특징
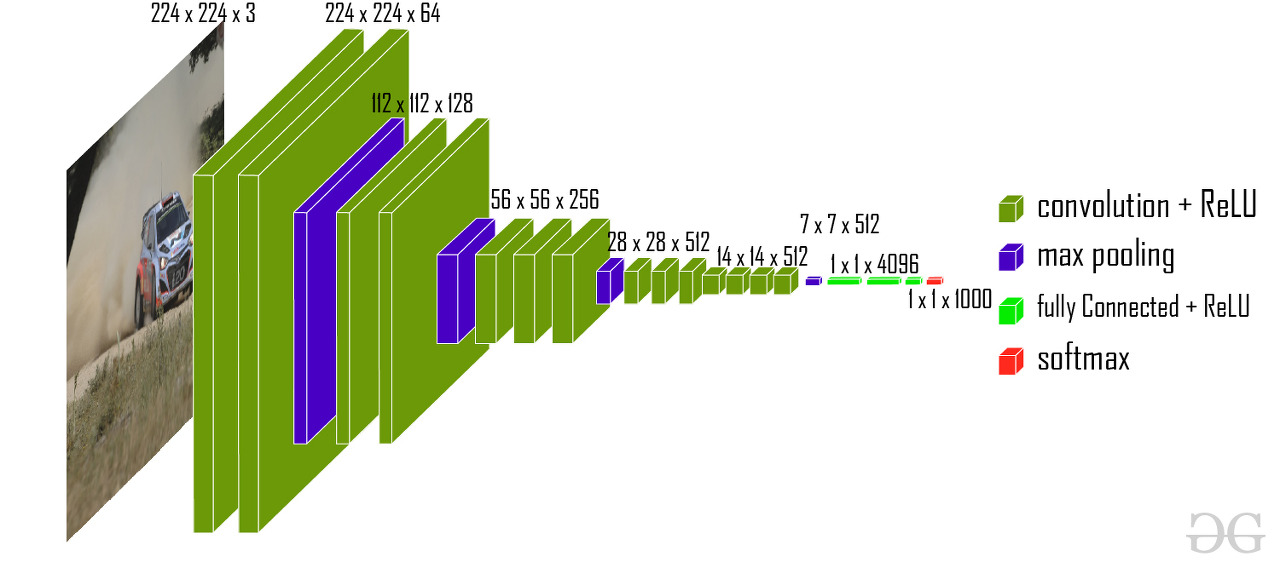

- VGG모델은 네트워크의 깊이와 모델 성능 영향에 집중한 것입니다.
- 커널 사이즈를 Alexnet과는 다르게 3 x 3으로 고정하였습니다, 그 이유는 커널 사이즈가 크면 이미지 사이즈 축소가 급격하게 이루어져 깊은 층 만들기가 어렵고, 파라미터 개수와 연산량이 많이 필요하기 때문입니다.
- 작은 필터를 사용함으로써 더 많은 ReLU함수를 사용할 수 있고 더 많은 비선형성 확보할 수 있었습니다.
AlexNet에서도 그랬듯이, 아래의 그림을 보면 깊이에 따라 모델 성능이 좋아짐을 알 수 있습니다.
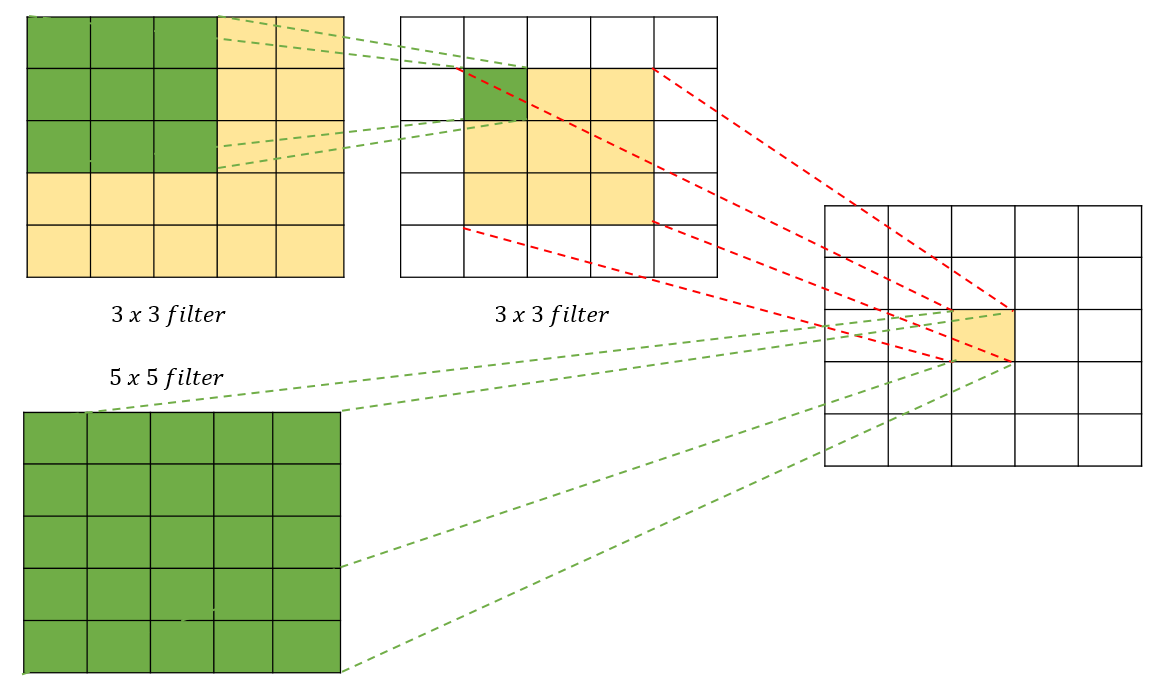
1. 위의 3x3 커널을 2개 적용한 경우 3x3x2 = 18 개
2. 5x5 커널을 1개 적용한 경우 5x5 = 25 개
그림을 보면 3x3을 2번 적용함으로써 2번 추상화 시킬수 있고, 최종으로 5x5의 추상화도 시킬 수 있습니다. 그리고 파라미터 수도 더 적습니다.
