Abstract
Deep Contextualized Word Representations
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol
aclanthology.org
이 논문은 제목 그대로 Deep contextualized word representations을 학습하여 적용시키는 것입니다. 각 단어마다의 복잡한 특성과 문법적 이해를 언어적 맥락에 따른 단어를 학습합니다.
She’s wearing a dress like mine
Do you like their new house?
위 두 문장을 확인해 봅시다. 둘 다 같은 like가 쓰였지만 위는 전치사, 아래는 동사의 의미적으로 다른 것을 확인할 수 있습니다. 이러한 단어가 기존에는 똑같이 임베딩되어 여러 이슈가 있었다고 합니다. ELMo는 Embedding from language model의 약자로 이름에서 알수있듯이 본 논문에서는 문맥에 따라 같은 단어라도 다르게 임베딩을 주어 학습하여야 한다고 제시하고 있습니다. 문맥을 학습하기 위해 양자(bidrectinal)의 방법으로 문장을 left-to-right, right-to-left 둘다학습하는 bidirectional language model(biLM)의 방법을 제시합니다. 이러한 모델로 unlabeling 된 상당한 양의 text corpus를 pretrain 하고 task에 맞게 labeling 된 text corpus를 downstream model에 학습시켜 주는 방법인 semi-supervision을 NLP에서 사용한 논문입니다. 이러한 방법은 question answering, textual entailment, sentiment analysis등 6개의 task에서 state of the art의 성능을 보였습니다.
Introduce
기존 NLP에서 Pre-trained model이 word representations을 학습하는데 좋은 결과를 나타내고 있었지만 high quality representations을 학습하는 데는 아직까지 연구되어야 될 분야였습니다. 위에서 설명했듯이 기존 방식은 같은 단어를 같이 임베딩하여 학습하였기 때문에 복잡한 언어의 특성(syntax and semantics), 언어적 맥락(polysemy) 두가지가 풀어야 될 문제였습니다. 본 논문은 이 두 가지 문제를 직관적으로 해결하고 state of the art의 성능에 도달했습니다.
ELMo는 기존 각 단어별로 임베딩을 한 것이 아니라 large text corpus로 bidirectional LSTM(left-to-right, right-to-left) 두 가지 LSTM의 벡터들을 결합하여 더 deep 하게 문장단위로 임베딩을 하였다고 제시합니다. 한마디로 2가지 LSTM들이 앞뒤 문맥을 파악하고 같은 위치의 layer끼리 결합하겠다는 의미입니다. 이렇게 하면 기존보다 더 깊은 층으로 word representations을 풍부하게 학습할 수 있습니다.
LSTM의 낮은 단계의 layer(입력과 가까운 층)는 품사 등 문법 정보를, 높은 단계의 layer(출력과 가까운 층)는 문맥 정보를 학습하는 경향이 있고, layer에 weight를 두어 각 task에 맞춰서 적절히 학습이 가능합니다. 이렇게 임베딩한 방법이 20% 에러율을 낮췄다고 하네요. 이렇게 하여 deep representations이 성능향상에 도움이 되었다고 증명이 되었습니다.
ELMo: Embeddings from Language Models
기존 각 단어마다 동일한 임베딩이 아니라 ELMo는 sentence단위의 word representations이라고 설명하였습니다. 이 word representations을 학습하기 위해 Bidirectional LSTM을 사용하고 이것을 ELMo라 합니다. 이 ELMo를 downstream에 적용하고 어떻게 구성되어 있는지 아래에서 설명하겠습니다.
1. Bidirectional language models
bidirectional LSTM는 LSTM을 left-to-right, right-to-left 두 가지 부분을 결합하여 사용합니다. 아래는 기본 LSTM forward 모델의 예시입니다.

