Abstract
- unlabel 된 데이터를 pretrain 후, label 된 데이터를 task에 맞게 fine-tuning 해주면 성능이 더 좋아집니다.(OpenAI GPT, ELMo,...)
- ELMO와 같이 network를 left-to-right뿐만 아니라 right-to-left도 결합하여 unidirectinal > bidirectional로 하였을 때 더 성능이 좋아졌다는 연구도 있습니다.
BERT는 위 두 가지 강점을 합친 모델입니다. Bidirectional Encoder Representation from Transformer의 약자로 Transformer를 활용하여 unlabeled 데이터를 bidirectional 하게 pretrain 시키겠다는 의미입니다. pretrained model에 fine-tuning 하는 과정에서 task에 따라 architecture의 큰 수정 없이 간단하게 output layer 하나를 추가함으로써, 광범위한 task에서 state of the art를 기록하였습니다.
Introduction
Language model에서 semi supervised learning은 큰 효과를 거두고 있었습니다. 이러한 NLP task는 최근에 token-level task 뿐만 아니라 Q & A와 같은 sentence-level까지 커버하는 연구가 이루어졌습니다. 이러한 pre-trained language representations을 downstream에 적용하는 방식은 크게 feature-based와 fine-tuning이 있습니다
- feature-based: ELMo와 같이 특정 task를 수행하는 network에 pre-trained language representation을 feature로 제공합니다.
- ELMo는 각 task별 pretrained 된 network에 각 layer의 가중치를 줍니다. 예컨대 품사 등 문법 정보가 중요한 분야는 low-layer, 문맥 정보가 중요한 분야는 high-layer에 높은 가중치를 둡니다.
- 모든 layer들의 출력값에 1번에서 준 가중치를 곱하여 모두 더합니다.
- 2번에서 weighted sum이 ELMo라 하고, 각 word마다 sentence-level로 학습한 이 feature를 downstream에 적용할 때 input이나 output에 concatenate 하여 사용합니다.
- fine-tuning: GPT-1과 같이 task-specific 한 parameters를 최소한으로 줄입니다. 그러니까 최소한의 변화로 fine-tuning을 하여 fine-tuning 할 때 parameters의 비용을 최소한으로 들게 하자 라는 의미입니다.
- GPT-1은 Transformer의 decoder 부분만을 사용한 network입니다.
- 기존 unlabeled 된 data들로 pretrain 합니다
- 모든 task에 공통된 pretrained-model을 사용하고, task마다 input의 구조만 약간 바꾸어 fine-tuning 합니다.
두 모델은 pre-training시 같은 목적함수를 공유하고, general language representation을 unidirectional 하게 학습하는 모델입니다. 이러한 unidirectional 한 구조는 pre-trained representations을 학습할 때 제한이 있었습니다. 예컨대 위 GPT-1은 Transformer의 decoder 부분만을 사용하는 left-to-right 구조 때문에 이전의 token 만 고려하여 전체 맥락을 중요하게 여기는 Q & A 같은 task에는 한계가 있었습니다.

BERT는 fine-tuning based approach를 향상한 모델입니다. masked language model(MLM)이라는 아이디어를 제시하였습니다. 이름과 같이 input token을 random 하게 mask를 씌워 입력으로 사용하고, original setence의 token들을 출력으로 사용하여 pre-training 합니다. MLM을 사용하면서 undirectional의 한계점을 bidirectional 하게 바꾸어 극복하였고, 기존 ELMo처럼 LSTM 두 개를 합친 얕은 bidirectional 한 모델이 아니라 더 deep 한 bidirectional representations을 pre-train 합니다.
또한, 기존 token들이 짝을 이루어 다음 token을 예측하는 구조였다면, next sentence prediction(NSP)이라는 아이디어이 추가로 도입되어 문장들이 짝을 이루어 다음 문장인지 아닌지 분류합니다.
Related Work
1. Unsupervised Feature-based Approaches
광범위하게 적용가능한 words의 representations을 학습하는 것은 수십 년 동안 연구되어 온 분야입니다. 잘 학습된 Pre-trained word embedding은 NLP 분야에서 엄청난 성능 향상을 가져올 것입니다. 여러 연구가 이루어졌지만 본 논문에서 다루는 ELMo만 간단하게 하겠습니다.
ELMo(Embeddings from Language Model)는 잘 학습된 Pretrained word embedding이라고 할 수 있습니다. 비록 shallow 하지만 bidirectional 하게 context-sensitive features를 추출합니다. 당시 여러 task에서 state of the art의 성능을 보였으며 상당히 text generation model에서 robust 하다고 할 수 있습니다.
2. Unsupervised Fine-tuning Approaches
최근, unlabeled data로 pre-train 하고, 후에 labeled data로 fine-tuning 하는 연구가 활발하게 이루어지고 있었습니다. 이러한 것의 장점은 downstream을 학습할 때 아주 작은 파라미터밖에 필요하지 않다는 것입니다. GPT-1가 본 논문이 나온 시점 여러 task에서 state of the art의 성능을 보여줬습니다.
BERT
이 전의 연구들과 같이 pre-training 후 fine-tuning의 절차를 거치지만 downstream의 각 task마다 같은 pre-trained parameters를 사용합니다.

