소개
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
본 논문이 발표할 때까지만 해도 RNN이나 LSTM과 같은 Recurrent 한 구조나 Encoder-Decoder를 포함한 구조를 가진 모델들이 번역 모델에서 큰 성과를 내고 있었습니다. 하지만 이러한 모델들은 예전부터 큰 Memory와 Computation에서 많은 양을 요구하고 있고, 문장의 길이가 길어질수록 한계를 드러내고 있었습니다. 이 문제점을 해결할 방법이 필요했는데, 기존 Encoder-Decoder구조를 벗어난 Attention Mechanism만으로 구성된 Transformer 모델이 발표되면서 성능과 메모리 두 가지 측면에서 우세한 모델이 등장하게 됩니다. 현재 Transformer는 컴퓨터 비전분야에도 쓰이고 있으며 많은 변화를 가져온 모델이므로 꼭 한번 보시는 것을 추천드립니다.
Sequence Modeling
기존 저희가 잘 알고 있는 모델들은 RNN과 LSTM 등이 있습니다. 이 두 모델은 Transformer가 나오기 전까지 실제로 State-Of-The-Art의 성능을 보이고 있었습니다. 하지만 위에서 언급한 것처럼 Recurrent한 구조나 Encoder-Decoder 구조는 Memory와 Computation에서 많은 양을 요구하고 있어 한계를 드러내고 있습니다. 우리가 잘 알고 있는 RNN모델로 예시를 들겠습니다.

RNN 모델의 경우 이전 hidden state
Encoder에서 입력된 단어의 흐름을 순차적으로 입력받아 이 정보들을 하나의 벡터로 압축하는데 이것을 Context Vector라고 합니다. 이 압축된 Context Vector를 Decoder로 전송하여 번역된 단어를 한 개씩 순차적으로 출력하는 구조입니다.
하지면 시퀀스 길이마다 입력되어야 정보가 다르기 때문에 Context Vector의 크기는 가변적이어야 하는데, Context Vector의 크기는 고정된 크기이므로, Encoder에서 시퀀스의 정보를 압축하는 과정에서도 병목현상이 발생하여 성능 하락에 원인이 된다는 제한점이 있었습니다.
계속해서 이러한 성능과 계산의 효율성과 메모리에 대한 연구가 이루어지고 있었지만 근본적인 모델 구조에 대한 제약은 남아 있었지만 이 틀을 깨버린 것이 Transformer입니다. 기존 이전 Hidden State만 고려하는 Locality의 구조가 아니며 병목현상이 발생하지 않는 Attention Mechanism을 사용하여 Global 하게 전체 Sequence의 구조를 파악하여 Memory와 새로운 State-of-the-art의 성능을 내었습니다. 기존에 도달하지 못했던 모든 구조를 Attention으로 바꾼 것에 많은 혁신적인 성과를 이루어 내었습니다. 그럼 Model Architecture에 대해 천천히 살펴보겠습니다.
Model Architecture
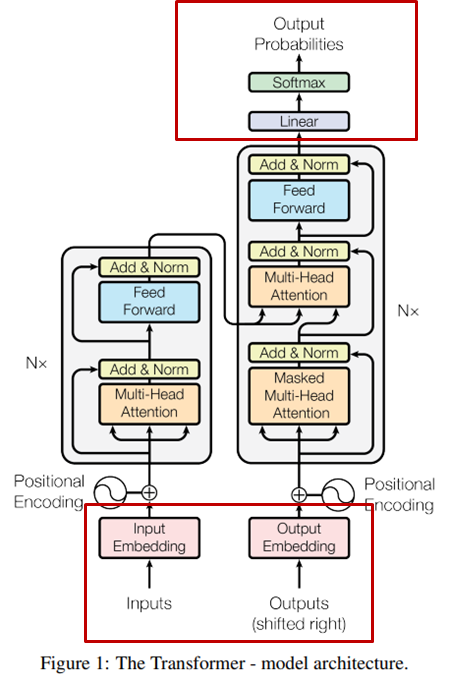
Transformer 모델이 나오기 전까지 Encoder-Decoder모델이 가장 큰 두각을 나타내고 있었습니다. Transformer 모델도 이 구조를 따라가지만 기존 Encoder-Decoder와 같이 병목현상은 생기지 않는 더 보완된 모델의 구조라고 보시면 됩니다. 아래는 모델의 전체 구조 도입니다.