- AlexNet에서 11x11, 5x5와 같은 넓은 크기의 커널로 Convolutation연산을 적용하는 것보다 여러 개의 3x3 Convolution 연산을 수행하는 것이 더 뛰어난 Feature를 추출합니다.
- AlexNet 대비 더 많은 채널수와 깊은 Layer 구성
- 3x3 크기의 커널을 연속해서 Convolution 적용한 뒤에 Max Pooling 적용하여 Convolution Feature map Block을 생성
- Block 내에는 동일한 커널 크기와 Channel 개수를 적용하여 동일한 크기의 feature map들을 생성
- 이전 Block 내에 있는 Feature Map의 크기는 2배로 줄어들지만 채널은 2배로 늘어남
이제 코드로 구현을 해보겠습니다.
코드(Cifar10)
import numpy as np
import pandas as pd
import os
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
from tensorflow.keras import regularizers
from tensorflow.keras.applications.vgg16 import preprocess_input
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import Sequence
import cv2
import sklearn
class CIFAR_Dataset(Sequence):
def __init__(self, images_array, labels, batch_size=64, aug=None, shuffle=False, pre_func=None):
self.images_array = images_array
self.labels = labels
self.batch_size = batch_size
self.aug = aug
self.pre_func = pre_func
self.shuffle = shuffle
if self.shuffle:
self.on_epoch_end()
def __len__(self):
return len(self.labels) // self.batch_size
def __getitem__(self, index):
# 배치 사이즈 만큼 np.array를 가져옴
images_fetch = self.images_array[index*self.batch_size:(index+1)*self.batch_size]
# 훈련데이터인 경우
if self.labels is not None:
label_batch = self.labels[index*self.batch_size:(index+1)*self.batch_size]
# 배치 사이즈만큼 이미지를 담을 빈 공간을 만듬
image_batch = np.zeros((images_fetch.shape[0], 128, 128, 3))
for i in range(images_fetch.shape[0]):
# 이미지가 32 x 32 이므로 128, 128로 사이즈를 늘려줌
image = cv2.resize(images_fetch[i], (128, 128))
# augmentation이 있으면 적용
if self.aug is not None:
image = self.aug(image=image)['image']
# scaling이 있으면 적용
if self.pre_func is not None:
image = self.pre_func(image)
# 모두 적용한 데이터를 넣음
image_batch[i] = image
return image_batch, label_batch
def on_epoch_end(self):
if self.shuffle:
self.images_array, self.labels = sklearn.utils.shuffle(self.images_array, self.labels)
def create_vggnet(in_shape=(224, 224, 3), n_classes=10):
input_tensor = Input(shape=in_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_oh_labels = to_categorical(train_labels)
test_oh_labels = to_categorical(test_labels)
tr_images, val_images, tr_oh_labels, val_oh_labels = train_test_split(train_images, train_oh_labels, test_size=0.15)
tr_dataset = CIFAR_Dataset(tr_images, tr_oh_labels, batch_size=64, aug=None, shuffle=True, pre_func= preprocess_input)
val_dataset = CIFAR_Dataset(val_images, val_oh_labels, batch_size=64, aug=None, shuffle=False, pre_func= preprocess_input)
test_dataset = CIFAR_Dataset(test_images, test_oh_labels, batch_size=64, aug=None, shuffle=False, pre_func=preprocess_input)
model = create_vggnet(in_shape=(128, 128, 3), n_classes=10)
model.compile(optimizer=Adam(0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
learn_cb = ReduceLROnPlateau(monitor='val_loss', mode='min', factor=0.2, patience=5, verbose=1)
stop_cb = EarlyStopping(monitor='val_loss', mode='min', patience=5, verbose=1)
model.fit(tr_dataset, epochs=30, validation_data=val_dataset, callbacks=[learn_cb, stop_cb])
model.evaluate(test_dataset)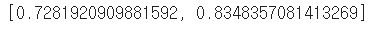
'컴퓨터비전 > CNN' 카테고리의 다른 글
| [딥러닝] ResNet 모델의 개요 및 특징 (0) | 2022.03.20 |
|---|---|
| [딥러닝] GoogLeNet(Inception) 모델의 개요 및 특징 (0) | 2022.03.17 |
| [딥러닝] AlexNet 모델의 개요 및 특징 (0) | 2022.03.17 |
| [딥러닝] Albumentations의 데이터 증강 이해 (2) | 2022.03.17 |
| [딥러닝] Kears의 전처리와 데이터 로딩의 이해 (0) | 2022.03.16 |




댓글