Abstract
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
자연어 분야는 본문 요약, Q & A, 유사성 평가, 문서 분류 등 여러 분야에서 발전해 왔습니다.
unlabel 된 text는 아주 많지만, 특정한 task에 label 된 data는 아주 부족합니다. 본 논문에서는 이러한 unlabeled 된 데이터를 버리지 말고 generative pre-training 하고, 특정한 테스트에 맞게 labeled 된 데이터를 알맞게 discriminative fine-tuning 하였고 높은 성과를 낸 논문입니다. pretraining -> fine-tuning 하는 과정에서 model architecture는 최소한으로 변경하고 12개의 task 중 9개의 task에서 state of the art를 냈다고 합니다.
Introduce
raw text를 효과적으로 학습하는 능력은 아주 중요합니다. 왜냐하면 NLP분야에서 label된 데이터는 부족하기 때문에 어떻게든 unlabel된 데이터를 최대한 활용하여 지도 학습에 대한 의존성을 완화해야 합니다. 설령 label 된 데이터가 엄청나게 많다고 해도 미리 unlabel 데이터로 학습하여 좋은 representation을 배워놓으면, label 된 데이터로 학습했을 때 중요한 부스트역할을 해줍니다.
하지만, 이 방법이 쉬웠다면 본 논문이 나올 이유가 없었겠죠. 기존 unlabel된 데이터로는 단어 수준의 정보밖에 얻지 못하고, 2개의 문제점이 항상 존재했습니다.
- 단순하게 텍스트를 학습하는데 즉, pretrained model을 학습하는데 무엇이 optimization이고 효과적인지가 불분명
- pretrained model을 fine-tuning하는데 무엇이 가장 효과적인지 알 수가 없음
그냥 단순하게 pretrain이랑 fine-tuning하는 방법이 명확하지 않았습니다. 현재 있는 기술로는 task-spefic에 맞게 model의 구조를 바꾸고 복잡한 scheme를 추가하는 것이었고, 이러한 불확실성이 semi-supervised learning에 어려움을 가지고 있었습니다.
본 논문 모든 task에 보편적인 representation을 학습하여, 기존 모델은 최소한의 변화로 task-spefic에 맞게 학습 하는것이 목표입니다. 이것은 두 가지 훈련 절차로 진행됩니다.
- 초기에 네트워크 parameters(representation)를 배우기 위해 unlabeled data를 활용하여 학습합니다.
- 목표하는 task에 맞게 pretrain된 parameters를 사용합니다.
네트워크는 Transformer의 구조를 사용하였고,기존 RNN보다 text에서 long-term dependency를 핸들링 할수있는 많은 메모리 구조를 가지고 다양한 task에도 robust 하게 작동합니다(12개 task 중 9개에서 state of the art).
Related Work
Semi-supervied learning
semi-supervised learning은 라벨링, 텍스트분류 등 많은 관심을 끌고 있었습니다. 본 논문 나온 시점 가장 최근 연구는 unlabeled data가 ELMo와 같은 단어 정도의 정보에 활용되었습니다. 이런 수준에 미치는 것이 아니라 unlabeled data를 좀더 높은 수준(구, 문장)으로 사용하겠다는 취지입니다.
Unsupervised pre-training
Unsupervised pre-training시키는 것은 초기 좋은 representation을 찾는데 목적에 둡니다. 그래야 supervised learning에서 잘 동작하기 때문입니다. 최근 pre-training은 이미지분류, 음성인식, 기계번역 등 여러 분야에서 도움이 되었다고 증명합니다. pre-training이 여러 분야에서 도움이 되긴 하지만 기존 LSTM과 같은 것들은 언어의 정보를 즉, 긴 문장을 수용할수 있는 능력이 안된답니다. 하지만 transformer는 이것이 가능하다는 걸 본 논문에서는 실험으로 증명이 되었답니다. 아울러 natural language inference, paraphrase detection, storpy completion 등에서도 증명이 되었습니다.
Auxiliary training objectives
본 논문은 unsupervised pre-training의 목적함수를 supervised fine-tuning할 때 auxiliary objective로 추가하였습니다. 단순하게 supervised learning의 목적함수에 unsupervised learning 목적함수를 추가하였고 이것을 auxiliary objective라고 표현합니다. 이러한 방법은 이미 여러 연구에서 좋은 성과를 내었습니다.
GPT-1
앞서 말한것과 같이 이 모델 2 stage의 절차를 거칩니다.
1. Unsupervised pre-trainig
Tokens \( U = {u_1, u_2,..., u_n} \)이 있다고 하면 표준의 likelihood가 maximize 하는 식을 따릅니다.