1. Model Architecture
BERT는 transforemer의 encoder 부분만 사용하고, BASE, LARGE 두 가지 모델로 나뉩니다.
- \(BERT_{BASE} \): L=12, H=768, A=12, Total Parameters=110M
- \(BERT_{LARGE} \): L=24, H=1024, A=16, Total Parameters=340M
- L= Transformer block layer의 수, H= hidden size, A= self-attention 헤드의 수
BERT는 GPT와 거의 유사합니다. 변경된 점은 두 가지가 있습니다.
- Transformer decoder > Transformer encoder
- unidirectional self-attention > bidirectional self-attention
2. Input/Output Representations
다양한 downstream tasks에 BERT가 잘 동작하기 위해, single sentence와 a pair of sentences(e.g., Q & A)를 하나의 token sequence로 잘 처리할 수 있어야 합니다.
- sentence: 우리가 흔히 아는 마침표로 끝나는 문장이 아니라, 임의의 연속된 text입니다. 그러므로 질문, 지문,... 있습니다.
- sequence: 이러한 sentence가 하나 또는 두 개로 표현된 것입니다.
WordPiece embedding을 사용하여 30000개의 토큰을 사용하였습니다. 이 토큰들의 처음에는 무조건 [CLS]라는 special classification token이 들어가고, 이 토큰은 Transformer의 encoder 마지막 layer를 거쳐 출력을 할 때 현재 task에 맞게 작동합니다. 예컨대 스팸메일분석이라 함은 0과 1로 분류될 것입니다.
1개의 sentence가 입력되는 경우가 있지만, 2개의 sentence가 입력되는 경우에는 중간에 [SEP] 구분자 토큰을 삽입합니다(만약 1개의 sentence의 경우 [SEP]을 사용하지 않고 하나의 sentence만 입력).
기존 연구인 GPT-1에서 입력은 Input Embedding에 Positional Embedding을 더해서 입력했습니다. 아울러 본 논문에서는 Segment Embedding이라는 Sentence끼리의 구분을 지어주는 Embedding도 추가로 더해줍니다. 아래그림은 필자가 임의로 삽입한 Embedding 값들입니다.

지금까지의 기술은 이전연구 GPT-1의 기술과 대부분 비슷하다고 생각할지도 모릅니다. 본 논문에서 제안한 기술 MLM(MaskedLM), NSP(Next Sentence Prediction)에 대해 설명하겠습니다.
3. Pre-training BERT
3.1 Masked LM(MLM)
기존의 기술들은 unidirectional 하였고, bidirectional 하더라도 deep 하지 않고 shallow 하다 하였습니다. 그러나 BERT는 아주 심플합니다. Token에 랜덤 한 확률값에 따른 Mask를 씌워 deep bidirectional representation을 학습합니다.
랜덤한 확률값은 실험에 의해 15%가 가장 좋은 성능을 보였습니다. Input은 tokens일부를 랜덤 하게 [Mask]된 것들이고, Output은 [Mask]되지 않은 기존 token들입니다. 문장 전체를 predict 하는 것이 아니라, [Mask] token만을 predict하는 pre-training task를 수행합니다.

