 시간복잡도는 \( O \left( N^2 \right) \)입니다(\( N = H * W \)). 이 시간복잡도는 해상도가 커지면 커질수록 더 커집니다. 본 논문에서는 시간을 더 줄이기 위해 \( R \)의 비율만큼 \( N \) 패치의 길이를 줄이는 방법을 선택하였습니다.

위 과정은 K의 차원을 \( frac {N} {R}, C * R \)로 줄이고, \( C * R \)의 채널을 \( C \) 차원으로 사영시킴으로써 최종적으로 \( frac {N} {R} * C \) 차원으로 줄여집니다.
그러므로 시간복잡도는 \( O \left( N^2 \right) \)에서 \(O \left(\frac {N^2} {R} \right) \)로 줄여집니다. 본 논문에서 \( R \) 비율은 stage-1부터 stage-4까지 [64, 16, 4, 1]로 설정했다고 합니다.
Mix-FFN
본 논문에서는 Positional encoding(PE)이 성능 저하를 불러일으킨다고 하였습니다. 이것을 기존 Feed-Forward Network(FFN) 사이에 3 * 3 convolution을 섞어 줌으로써 부족한 지역 정보가 해결됐다고 합니다(3 * 3 Conv에서 zero padding이 이 효과를 나타낸다고 함). 특히 이 부분에서 파라미터 수를 줄이기 위해 depth-wise convolutions을 사용한다고 합니다.
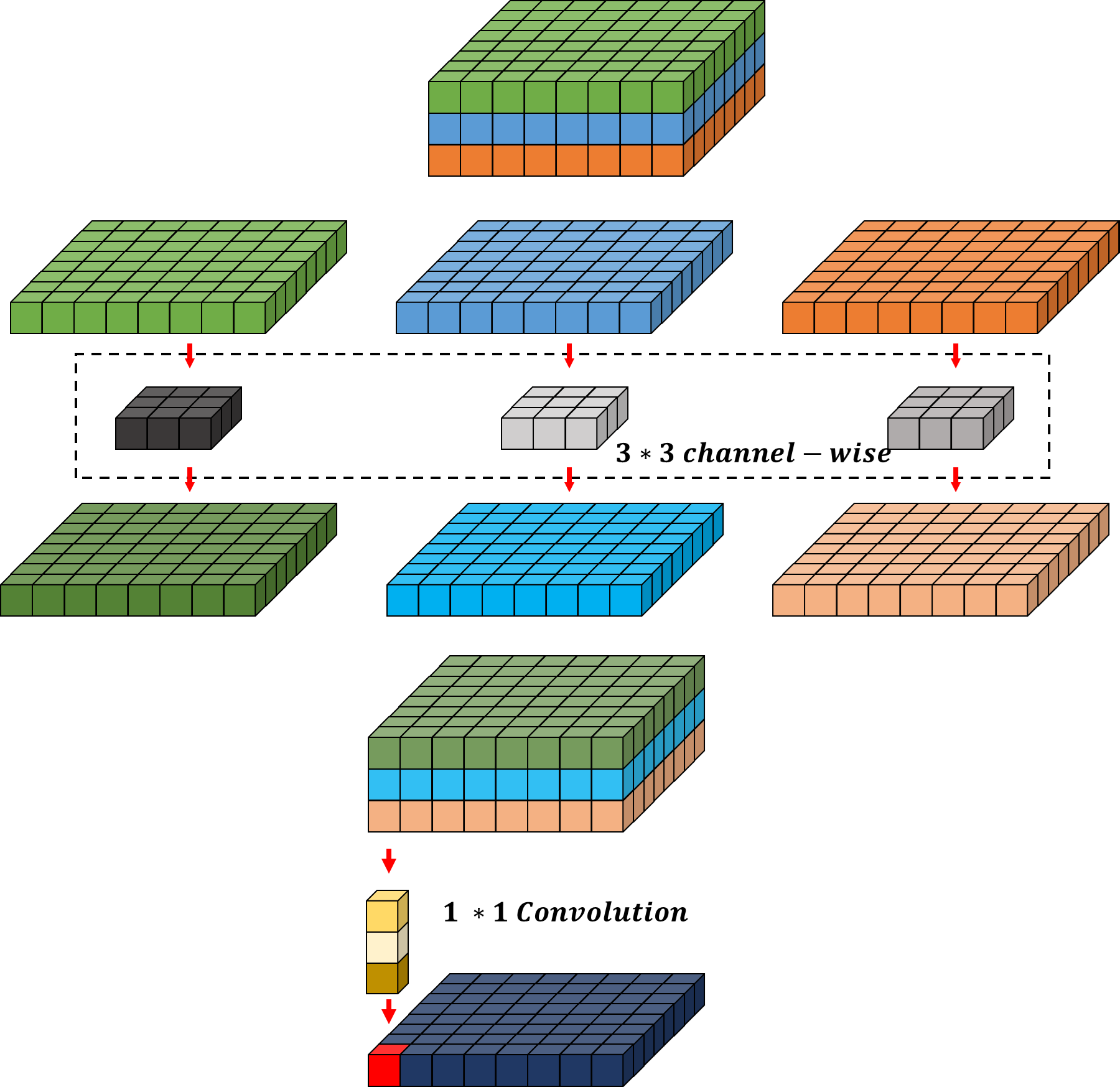
기존 3 * 3 convolution 연산과 똑같은 출력을 가지지만, 속도에 이점이 있음
Lightweight All-MLP Decoder
아래는 기본적인 CNN에서 semantic segmentation을 하기 위한 구조입니다. 인코더에서 수용 필드를 늘려 풍부한 표현력을 학습하거나, 디코더를 인코더의 계층과 동일하게 구성하여 점진적으로 segmentation 마스크 복원해야 합니다.

