들어가며
이 논문은 사전 학습된 비계층적 구조인 ViT를 백본으로, Object detection에 활용한 모델입니다. 논문의 핵심은 아래와 같습니다.
- Multi-Scale의 feature map으로부터 여러 계층 구조를 활용하는 FPN은 불필요하고, Single-scale의 feature map으로부터의 심플한 feature pyramid로 충분함
- Fine-Tuning의 과정에서 window attention을 사용하는데, cross-window는 모든 블럭에블록에 적용하지 않고, 아주 적은 블록에 적용하는 것만으로도 충분함(Swin 참고 링크).
- Pre-Training 과정에 ViT 백본은 Masked Autoencoders(MAE)로 사전 학습 되었음(MAE 참고 링크).
기존 Object Detection은 이미지 분류의 방대한 데이터로 사전 학습(Pre-training)된 백본에 상대적으로 적은 Object Detection 데이터를 활용을 위한 미세 조정(Fine-tuning)을 하는 구조입니다. 이때 Object Detection는 계층적인 구조를 가지고, 백본에 neck/head가 구성되면서 이 neck과 head의 디자인에 성능이 크게 좌지우지하였습니다.

"그런데 만약 기존 방법처럼 계층적인 구조가 아닌 비계층적 구조를 가지는 ViT와 같은 모델을 백본으로 가져가고, 뒤에 Neck/Head를 연결시켜서 Object Detection을 수행하는 건 어떨까?"
이것이 이 논문의 핵심입니다. 직관적으로 이 방법의 장점은 Pre-Trainig 할 때의 백본인 ViT와 Fine-Tuning 할 때의 Neck/Head와 따로 관리를 할 수 있다는 것입니다. 먼저, 이 ViT를 백본으로 사용할 때의 장점은 아래와 같습니다.
| CNN | Transformer | |
| Inductive bias | Inductive bias: locality, Translation invaiance | x |
| 장점 | 수렴이 빠르다. | 과적합에 민감하지 않다. |
| 단점 | 과적합에 민감하다. | 수렴이 느리다. |
Transformer는 Inductive bias가 없어, 위와 같이 수렴이 느리지만 과적합에 민감하지가 않습니다. 이 말은 데이터를 수용할 수 있는 용량이 크다는 말로 보아도 무방합니다. 그렇기 때문에 아래 그림과 같이 데이터가 많아질수록 CNN과 같은 모델은 빠르게 수렴하여 어느 정도 수준에서 성능 향상이 고정되지만, ViT의 경우에는 계속해서 성능이 올라가는 것을 볼 수 있습니다.

이러한 장점으로, Object detection에 필요한 방대한 데이터의 Translation-equivariant features와 Scale-equivaiant features를 supvised 또는 self-supervised의 사전 학습으로 이점을 누릴 수 있습니다. 한마디로 데이터를 많이 때려 박아서 많은 Features를 학습하겠다입니다. 이 사전학습의 방법으로는 self-supervised learning인 Masked Autoencoder(MAE)의 방법을 사용하였습니다.
이렇게 사전 학습이 잘된 백본에서 이제 Fine-Tuning을 할 때 features를 효과적으로 추출하기 위해 아주 약간의 구조의 변형이 들어갑니다.
- 기존 self-attention 방식을 window attention으로 변경
- 1/4 blocks에서만 cross-window를 진행(총 transformer encoder blocks이 24개라면 6 배수의 block에서만)
기존 window attention 방식을 사용하면, window 간에 상호작용할 cross-window 방식이 있어야 합니다. 하지만 본 논문에는 이것을 전체 다 하는 것이 아닌 1/4 정도만 진행한다고 합니다.
self-attention 방식에 window attention을 이용하고, 4개 정도의 blocks에서만 cross-window를 진행합니다. 이 방식은 global self-attention을 해주거나 컨볼루션으로 한다고 합니다(기존과 같이 shift 방식은 사용하지 않음).
이렇게 방대한 Features를 가지는 백본이 구성되었으니, 아래의 오른쪽 그림과 같이 Pre-trained ViT의 마지막 레이어의 feature map에 심플한 feature pyramid를 구성하는 것만으로 잘 Object detection을 수행할 수 있었다고 합니다(왼쪽 그림은 기존 방식).