왼쪽의 회색 큰 박스는 Encoder 오른쪽의 회색 큰 박스 Decoder의 구조이고, N개를 쌓아 올려 레이어층을 깊게 만드는 구조입니다. 각각 Input Embedding과 Positional Encoding을 거쳐 입력되며 Encoder, Decoder에 총 3가지 Attention 이 있습니다. 나중에 자세히 설명할 테니 지금은 가볍게 구조만 익히면 되겠습니다.
Encoder: 첫 번째 주황색 Sub-Layer는 Multi-Head Encoder Self-Attention, 파란색 Sub-Layer는 단순한 Feed-Forward입니다. 두 Sub-Layer 각각 Residual Connection을 사용하고 Layer Normalization을 사용합니다. N개의 동일한 층이 쌓이고 마지막 Layer가 Decoder의 Multi-Head Encoder-Decoder Attention으로 입력됩니다. 본 논문에서는 N=6으로 동일한 6개의 층을 쌓아 올렸고 출력 차원은 512로 설정하였습니다. 처음 Encoder에 입력부터 출력까지 총 512차원으로 고정됩니다.
Decoder: 첫 번째 주황색 Sub-Layer는 Masked Multi-Head Decoder Self-Attention, 두 번째 주황색 Sub-Layer는 Encoder에서의 출력으로 입력된 Multi-Head Encoder-Decoder Attention, 파란색 Sub-Layer는 마찬가지로 단순한 Feed-Forward이고 Residual Connection과 Layer Normalization으로 동일하게 구성됩니다.
어텐션(Attention)
이제 위에서 계속해서 언급했던 Attention이 무엇인지 살펴보겠습니다. Attention이란 같은 문장 내에서 단어들 간의 관계를 나타내며, 이 관계를 Query(Q), Key(K), Value(V) 3가지로 표현하여 하나의 출력결과를 내는 것입니다. 직관적으로 와닿지 않을 것이라 예시를 들겠습니다.
영어: I love her.
한국어: 나는 그녀를 사랑한다.
영어를 한국어로 번역하는 것으로 예시를 들면, 나는이라는 주체가 Query, 연관성을 찾는 대상인 (I, love, her)이 Key, Q와 K의 유사성을 계산하여 유사한 만큼의 Value값을 가져올 수 있습니다. 일반 딕셔너리는 일치하는 K값에 V값을 가져오는 것인데, Attention Mechanism은 Q, K의 유사한 만큼의 V를 가져온다고 보시면 될 것 같습니다. Q, K, V는 단순한 스칼라가 아니라 Vector이고, 출력도 마찬가지로 Vector입니다.
왼쪽 그림은 한 개의 Attention을 표현한 것이고, 이러한 Attention이 여러 개 모여서 만들어진 것이 오른쪽에 Multi-Head Attention입니다. 차근차근 설명해 보겠습니다.
Scaled Dot-Product Attention
Q, K, V로 Attention 값을 구하는 수식은 아래와 같습니다.
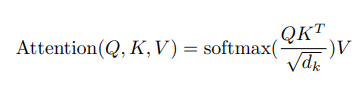
Q와 K로 Attention Score를 구하고 Q, K, V Dimension(
(I love her -> 나는 그녀를 사랑한다) 구조로 어떻게 Attention이 실행되는지 예시를 들겠습니다. Input Embedding의 차원이 5, 각 Head의 차원이 3이라고 하고 (예시를 위함이지 원래는 훨씬 많습니다.), 각각 (I, love, her), (나는, 그녀, 사랑)으로 Tokenize 된다고 가정해 보겠습니다.