이렇게 pre-training을 진행하면 bidirectional representation을 잘 학습되었습니다. 저희는 pre-training 후에 fine-tuning 하는 과정을 거치는데 fine-tuning을 할 때는 MLM의 학습방법을 사용하지 않고 학습을 진행합니다. 이 과정에서 pre-training과 fine-tuning 사이에서 mismatch가 일어난다고 합니다. 이런 mismatch를 개선하는 방안은 아래와 같습니다.
- 15%의 확률값을 주어 랜덤 하게 [MASK] 토큰을 생성할 때, 몇 가지 추가적인 처리를 더 해주게 됩니다.
(e.g., my dog is hairy)- [MASK] 토큰들의 10%는 랜덤 한 토큰으로 변경. my dog is hairy -> my dog is apple
- [MASK] 토큰들의 10%는 기존의 토큰으로 변경. my dog is hairy -> my dog is hairy
- [MASK] 토큰들의 80%는 그대로 [MASK] 토큰으로 유지. my dog is hairy -> my dog is [MASK]
위의 80, 10, 10 %의 확률 비율도 실험에 의해 저 수치가 가장 괜찮았다고 합니다.
3.2. Next Sentence Prediction(NSP)
Q & A나 Natural Language Inference(NLI) 같은 task에서는 모델 두 sentence 간의 관계를 이해하는 것이 아주 중요합니다. 이 두 sentence는 그냥 모델에 넣는다고 해서 direct 하게 capture 되지는 않습니다. BERT에서는 이러한 개선방안으로 단일 corpus에서 setence A, sentence B 단순히 이 A, B가 다음문장이냐 아니냐 이진분류(IsNext, NotNext)하는 task를 수행합니다.

위 지문은 BERT의 논문의 일부에서 가져왔습니다. 콤마와 마침표로 sentence가 나누어진다고 가정하고 IsNext, NotNext를 분류하는 task를 아래 예시로 들겠습니다.
- IsNext
- Sentence A: We argue that current techniques restrict the power of the pre-trained representations
- Sentence B: especially for the fine-tuning approaches.
- NotNext
- Sentence A: We argue that current techniques restrict the power of the pre-trained representations
- Sentence B: The major limitation is that standard language models are unidirectional
BERT에서는 50%는 바로 다음문장(IsNext), 50%는 다음문장이 아닌 랜덤 한 sentence(NotNext)로 구성하여 학습하였습니다. 위에서 말씀드린 [CLS] 토큰을 기억하시나요? pre-training시에 바로 여기서 이게 IsNext인지 NotNext인지 분류하는 것입니다. 아주 심플한데도 불구하고 NLI 나 Q & A에서 좋은 성능을 보였습니다.
3.3. Pre-training data
BERT에서 Pre-training data는 실제 존재하는 literature인 BooksCorpus(800M word), Engloish WIkipedia(2,500M words)르 사용하였습니다. BERT에서 사용한 기술들에 의해 document-level corpus를 사용하는 것이 연속되는 긴 sequences를 학습하기에 좋아서 사용하였습니다.
4. Fine-tuning BERT
BERT는 Transformer의 encoder를 사용하고 fine-tuning과정은 아주 간단합니다. 각 task마다 input, output이 약간 다르다는 차이점밖에 없고, architecture를 바꾸고 붙이는 것이 아니기 때문에 end-to-end 학습이 가능합니다. pre-training에 거쳐 적은 parameter로 학습이 가능하고 학습 시간도 대부분 1시간 이내에서 그쳤다고 합니다. 아래는 각 task에 대한 큰 그림입니다.
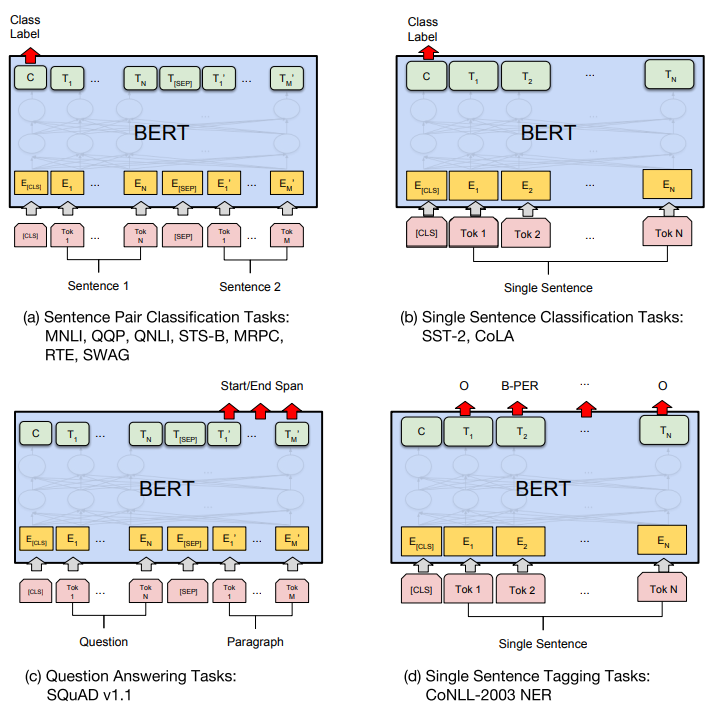
- (a), (b)는 sentence사이에 [SEP] 구분자 토큰을 주어 한번에 삽입하는 sequence-level task
- (c), (d)는 하나의 sentence가 삽입되어 sentence사이의 token들의 관계를 분석하는 token-level task
각 task마다 마지막에 output형식이 다릅니다. 그러므로 추가적인 output layer하나를 삽입하여 각 task-specific model을 만들기 때문에 최소한의 parameter가 드는 겁니다. 각 task-specific model에 대한 설명과 결과는 아래 Experiments에서 다루겠습니다.
Experiments
이 섹션에서는 BERT가 11개의 NLP tasks에서 fine-tuning 한 결과를 볼 것입니다.
1. GLUE
General Language Understanding Evaluation (GLUE)는 위 Fine-tuning BERT에서 (a), (b) 번째에 해당되는 task입니다. 다양한 natural language 이해에 대한 task입니다. input sequence(single sentence or sentence pairs)가 입력으로 들어가면 처음의 [CLS] 토큰이 마지막 hidden vector \( C ∈ \mathbb {R}^H \)가 출력됩니다. 여기서 GLUE task에 맞게 classification layer weights \( W ∈ \mathbb {R}^{K_XH} \)를 곱하여 softmax로 각 labels의 확률값을 구합니다 i.e., \(log(sortmax(CW^T)) \).
*\( K \): labels의 수
GLUE task에 하이퍼파라미터는 batch size 32, epoch 3으로 지정되었습니다. \( BERT_{LARGE} \)는 작은 데이터셋에서는 때때로 불안정한 결과를 보였습니다. 아래는 얼마나 BERT가 대단한지 여러 task에서 평가하는 테이블입니다.
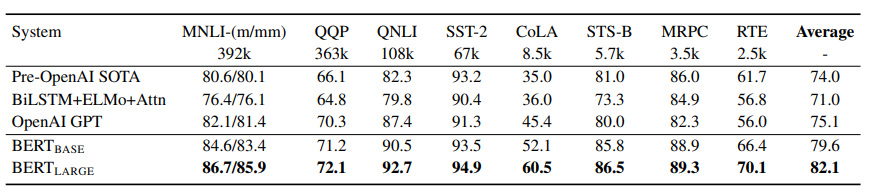
single sentence(a)와 sentence pairs(b) 각 두 가지 종류를 데이터셋 예시를 들어 설명하겠습니다.
QQP
Quora Question Pairs(QQP)는 이진 분류 task입니다. 두가지 질문 즉 두가지 sentence가 입력되며 의미적으로 동일한지 아닌지를 결정합니다.