\( k \)는 여기서 context window의 사이즈이고, \( Θ \)는 뉴럴네트워크의 파라미터입니다.
위 식은 이 네트워크에서 \( u_{i-k}, ..., u_{i-1} \)가 주어졌을 때 \( u_i \)의 확률값을 계산하는 식입니다. 예컨대, I love you라는 문장이 있으면 I, love 가 주어졌을 때 you를 예측하는 확률값입니다.
본 논문에서는 Transformer의 decoder부분을 사용하였습니다.

기존 decoder 부분에서 encoder layer가 없기 때문에 encoder-decoder attention을 제외하였고, 임베딩(\( W_e\))후 potision embedding matrix( \( W_p \) )를 더하고, layer의 갯수만큼 decoder block을 통과하고 position-wise layer( \(W_e^T \) )를 거쳐 softmax로 확률값을 구합니다.
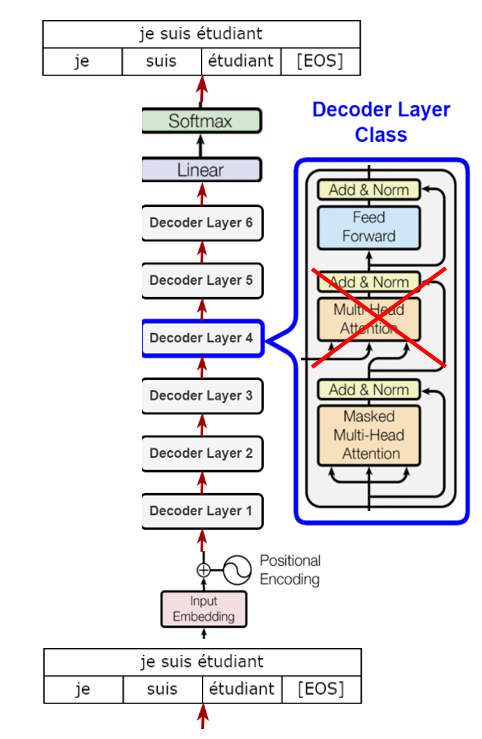
2. Supervised fine-tuning
이제 pretrain 모델로 fine-tuning을 할 차례입니다. supervised learning이기 때문에 task에 따라 시퀀스에 따른 label값이 있어야합니다. \( C \)는 데이터세트, 각 sequence마다 토큰들 \(x^1,..., x^m \), \( label = y \)로 가정하겠습니다.
위 그림처럼 pretrain된 모델의 Position-wise layer와 softmax layer 사이에 linear layer(\(W_y\)) 하나를 추가하여 각 task마다 label y를 예측합니다.
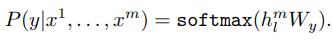
이 식을 모든 데이터세트의 log likelihood를 최대화 하는 식으로 바꾸면

추가적으로 아까 위 Related Work 에서 auxiliary objective를 추가하여 모델의 성능을 높였다고 하였는데 2가지 성능향상에 효과가 있습니다.
- supervised model에 일반화 성능을 향상
- 수렴 속도를 가속
fine tuning 할 때, unsupervised learning도 가중치(\( λ \))를 곱해주어 log likelihood를 최대화하면 위 2가지와 같은 장점을 가졌다고 합니다.
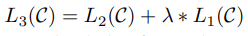
3. Task-specific input transformations
앞서 말한것 처럼 GPT-1은 최소한의 변화로 여러 task를 다룬다고 하였습니다. 기존 연구들은 전송된 representation위에 새로운 architecture를 하나 더 달아 복잡한 구조였습니다. 상당한 양의 task-specific의 customization이 필요하여 전이 학습을 사용하지 않았습니다. GPT-1의 traversal-style은 구조화된 input으로 전이 학습을 최소한의 변화로 가능하게 하였습니다.