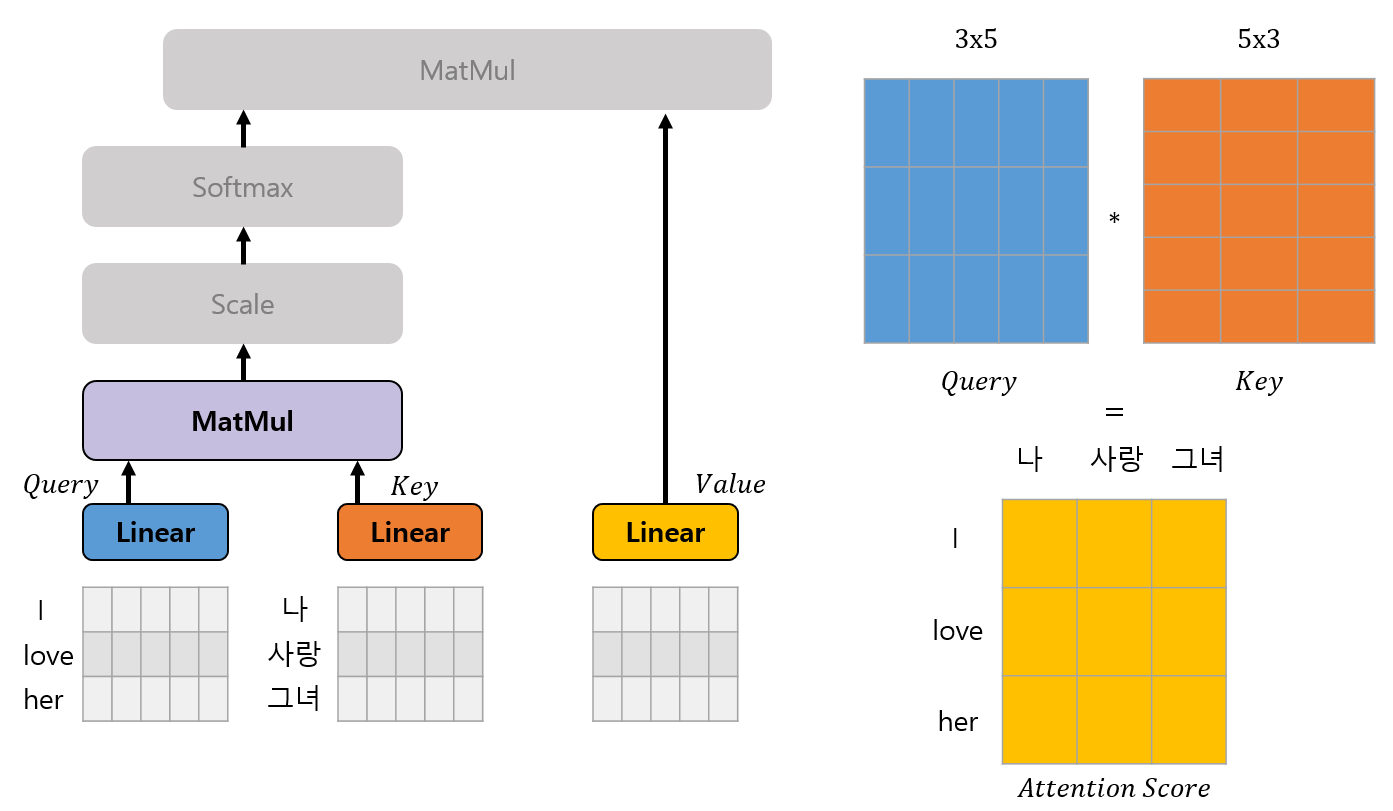
Linear 연산을 통해 위 그림과 같이 각각 Q, K, V를 얻게 됩니다. 그후 Q와 K의 내적으로 Attention Score를 얻게됩니다. 여기서 Attention Score는 두 단어들 간의 유사도를 의미합니다.
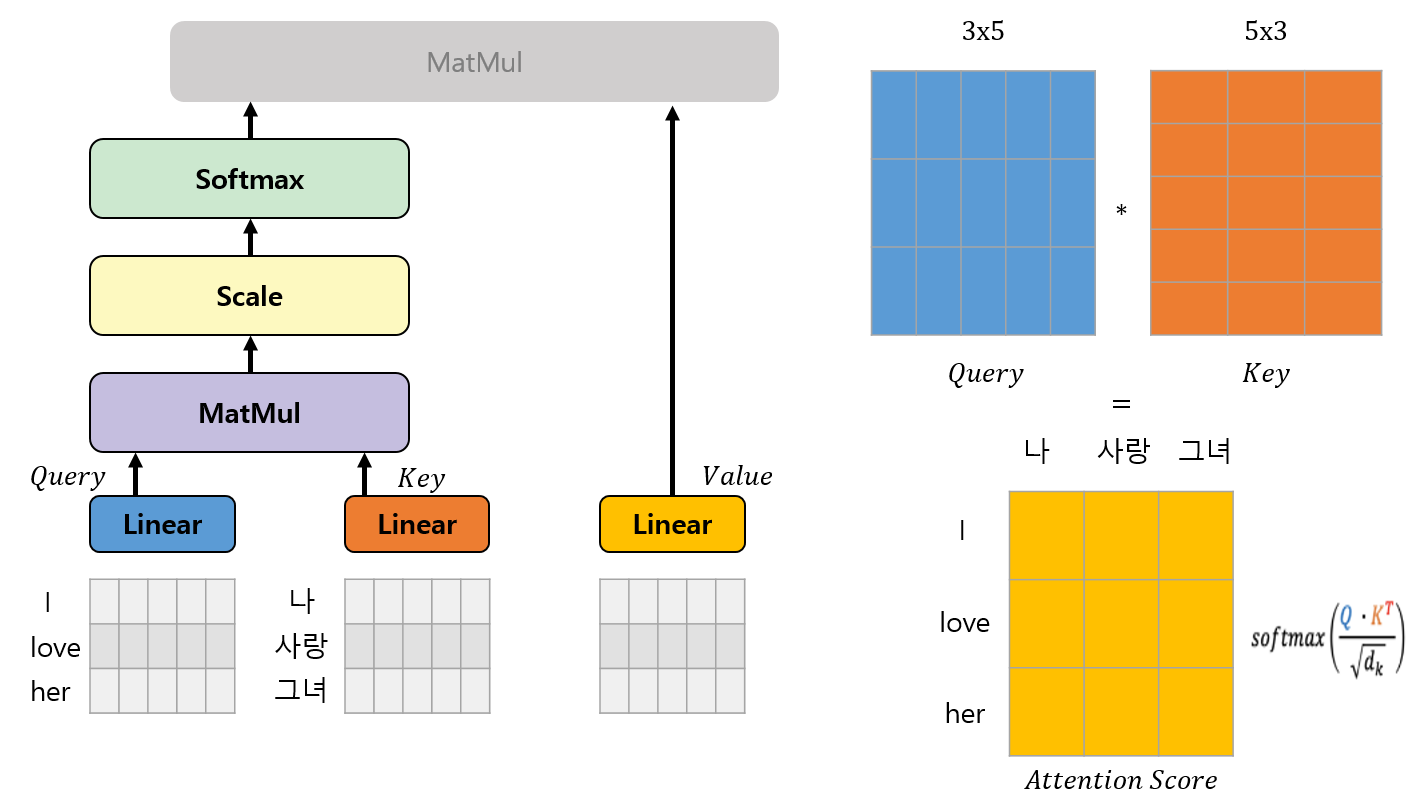
이후 Attention Score를
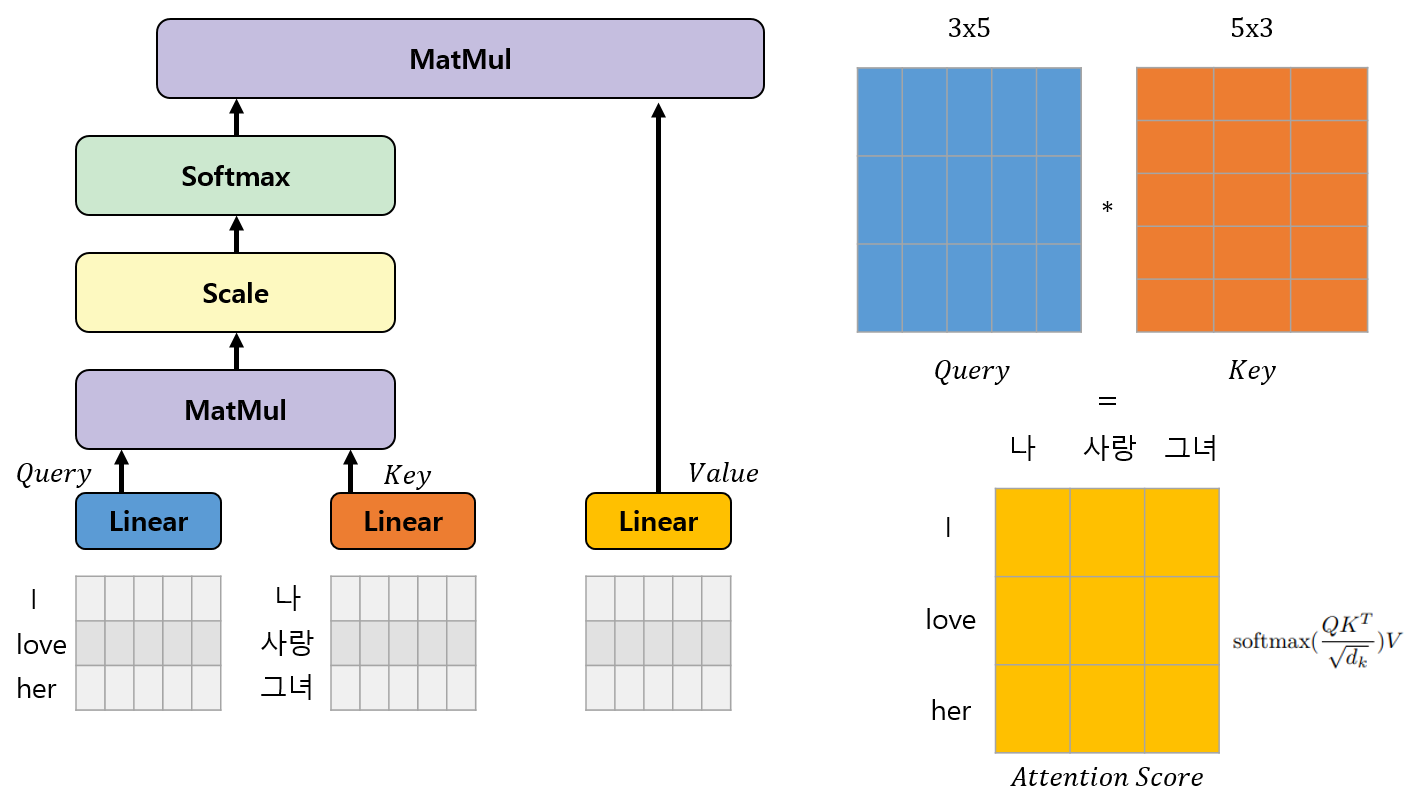
마지막으로 Softmax로 구한 확률값에 V값을 곱하여 Attention 과정을 마무리합니다. 하지만 Transformer는 이러한 Attention구조가 여러 개인 Multi-head Attention구조로 이루어져 있습니다.
Multi-Head Attention
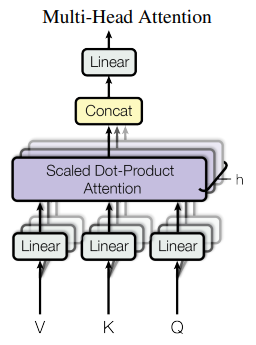