위와 같은 이점을 활용하여, Multi-Scale 계층적인 구조를 사용하여 백본과 Detector를 통합하는 기존 구조와 달리, 백본과 Detector의 디자인을 분리시킬 수 있게 되었습니다. 이렇게 사전 학습된 백본의 디자인 변경 없이, Detection에서 수행되어야 할 특정한 사전 지식은 Fine-tuning 할 때만 약간의 변경이 이루어집니다.
Method
앞선 전술한 것처럼 핵심적인 기여는 계층적인 구조를 제외하고, Fine-tuning 동안 Object detection에 백본을 적용하기 위해 최소한의 수정하는 것입니다. 이후, Detection heads를 적용하여 물체를 감지하는 것이고, 새로운 무언가를 개발하기보다 새로운 Insight를 이끌어 내는 데 추첨을 두고 있습니다.
Simple feature pyramid
기존 FPN은 계층적인 구조로, 높은 차원의 features와 더 낮은 차원의 features를 결합함으로써 더 강력한 features를 제공하는 것입니다. 이는 아래 그림 (a)와 같이 top-down 방식과 lateral conntection으로 구성되어 있습니다.

본 논문은 이와 달리 가장 강력한 features를 가지는 오직 백본의 마지막 feature map만 활용하고, 이 1/16의 scale을 가지는 feature map에 convolutions과 deconvolutions으로 \( { \frac {1} {32} , \frac {1} {16} , \frac {1} {8} \frac {1} {4} } \)의 Scale을 가지는 Multi-Scale feature maps을 구성합니다. 이것을 "simple feature pyramid"라고 합니다.
기존 방법과 같이 latenral conntection이 필요 없고, 오로지 Deconvolution 만으로도 충분하다고 실험으로 입증했습니다. 이러한 이유는 위치 임베딩과, 보통 768 이상 고차원의 hidden dimension이 패치 임베딩이 정보를 보존하고 있기 때문이라 합니다. 그래서 위 (a), (b)와 같이 계층적인 구조를 흉내 내는 구조는 불필요하다고 합니다.
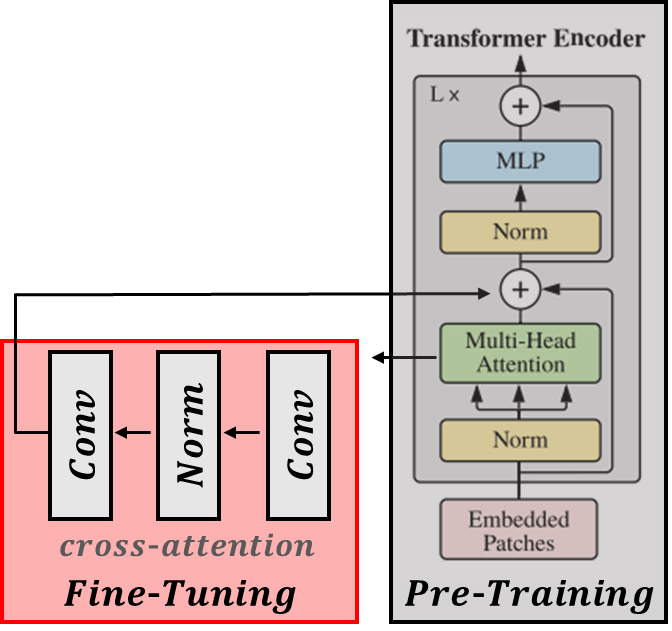
Backbone adaptation
Object detection에 고차원 이미지는 많은 성능 향상에 도움을 주겠지만, global self-attention을 수행하기엔 너무 오랜 시간이 걸리고, 그만큼 메모리 소비도 큽니다. 그래서 사전 학습된 백본에서만 global-attention을 수행합니다.
그래서, 고차원 이미지에 대한 Fine-Tuning을 할 때 window attention을 수행하는 것입니다. 단, 약간의 blocks에만 cross-attention을 수행합니다(보통 4개). 사전 학습된 백본의 레이어들을 균등하게 4등분 합니다(예를 들어 24개의 Blocks이면 각 부분집합은 6개의 Blocks로 구성). 각 부분집합의 마지막에 cross-attention을 수행하는 것입니다. 이러한 cross-attention 방식은 2가지 전략으로 나뉩니다.
- Global attention 방식: Window self-attention이 아닌, Global self-attention을 수행.
- 컨볼루션 방식: 각 부분집합 후에 여분의 Convolutional block을 추가. 하나 또는 이상의 Convolution을 구성하는 Residual block임(코드에서는 Attention 스코어 + Convolution). 이렇게 함으로써 사전학습된 백본의 초기 상태는 변경하지 않고, Fine-Tuning 할 Block을 추가할 수 있습니다.
위와 같이 기존 사전학습된 구조의 변경 없이, 아주 심플하게 기존 모델들을 구성할 수 있습니다. 이러한 방법으로 사전 학습과 미세 조정의 분리가 가능하고, 사전 학습에 ImageNet과 같은 Non-Detection 데이터를 활용한 Features가 기존에 부족한 Detection 학습 데이터의 공백을 메꿀 수 있습니다.
이러한 관점에서 볼 때 inductive biases가 적어 데이터 수용량이 큰 ViT에 아주 방대한 데이터를 Self-supervision으로 사전 학습시켜, 기존 CNN에서 가진 사전 지식(Scale equivariance, translation equivaiance)을 데이터로부터 이끌어낼 수 있다고 합니다.
그 후, Detection head를 추가하여 inductive biases가 작지만, 데이터를 때려 박은 Transformer가 CNN의 사전 지식을 이끌어 냈는지 확인해 보자는 것입니다.
위와 같이 부족한 inductive biases를 가진 Transformer가, 방대한 데이터로 CNN의 사전 지식을 습득한다면 아주 유의미한 연구가 진행될 것이라고 하네요.
Experiments
Feature pyramid
아래는 위에서 봤던 (a) FPN, 4-stage, (b) FPN, last-map, (c) simple feature pyramid에 대한 비교 실험입니다.