한 sentence가 있고 이것은 \( N \) 개의 token들로 나누어진다고 하면 ( \( t_1, t_2,..., t_N \) )가 나오고, 각각 현재 토큰을 기준으로 다음 토큰이 나올 확률을 예측하는 모델을 LSTM의 forward부분입니다.. 예컨대, Let's stick to라는 문장이 있으면 Let's라는 단어가 나왔을 때 다음 stick이 나올 확률, Let's stick이라는 단어들이 나왔을 때 to 가 나올 확률을 계산하면 아래와 같은 forward에 대한 식이 나옵니다.

마찬가지로 현재 토큰을 기준으로 이전 토큰을 예측하는 모델을 LSTM의 backward부분입니다..

본 논문에 목적은 두 forward와 backward의 각 파라미터를 별도로 유지하면서 두 log likelihood를 공통적으로 maximize 하는 것이기 때문에

*\(Θ_x \) = token representation, \(Θ_{LSTM} \) = LSTM layer , \(Θ_s \) = Softmax layer 각 파라미터들
이렇게 함으로써 두 파라미터가 서로 완전히 독립적이지 않고 weights들을 공유합니다.
2. ELMo
ELMo를 요약하자면 두 LSTM의 layer representations의 결합입니다. 각 토큰 \( t_k \)마다 L-layer biLM(2L)과 처음 token layer를 합치면 총 2L+1개의 representations이 나옵니다.

*\( j \) = layer index, \( k \) = token index
위의 모델을 downstream에 적용하기 전에 먼저 모든 layers를 하나의 vector로 압축시켜줘야 합니다. 기존 연구들은 심플하게 마지막 하나의 layer만 선택했고 k번째 token에서 마지막 L번째 레이어를 선택한 수식은 \( E(R_{k}) = h_{k, L}^{LM} \)입니다. 그럼 이제 여러 개 layer들을 압축한 수식은 다음과 같습니다.

아까 처음에 소개파트에서 낮은 단계의 layer(입력과 가까운 층)는 품사 등 문법 정보를, 높은 단계의 layer(출력과 가까운 층)는 문맥 정보를 학습한다고 하였습니다. 위에서 \( s*{task} \)는 이것을 학습하는 가중치로, softmax 가중치가 적용되며 모든 layer에 적용되는 값을 더하면 1이 됩니다.
\( γ^{task} \)는 전체 모델의 적용되는 scale로 최적화에 아주 중요한 역할을 한다고 제시합니다. 경우에 따라 가중치를 부여하기 전에 layer normalization을 적용하는 게 도움이 되기도 하였습니다. 아래는 lstm layer가 2층일 때 예시입니다.