Input Embedding + Positional Encoding의 차원이 d라고 가정해 봅시다. Attention 구조를 한번 실행시켜도 되지만 굳이 h개로 나누어 d / h의 차원으로 쪼개 병렬연산하여 h개를 학습하고 다시 Concat 하고 Linear Layer에 입력이 되었습니다. 여기서 굳이 중간에 h개로 나눈 이유가 있을까 하는 의문점이 있습니다. 그냥 바로 forwarding 하면 안 되는 것일까?

본 논문에서는 여러 개로 나는 Multi-Head들이 서로 다른 Representation Subspaces를 학습하여 다양한 유형의 종속성을 가져 다양한 정보를 결합할 수 있다고 제시합니다.
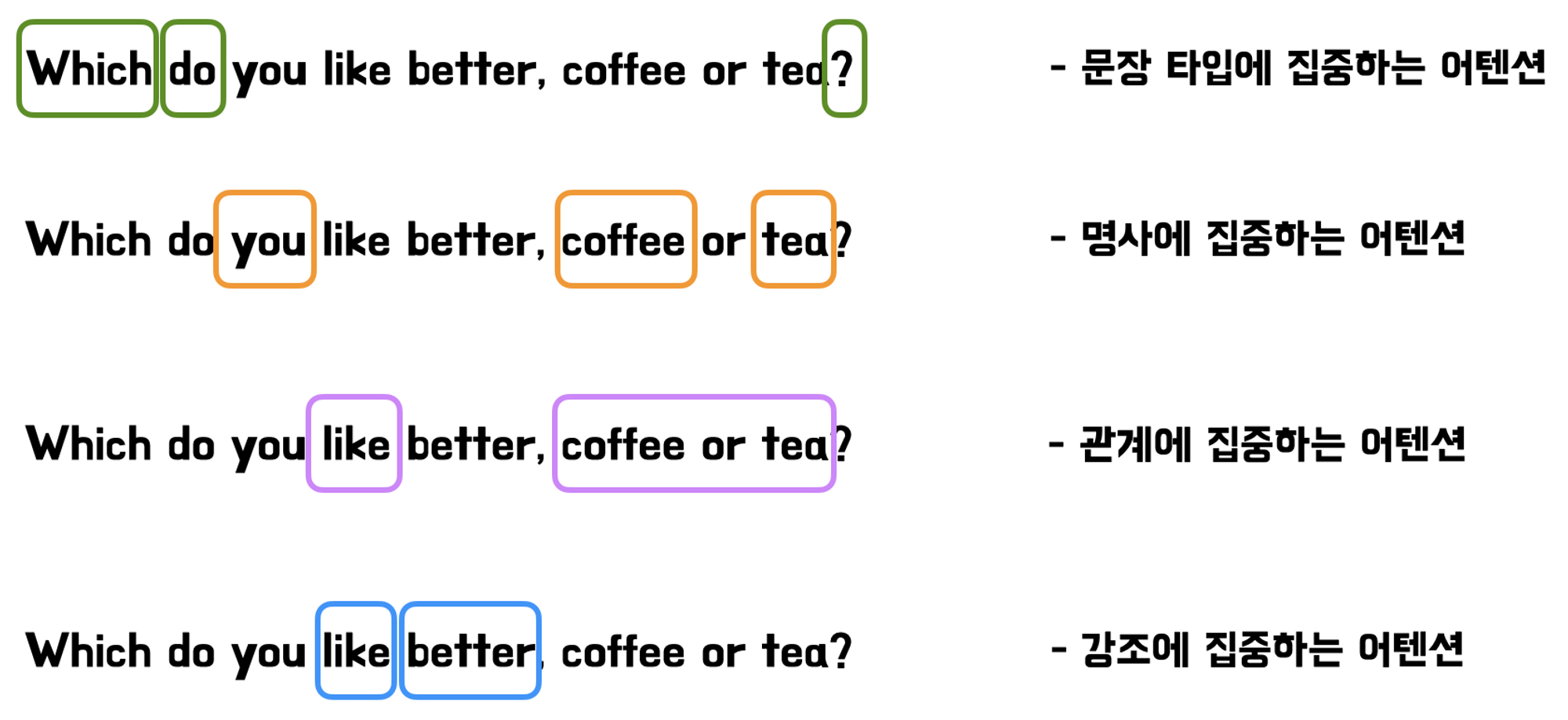
위 그림과 같이 서로 다른 head들이 서로 다른 어텐션을 가지는 방식으로 동작됩니다. 또, 원래 d차원을 h개로 쪼개 병렬연산 한 것이기 때문에 총 계산비용은 하나의 head를 사용했을 때와 동일하다고 합니다.
이제 Attention Mechanism에 대한 설명이 끝났고 위에 Transformer Architecture의 부분을 보시면 Attention이 Encoder-Decoder