일단 pyramid 구조를 적용한 것이 안 한 것보다는 모두 성능 향상을 기록했습니다. 하지만 simple feature pyramid가 multi-scale feature를 적용한 것보다 성능이 잘 나왔죠? 그렇기 때문에 앞서 말한 것처럼 FPN의 구조가 필요 없다는 것입니다.
Window attention
아래는 백본에 적용한 각 Window attention 방식의 비교실험입니다.

모두 none이라고 표시된 것은 기본 ViT를 이야기합니다. (a)에서는 서로 다른 cross-window의 방식에 대한 성능 비교입니다. Backbone adaptation의 절에서 적용한 것은 conv block이고, 이 부분을 각각 global self-attention, shift self-attention을 적용한 것입니다. 모두 다 적용하지 않은 것보다는 성능 향상을 기록했지만, 그중 convolution을 적용한 방식이 가장 큰 성능을 기록했습니다.
(b)에는 cross-window로 구성한 Convolution을 basic(2개의 3*3), bottleneck(1*1 -> 3*3 -> 1*1), naive(3*3)의 각각 성능 비교입니다. basic 한 방법이 가장 큰 성능을 기록했네요.
(c)는 첫 4개의 blocks, 마지막 4개의 blocks, 균등하게 4개의 blocks에 cross-attnetion을 적용했을 때의 성능 비교입니다. evenly 4 blocks이 가장 좋은 성능을 기록했지만, last 4 blocks도 비슷한 성능을 기록하였습니다. 이의 결과로 ViT는 Block이 뒤로 갈수록 attention distance(맨 마지막 추가 자료)가 더 길어지고, 이전 block에서 더 로컬화된다고 설명합니다. 그래서 first 4 blocks은 성능에 크게 영향이 없습니다.
마지막으로 (d)는 이런 global attention를 적용할 block의 수에 대한 성능을 비교합니다. 24 blocks 모두 적용하는 게 가장 좋은 성능을 보였지만, 4 blocks을 적용했을 때와 0.5 정도의 차이밖에 나지 않습니다. 하지만 메모리 요구는 엄청 많이 듭니다. 그래서 4 blocks만 적용했을 때 더 나은 trade-off를 가진다고 볼 수 있죠. 아래가 이 trade-off에 대한 비교입니다.

메모리는 약 3배 정도, 시간은 약 1.5배 정도 더 걸리는데 성능은 0.5 정도밖에 증가하지 않았습니다.
Masked Autoencoders(MAE)
한마디로 정의하면 "MAE로 사전학습하는 것이 가장 좋다"입니다.

계층적인 구조들과 비교했을 때, 기존 방법은 지도 학습을 했는데 MAE는 label이 없는 self-supvised learning입니다. MAE가 지도 학습보다 성능이 잘 나온다는 건 MAE 논문에도 명시되어 있습니다.
이 밖에도 Object detection에서도 좋은 성능을 기록하였습니다.
자세한 내용은 본 논문을 참고하시고, 언제나 게시글에 대한 피드백은 환영입니다.
긴 글 읽어주셔서 감사합니다.
'컴퓨터비전 > Object Detection' 카테고리의 다른 글
| [논문 리뷰] Denoising DETR(DN-DETR) (0) | 2024.04.04 |
|---|---|
| [논문 리뷰] Conditional DETR (0) | 2024.03.29 |
| [논문 리뷰] Deformable DETR (0) | 2024.03.28 |
| [논문리뷰] DETR: End-to-End Object Detection with Transformer (0) | 2024.03.22 |
| [논문리뷰] Cascade R-CNN (0) | 2024.03.18 |




댓글