이와 달리, Segforemer는 오직 MLP 레이어들로만 디코더를 구성합니다. 아까 말한 인코더에서 Transformer 구조를 가져, 큰 수용 필드를 가지고, 계층적인 구조로 속도와 표현력이 이점이 있다고 말씀드렸습니다. 그래서 디코더에는 별다른 레이어를 추가할 필요가 없는 거죠. 디코더의 전체 수식은 아래와 같고 총 4개의 단계로 구성됩니다.

- 먼저 인코더로부터 출력된 multi-level features(\( F_i \))의 채널을(\(C_i\)) \( C \) 차원으로 사영되기 위해 MLP(Linear) 레이어로 입력됩니다. 계층적 인코더의 출력인 \( \hat {F_1} = \frac {H} {32} * \frac {W} {32} * C_1 \), \( \hat {F_2} = \frac {H} {16} * \frac {W} {16} * C_2 \), \( \hat {F_3} = \frac {H} {8} * \frac {W} {8} * C_3 \), \( \hat {F_4} = \frac {H} {4} * \frac {W} {4} * C_4 \)에 모두 진행.
- 1번에서 출력된 \( \hat {F_1}, \hat {F_2}, \hat {F_3}, \hat {F_4} \) 모두 \( \frac {H} {4} * \frac {W} {4} \)의 차원으로 Upsampling 해줍니다.
- 2번에서 출력된 \( \hat{F_1}, \hat{F_2}, \hat{F_3}, \hat{F_4} \)들을 모두 채널을 기준으로 결합해 주고, 결합된 \( 4C \) 차원의 모든 계층적인 Representations를 \( C \) 차원으로 융합시킵니다.
- 최종적으로 3번에서 융합된 \( \frac {H} {4} * \frac {W} {4} * C \)를 데이터의 클래스 개수 (\(N_{cls} \))만큼 사영시켜 segmentation mask를 예측합니다.
이제 이 디코더가 진짜로 Representations을 잘 융합했는지 확인해 볼까요?
수용 필드 분석
이 파트에서는 MLP 디코더가 효과적으로 context 정보를 담고 있는지 분석합니다. 아래 그림은 CNN기반인 DeepLab3+과 Transformer 기반인 SegFormer의 인코더에서 Stage-1, Stage-2, Stage-3, Stage-4, 디코더 헤드를 시각화한 것입니다.