Attention, Encoder Self-Attention, Decoder Self-Attention 총 3가지 종류가 있고 모두 동작방식이 하나하나 다르기 때문에 동작 방식에 대한 설명을 하도록 하겠습니다.
어탠션(Attention)의 종류
- Encoder Self-Attention: Encoder에서 사용되는 self-attention은 Query, Key, Value 모두 Encoder로부터 가져옵니다. Encoder의 각 Layer들은 이전 Layer의 출력을 입력으로 받아 이전 Layer에 있는 모든 Position에 대응이 가능하고, 같은 Place의 Query마다 같은 Place의 Key, Value들로 Attention값을 구합니다. 예시를 들면 I love her이라는 문장에서 I 가 Query일 때 각 I, love, her 이 Key로 대응되고 마찬가지로 love, her이 Query일 때 각각 Attention값을 구합니다.
- Masked Decoder Self-Attention: 전반적인 목표는 Encoder와 같지만 Encoder는 입력이 Decoder는 출력값이 들어옵니다. Decoder에서는 Sequence model의 Auto-Regressive property 보존을 위해 이후에 나올 단어들은 참조하지 않습니다. 예시를 들면 Q=I, K=I, Q=love, K=[I, love], Q=you, K=[I, love, you]
(Decoder는 인코더와 달리 출력단이므로 이후 단어들을 참조하는 것은 정답을 알려주는 것과 같은 일종의 치팅)
또한, <PAD>와 같은 학습하고 싶지 않은 토큰 등이 있으면 유사도를 구하지 않도록 -∞ 로 세팅하여 마스킹(Masking)을 합니다. - Encoder-Decoder Attention: Encoder의 마지막 Layer층에서 출력된 Query, Key, Value 중 Key, Value만 사용하고 이전 Decoder에서 Query를 사용합니다. 이렇게 하면 Decoder의 Sequence들이 Encoder의 Sequence들과 어떠한 연관을 가지는지 학습합니다.