3. Using biLMs for supervised NLP tasks
위에서 ELMo를 pretrain 하였으니 이제 task에 맞게 적용시켜 supervised architecture를 설계하면 됩니다. 방법은 아주 심플합니다. 1. biLM을 학습시켜 각 단어에 대한 layer representations를 저장하고, 우리의 2. downstream이 pretrain 된 모델의 선형결합을 학습하도록 합니다.
- pretrained 된 biLM의 weights를 고정한다.
- input text를 각 token에 대해 biLM을 거쳐 task에 맞게 \( ELMO_k^{task} \)를 뽑아낸다.
- input token \(x_k^{LM} \)과 \( ELMO_k^{task} \)을 결합하여 [\(x_k^{LM} \);\( ELMO_k^{task} \)] 형태의 input으로 Supervised task RNN모델에 넣어준다.
- SNLI(문장 간 논리관계 유추), SQuAD(질의응답)의 task에는 출력에도 \( ELMO_k^{task} \)를 두어 더 좋은 성능을 거둠
- dropout과 loss에 biLM의 weights \( w \)에 \( λ||w||_2^2 \)를 더하는 정규화 방법도 사용.
- inductive bias를 부과하여 모든 biLM layers에 평균에 근접하게 하기 위함(일반화 성능을 높이려고)
4. Pre-trained bidirectional language model architecture
본 논문에서는 L = 2 biLSTM을 사용하였고, dimension = 512이며 LSTM 첫 번째와 두 번째 레이어 사이에 residual connection로 연결합니다. 임베딩은 2048 character n-gram convolutional filters에 두 개의 highway layer를 사용하였고 512차원으로 projection 시켜주었습니다.
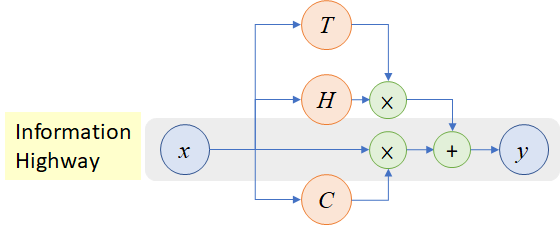
기존 임베딩 방법은 고정된 어휘 한 개의 representations을 생성하는 반면, biLM은 각 입력 token마다 순수 문자기반 입력 이기 때문에 3개의 representations을 생성합니다.
본 논문에서는 한 번의 pretrained으로 여러 task의 representations을 학습할 수 있고 특정 도메인별 데이터에서 biLM을 fine-tuning 하면 perplexity가 크게 감소하고, downstream의 성능이 향상됩니다.
Evaluation
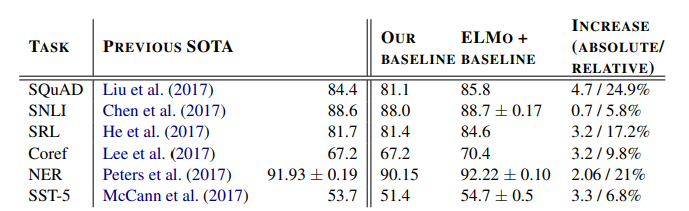
뒤 그림은 6개의 NLP task에서 ELMo를 사용했을 때 결과를 나타낸 것입니다. 모든 task에서 ELMo를 사용했을때 성능이 올라간 것을 볼 수 있습니다. 아래는 적용한 task에 대한 간단한 설명입니다.
- Question answering: 주어진 질문에 문장 안 올바른 정답을 출력. The Stanford Question Answering Dataset (SQuAD)에 서 100K+의 question-answer 데이터이고 위키피디아에서 가져옴.

- Textual entailment: 주어진 전제로 가설이 참인지 거짓인지 결정. The Stanford Natural Language Inference (SNLI)에서 550K의 가설/전제의 짝으로 구성.

- Semantic role labeling: semantic rol labeing(SRL)은 누가 언제 어디서 등 동사나 인수의 구조를 맞춤
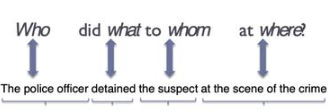
- Coreference resolution: 임의의 개체(entity)를 표현하는 다양한 명사구(mention) 들을 찾아 연결
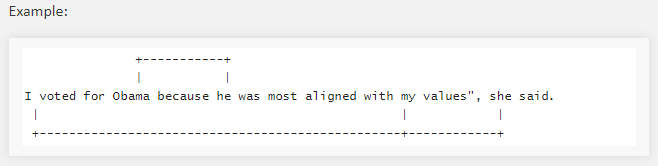
- Named entity extraction: 말 그대로 개채명 인식이고, 미리정의된 사용자 이름, 조직, 위치 및 기타 등 인식. The CoNLL 2003 NER은 Reuters RCV1에서 가져옴.

- Sentiment analysis: Stanford Sentiment Treebank(SST-5)에서의 감성 분류 작업. 문장을 보고 영화평점 1~5까지 분류.