- Classification: 기존 분류 문제와 같습니다.
- Textual entailment: 전제(premise)와 가정(hypothesis) 두 가지의 시퀀스 토큰들을 중간 구분 문자($) 를 사용하여 한번에 네트워크에 forward 합니다.
- Similarity: 두문장의 유사성을 비교할 때 어느 전제와 가정처럼 순서가 존재하지 않습니다. 그래서 문장 순서를 반영하기 위해 (text1, text2), (text2, text1) 두 가지를 각각 모델에 forward 하여 마지막 linear layer에 들어가기 전 element-wise로 합하여 출력합니다.
- Question Answering and Commonsense Reasoning: 이 task에서는 지문 \( z \), 질문 \( q \), 정답 리스트( \( a_1, a_2,... a_k \) )가 있습니다. 각 정답 리스트 k개만큼의 각각 모델에 forward 하여 리스트들의 softmax를 구해 가장 정답에 가까운 값을 구합니다.
Experiments
setup
Unsupervised pre-training에는 BooksCorpus라는 데이터셋을 사용하였는데 7,000개가 넘는 다양한 장르의 출간되지 않는 책들로 long-range 정보를 학습하기에 좋은 긴 지문 데이터셋입니다. transformer decoder layer는 총 12층으로 구성되어 있고, self-attention head는 각 64개의 Q, K, V과 총 12개의 heads로 구성되어 있습니다. position-wise feed-forward는 총 3072차원이며 Adma optimizer를 사용하였습니다.
Fine-tuning은 \( λ \)를 0.5로 설정한 것 제외하고는 나머지 하이퍼파라미터는 Unsupervised와 거의 동일합니다.
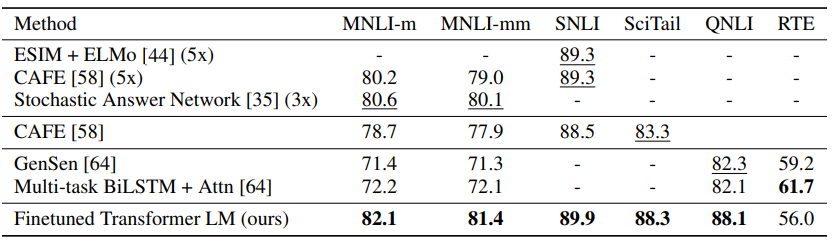
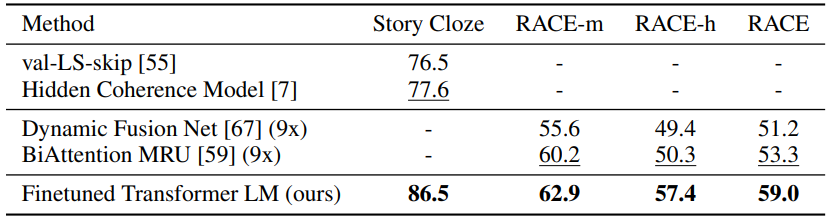
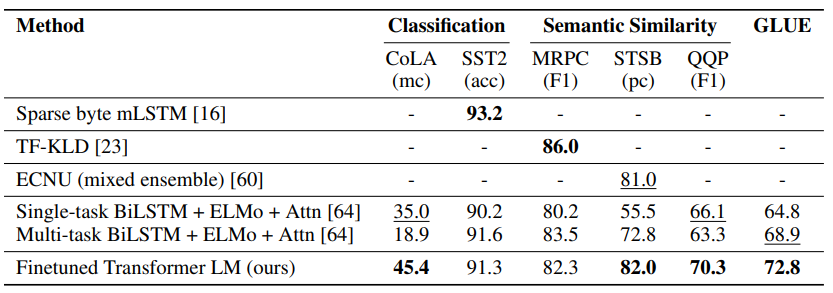
아래는 task 12개 중에 9개의 dataset에서 state of the art를 달성한 테이블입니다.
Conclusion
GPT-1에서는 기존 방식과 달리 task별로 architecture를 설계해야 하는 것이 아닌 generative pre-training 모델과 discriminative fine-tuning모델을 제안하였습니다. 다양한 긴 문장을 pre-train 함으로써 long-range dependency 처리하고 question answering, semantic similarity assessmet 등 12개 중 9개 task에서 state of the art의 성능을 내었습니다. 그리고 LSTM과 Transformer를 비교했을 시 Transformer의 성능이 월등히 높았습니다. 이제 RNN 말고 Transformer 써라라는 것 같네요).
OpenAI가 발표한 Chat-gpt의 토대가 되는 논문이므로 한번 읽어보시길 추천드립니다.
긴 글 읽어주셔서 감사합니다.
'NLP' 카테고리의 다른 글
| [논문리뷰] BERT(Pre-training of Deep Bidirectional Transformers forLanguage Understanding)의 이해 (0) | 2023.06.14 |
|---|---|
| [논문리뷰] ELMo(Deep contextualized word representations)의 이해 (0) | 2023.06.12 |
| [논문리뷰] Attention is All you need의 이해 (4) | 2023.06.06 |



댓글