Position-wise Feed-Forward Networks
Encoder와 Decoder모두 attention의 sub-layers로 Fully Connected Feed-Forward network가 포함되어 있었습니다(위에 Transformer Architecture에서 파란색 부분입니다). 이 부분은 2개의 Linear Layer가 이어져있고, 사이에는 ReLU Activation을 사용하였습니다. 모델의 input과 output은 동일하게
Embeddings and Softmax
- 아래 빨간 부분에 Input Embedding과 Output Embedding은 Embedding layer를 거치고, 차원은
- 위 빨간 부분은 Decoder 단 출력에서 Linear transformation을 거치고, softmax function을 취해 다음 토큰들의 확률값을 계산합니다.
- 두 개의 임베딩은 Linear transformation으로 동일한 weight matrix를 공유합니다.
Positional Encoding
Transformer는 LSTM, RNN기반의 모델처럼 시간의 연속성을 다루지 않습니다. RNN기반 모델은 모델 구조자체가 이전 hidden state로부터 순차적인 정보와 입력데이터를 결합하여 출력을 산출하기 때문에 자동적으로 시간의 연속성을 보장하게 됩니다. 하지만 Transformer 모델은 Attention 함수 기반으로, Q를 기준 다른 K들의 연관성만 따지기 때문에 Sequence에 대한 정보가 존재하지 않습니다. 예컨대, I love her을 번역하는데 사랑해 그녀 나 이런 식으로 번역되는 것은 우리가 원하는 결과가 아닐 겁니다. 그래서 도입된 기술이 Positional Encoding인데 이 부분은 그렇게 어렵지 않습니다.
본 논문에서는 sin곡선의 상대적인 위치에 대한 정보를 Embedding과 동일한 차원에 위치시키는 것입니다. 간단하게 이야기하자면 Embedding 차원
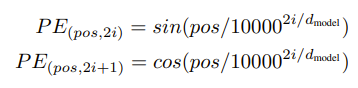
본 논문에서는 Sin함수를 사용하였고, 훈련 중에 더 긴 시퀀스 길이를 추정이 가능하여 선택했답니다(성능에는 별 차이가). 범위는 2π부터 2π * 10000까지,
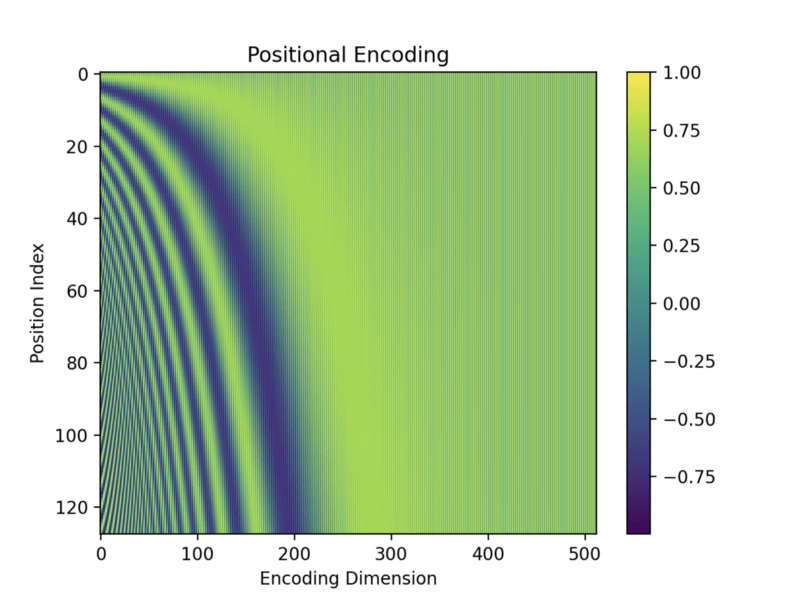
결론적으로 Input Embedding, Output Embedding에 위의 -1~1 사이의 값을 더해주는 것입니다.
Self-Attention을 사용한 이유
기존에 RNN, LSTM도 있고 Encoder-Decoder 구조인 seq2 seq도 있는데 왜 Self-Attention을 사용한 Transformer가 더 좋을까? 하는 의구심이 생깁니다. 이유를 총 3가지 나누어 설명하였습니다.