Analysis
1. Alternate layer weighting schemes
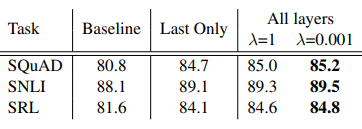
위 테이블은 SQuAD, SNLI, SRL 데이터 셋에서 기존 ELMo를 적용하는 식 전체 layer를 결한 하는 것과 마지막 layer에만 적용한 것, 기존 λ=1, 현재 λ=0.001을 비교한 것입니다. 전반적으로 향상된 결과를 보입니다.
2. Where to include ELMo?
본 논문에서는 모든 ELMo를 오직 input layer에만 적용하였습니다. 하지만 output layer에도 적용하였을 때 전반적으로 성능이 향상되었습니다. 아래는 input, output 둘다 적용하였을때 결과입니다.
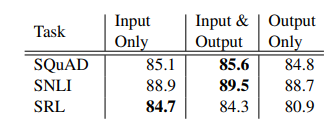
SQuAD, SNLI은 Input & Output 둘다 적용하였을때 성능이 가장 좋았고, SRL은 Input만 적용하였을때 성능이 좋았습니다. 여기서 SQuAD, SNLI은 biRNN이후 바로 attention layer를 사용하였기 때문에 이 layer에 ELMo를 추가하여 내부 representations에 직접 접근할 수 있도록 해주고, SRL의 경우 task-specific context representation이 biLM context representations 보다 더 중요하기 때문이라는 설명이 가능합니다.
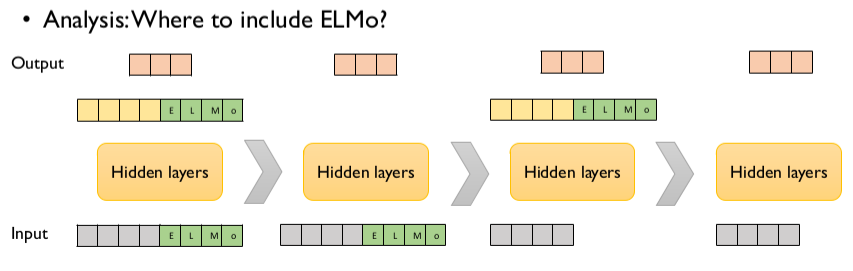
3. What information is captured by the biLM’s representations?
ELMo를 적용한 task에 향상된 성능을 보이면서 biLM이 contextual representations를 잘 학습하여 NLP task에 유용하다는 것이 증명되었습니다. biLM은 context로 word의 의미를 명확하게 해석합니다.
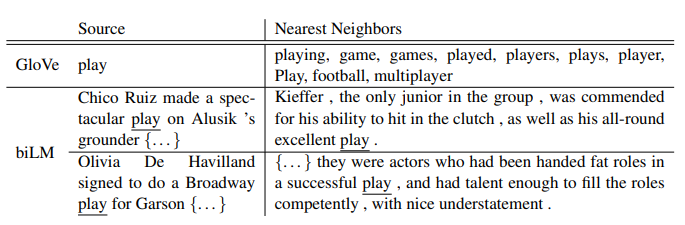
위 테이블의 첫 번째를 보면 기존에 사용하던 방법인 GloVe vector를 사용하여 "play" 근처의 리스트를 뽑아본 것입니다. 여러 부분에 분포하지만 스포츠 관련 의미에 집중되어 있습니다.
그러나 본 논문의 biLM에서는 "play"의 비슷한 의미로 쓰인 문장을 판단할 수 있습니다.
4. Sample efficiency
ELMo는 또한 샘플링의 효율성도 증가하였습니다. ELMo 없이 기존모델은 486 epochs에 최고 성능을 도달했다면, ELMo를 적용한 모델은 10 epochs에 최고 성능을 도달하였습니다. 또한 적은 train set으로도 ELMo를 적용한 모델이 좋은 성능을 도출하였습니다. 아래의 x축은 총 데이터세트의 percentage입니다.
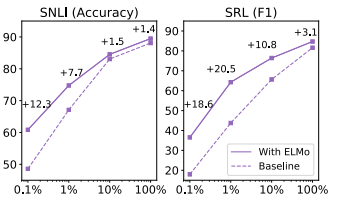
Conclusion
기존 word 단위가 아닌 context 단위로 임베딩을 한 ELMo를 적용한 것은 여러 가지 NLP task에서 큰 향상을 보였습니다. 여러가지 실험으로도 확인이 증명이 되었습니다. 현재 논문으로 여러 pretrained model이 파생되고 연구 중에 있습니다. 꼭 한번 읽어보시길 추천합니다.



댓글