CoLA
The Corpus of Linguistic Acceptability(CoLA)는 이진 분류 task입니다. 한 가지 sentence가 입력되며 영어가 문법적으로 옳은지 아닌지를 분류합니다.

2. SQuAD v1.1
The Stanford Question Answering Dataset(SQuAD)는 위 Fine-tuning BERT에서 (c) 번째에 해당되는 task이고, Wikipedia의 지문, 질문, 정답을 활용한 데이터셋입니다. (c)의 그림을 보시면 두 개의 sentence가 입력으로 주어집니다. 여기서 sentence들은 각각 지문과 질문이고 output으로 정답이 출력되며, 지문이 주어지고 질문을 하면 지문 안의 정답을 찾는 문제입니다.
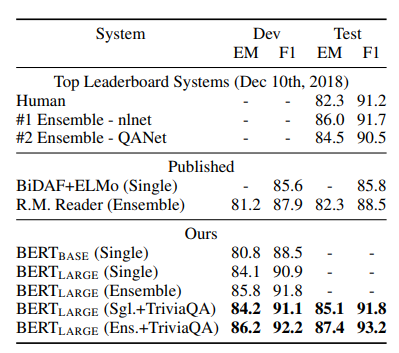
- 질문을 A embedding, 지문을 B embedding으로 처리하고, 지문에서 정답이 되는 substring의 처음과 끝을 찾는 task
- 지문에서 정답이 되는 substring의 시작 부분인 start vector를 \( S ∈ \mathbb {R}^H \) 모든 Token들과 dot product를 계산하여 소프트맥스로 구함
- 지문에서 정답이 되는 substring의 마지막 부분 end vector를 \( E ∈ \mathbb {R}^H \) 라 하고 위와 동일한 방식으로 구함
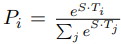