1. Total computational complexity per layer
CNN은 RNN보다 무조건 시간복잡도가 높기 때문에 RNN으로 비교를 하겠습니다. n이 d보다 작으면 Self-Attention이 n이 d보다 크면 RNN이 더 complexity가 낮아지게 됩니다. 하지만, 영어로 예를 들면 token 되는 개수가 8000개가 넘어갑니다. 그럼 이 많은 단어들을 representation dimension으로 표현하려면 256, 512,.. 등 높은 차원이 주어져야 continuous 하게 잘 표현이 됩니다. 보통 문장의 길이가 256, 512를 넘어가는 경우가 없기 때문에 Self-Attention이 complexity가 더 작다고 말할 수 있습니다.
2. The amount of computation
RNN의 경우 레이어마다 모든 토큰들이 input을 순차적으로 총 n개의 Sequence만큼 입력을 받아 O(n)를 가지지만 Self-Attention은 모든 potision들의 Attention Score값들을 한 번에 처리할 수 있기 때문에 사실상 O(1)을 가져 더 빠르게 parallel system에서 유리하게 적용됩니다.
3. Path length between long-range dependencies
long-range dependencies는 position 간 멀리 떨어져 있는 단어들 간의 의존성을 이야기하고 항상 challenge였습니다. RNN, LSTM 같은 구조들도 과거의 정보가 마지막까지 전달되지 못하는 현상이 일어났습니다.
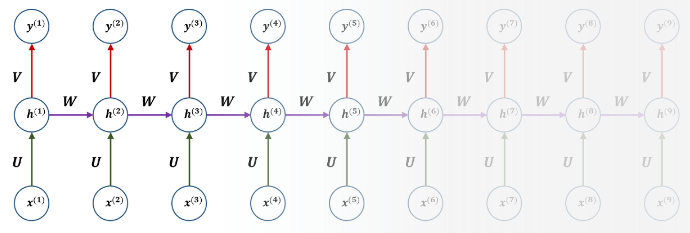
이러한 의존성을 학습하는 능력에 영향을 미치는 한 가지 핵심요소는 forward, backward signals 간의 path length입니다.Input sequence와 Output sequence의 이 path length가 짧을수록 long-range dependencies를 쉽게 학습할 수 있습니다. Input sequence와 Output sequence를 이어주는 징검다리(?)의 개수라고 생각하시면 편할 겁니다. 이 것의 최대 개수를 Maximum Path Length 라 하고 RNN은 한 토큰에 하나씩 layer가 붙어 총 O(n)의 길이이고, Transformer는 self-attention이 layer를 쌓아 올려 token끼리의 연산을 하는 것이 아니라, 하나의 self-attention의 각 토큰들이 모든 토큰들과 참조하여 연관성을 구하기 때문에 O(1)입니다.
결론
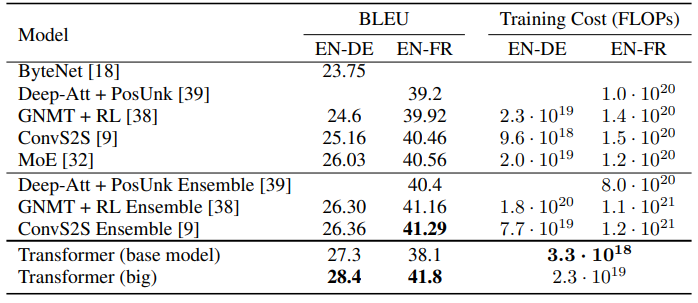
WMT 2014 English-to-German translation task, WMT 2014 English-to-French translation task에서 각각 최고의 성능을 내었으며 training cost 또한 가장 낮은 것을 볼 수 있습니다. 이것 말고도 다른 taks에서도 일반화가 잘 되었으며 좋은 성능을 보여주었습니다.
본 논문은 최초로 전체 구조를 attention으로 바꾼 Transformer모델을 제시하였습니다. 기존 RNN, Encoder-Decoder구조를 모두 Multi-Head Self-Attention으로 변경한 것이지요. Translation tasks에서 기존 모델들보다 상당히 빠르고 이전 최고의 모델을 능가하는 state of the art의 성능을 자랑하기도 하였습니다. 이 논문이 나왔을 때 아주 혁신적이며 미래에 attention-based models의 연구가 계속될 것이라고 주장하였습니다. 현재 이미 많은 파생연구가 진행 중이고 비전영역에도 사용되고 있습니다. 꼭 한 번은 읽어보시는 것을 추천드립니다.
긴 글 읽어주셔서 감사합니다.



댓글