Segformer 인코더의 stage-1에서 Convolutions과 같이 아주 local attentions을 제공하고(점이 작음), stage가 올라갈수록 global attentions을 제공하는 것(점이 커짐)을 볼 수 있습니다. Stage-4(빨간 박스)와 MLP head(파란 박스)를 자세히 보면, 약간의 차이가 있습니다. Stage-4의 attention과 달리, stage-4보다 더 local attention의 연산을 진행하는 stage-1, stage-2, stage-3을 결합한 디코더 헤드는 중앙으로 갈수록 더 짙어지는 것을 알 수 있고, 이것은 다른 Stage의 정보들을 잘 결합한 것으로 볼 수 있습니다.
CNN은 위와 같이 수용필드를 늘리려면 ASPP(Atrous spatial pyramid pooling)와 같은 context module을 사용하여야 하는데, 성능은 좋아질지 몰라도 필연적으로 모델이 무거워진다는 단점이 있습니다.
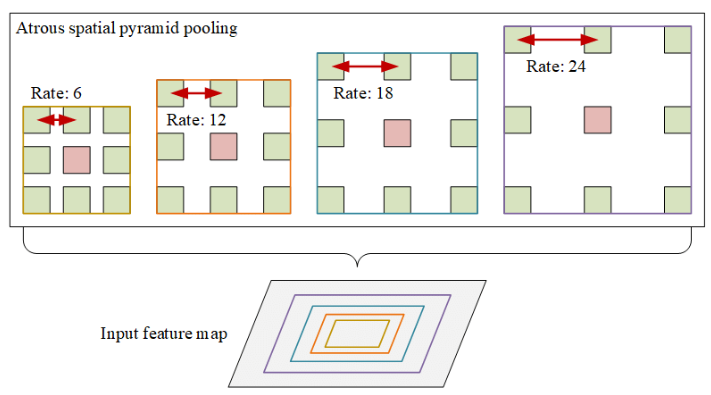
- Atrous Convolution: 커널 사이사이에 패딩을 주어, 커널의 수용필드를 늘리는데 이 패딩의 비율(높을수록 커널의 사이가 넓어짐)
- 다양한 비율을 가지는 Atrous Convolution에 풀링을 거쳐, 더 넓은 수용필드로 다양한 표현을 결합하여 풍부한 표현력을 가진다.
Transformer는 이런 복잡한 거 없이 큰 수용필드를 가집니다. 또한, 인코더의 계층적 구조를 통합하는 디코더의 구조는 local, global attention을 동시에 가져올 수 있다는 장점이 있습니다. 그렇게 때문에 낮은 파라미터로도 강력한 표현력을 가진다고 제시합니다.
Experiments
SegFormer는 다양한 크기의 피쳐 맵을 계층적인 구조로 혼합하여 처리하기 때문에, Mix Transformer encoder(MiT)라 불립니다. 이 시리즈는 크기에 따라 MiT-B0 ~ MiT-B5까지 있습니다.

3개의 데이터 셋에 대해 성능 비교를 하고 있습니다. mIoU 옆에 SS, MS는 각각 single scale, multi-scale에 대해 성능 비교를 한 것입니다. 여기서 유심히 봐야 할 것은 Decoder의 파라미터가 거의 없다는 것입니다. MiT-B0와 같은 모델은 실시간에도 활용이 가능하겠네요.
Mix-FFN vs. Positional Encoder(PE)
본 논문에서는 PE를 쓰지 않는다고 했었습니다.
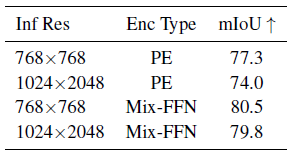
위는 PE를 사용했을 때, Mix-FFN를 사용했을 때의 성능 비교입니다. 확실히 Mix-FFN이 성능이 많이 올라갔지만, 앞선 전술한 것처럼 PE는 훈련 사이즈와 테스트 이미지 사이즈가 달라 성능이 크게 저하된다고 하였습니다. 그렇게 때문에 Mix-FFN 보다 해상도가 변함에 따라 성능의 폭이 크네요.
효과적인 수용 필드 검증
이번에는 Transformer의 인코더가 얼마나 수용 필드가 넓어 풍부한 표현력을 가지는지, CNN과 같은 MLP 디코더를 활용하여 비교해 봅시다.

여기서 S는 각 계층적인 단계를 의미합니다. 딱 봐도 CNN에는 lightweight 디코더를 붙이니 성능이 엄청 떨어졌네요. 이 것이 수용필드가 작아 효과적인 표현력을 전달하지 못했기 때문으로 해석합니다. 또한, MiT는 stage-4의 표현들만 활용해도 파라미터수는 낮고, 성능은 아주 높은 것을 확인하였네요.
오늘은 컴퓨터 비전에서 사용하는 self-supervised learning 논문인 MAE 한 번 리뷰해 보았습니다.
자세한 내용은 본 논문을 참고하시고, 언제나 게시글에 대한 피드백은 환영입니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Semantic segmentation' 카테고리의 다른 글
| [논문리뷰] Twins: Revisiting the Design of Spatial Attention inVision Transformers (0) | 2024.05.12 |
|---|---|
| [논문리뷰] Segmenter: Transformer for Semantic Segmentation (0) | 2024.04.29 |
| [논문리뷰] SETR: SEgmentation TRansformer (0) | 2024.04.29 |
| [논문리뷰] Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation (1) | 2024.04.18 |
| [논문리뷰] MaskFormer (0) | 2024.03.21 |




댓글