Ablation Studies
BERT가 왜 중요한지 ablation experiment를 통해 증명하는 섹션입니다.
5.1 Effect of Pre-training Tasks
아까 BERT의 pre-training 기술인 maskedLM(MLM), Next Sentence Prediction(NSP)의 중요성을 알기 위해 ablation 하면서 성능비교를 합니다.
- NO NSP: MLM은 사용하지만, NSP를 없앤 모델
- LTR & No NSP: MLM 대신 Left-to-Right(LTR)을 사용하고, NSP도 없앤 모델 (GPT-1가 같은 모델이지만 dataset을 늘림)
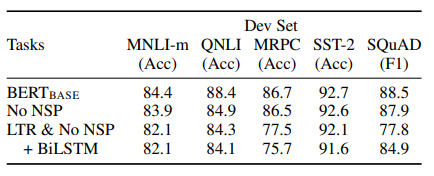
확실히 하나씩 제거하였을 때 성능이 모두 저하된 것을 볼 수 있습니다. 특히, QNLI과 같은 NLI에서 많은 성능 하락을 하였는데 이것은 NSP가 문장 간의 구조 학습에 중요한 역할을 하고 있음을 알 수 있습니다. 아울러 MLM 대신 Left-To-Right(LTR)을 쓰면 성능이 대폭 하락했습니다.
BiLSTM을 붙이면 SQuAD 같은 경우에 LTR보다는 성능이 올라갔지만 LTR, RTL 두 개의 모델 concatenation 하기 때문에 기존 BERT보다 2배나 더 많은 파라미터가 필요로 할뿐더러 성능도 기존 BERT보다 좋지는 않습니다.
위와 같은 이유로 BERT가 기존모델보다 훨씬 우월한 것을 볼 수 있습니다.
5.2 Effect of Model Size
이 섹션에선 layers, hidden units, and attention heads 수를 변경하면서 하이퍼파라미터가 얼마나 성능에 영향을 미치는지 확인합니다.
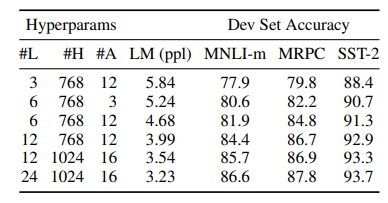
하이퍼파라미터의 수치가 높아질수록 성능도 올라가는 건 예전부터 증명되었습니다. 아울러 BERT는 충분히 잘 pre-training 되어 있으면 아주 작은 데이터셋에도 큰 효과를 기대할 수 있다는 점입니다.
5.3 Feature-based Approach with BERT
위 pre-training 방식은 pre-train후 task에 맞게 1개의 classification layer를 추가하여 분류를 하였습니다. 그러나 feature-based approach는 pretrained model에서 고정된 feature가 추출하는 방식(ELMo)이고 나름대로 fine-tuning보다 이점이 있습니다.
- Transformer Encoder 가 모든 NLP에 쉽게 representation을 학습할 수 있는 것은 아니므로 특정 task마다 architecture를 추가해야 할 수도 있습니다.
- 처음에 좀 많은 양의 representation을 pre-trainig 한다면 다른 task를 적용할 때 계산량에 benefit을 얻을 수 있습니다.
Conclusion
기존 ELMo와 GPT의 pre-training 모델도 있었지만, 그것들의 장점만 결합한 모델이라고 봐도 과언이 아닌 것 같습니다. 이미 많은 실험으로 입증이 되었고, 기존 undirectional 한 모델에서 약간의 변화로 작은 resource로 bidirectional 하게 만든 것이 놀라울 따름입니다. 현재도 많이 인용되고 있는 것으로 알고 있습니다. 다음은 이 pre-training이 vision 분야에서도 활발하게 이루어지고 있는데, 그러한 논문으로 찾아뵙겠습니다.
긴 글 읽어주셔서 감사합니다.
Reference
'NLP' 카테고리의 다른 글
| [논문리뷰] GPT-1(Improving Language Understandingby Generative Pre-Training)의 이해 (0) | 2023.06.13 |
|---|---|
| [논문리뷰] ELMo(Deep contextualized word representations)의 이해 (0) | 2023.06.12 |
| [논문리뷰] Attention is All you need의 이해 (4) | 2023.06.06 |



댓글