특징
AlexNet은 2012년 당시 오차율이 제일 낮은 모델로 우승한 모델입니다. 지금은 그렇게 좋은 모델은 아니지만 저 당시에는 굉장한 정확도였다고 합니다.
ReLU
- 이전에 보통 사용하던 뉴런 출력 함수는 주로
Overlapping
- MaxPooling으로 Overlapping Polling을 적용함,
Local Response Normalization(LRN)
- AlexNet에서 처음 도입되었습니다.
- 활성화 함수를 적용하기 전에 Noramlizatino을 적용하여 함수의 결괏값에서 더 좋은 일반화 결과를 도출했습니다.
- 이미지의 인접 화소들을 억제시키고 특징을 부각합니다.
Dropout
- 50% 확률을 Dropout을 적용하였습니다.
- 신경망 사이의 연결을 랜덤 하게 끊음으로써 Overfitting을 줄여줍니다.
Augmentation
- Data Augmentation적용(좌우, Crop, PCA 등등)
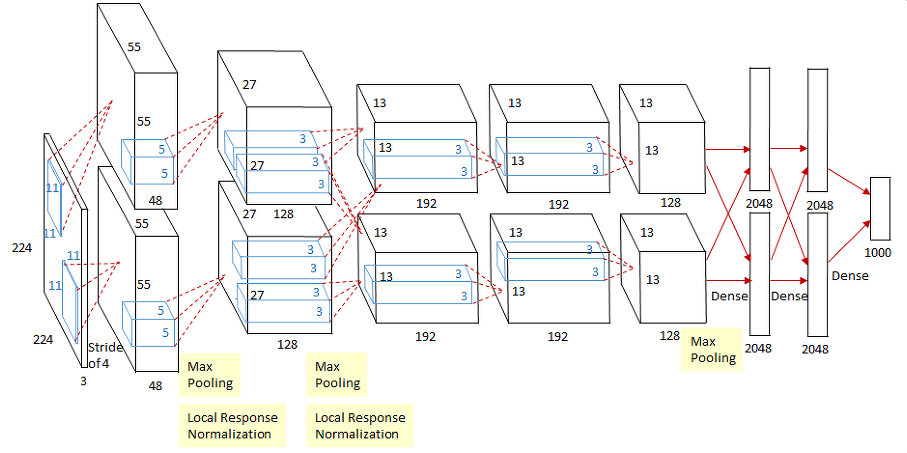
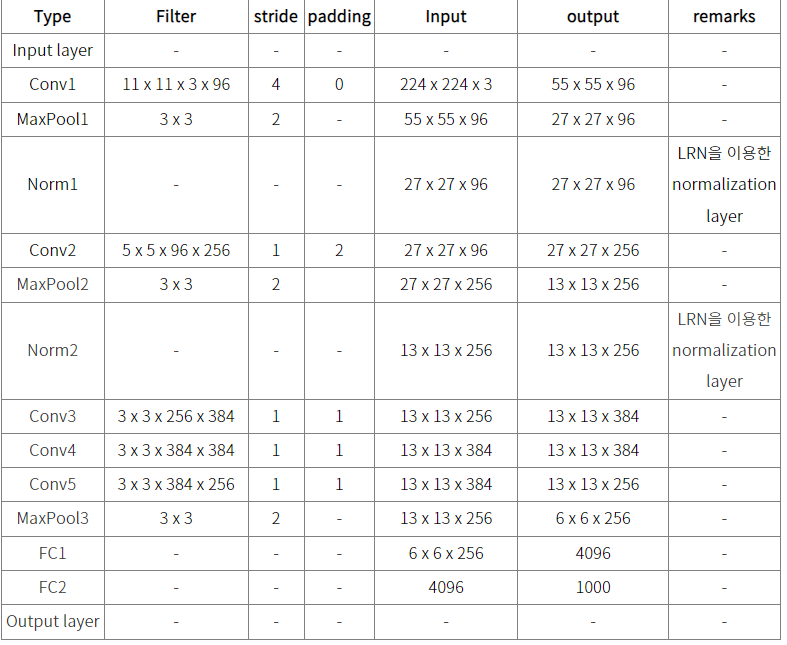
- 11x11, 5x5 사이즈의 큰 사이지의 커널을 적용하고, 이후 3x3 커널을 3번 연속 적용했습니다.
- 큰 사이즈를 초기 Feature map에 적용하는 것이 보다 많은 feature의 정보를 만드는데 효율적이라고 판단했습니다.
- 하지만 많은 가중치의 파라미터로 인해 컴퓨팅 연산이 크게 증가하고, 이를 극복하기 위해 GPU를 활용하여 병렬화 처리를 하였습니다.
자 이제 코드를 살펴보겠습니다.
코드
모델을 만들고, 모델에서 돌아갈 Sequence와 훈련 검증 데이터를 분리시킨 후 테스트 데이터로 검증하겠습니다.
import numpy as np
import pandas as pd
import os
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
from tensorflow.keras import regularizers
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import Sequence
import cv2
import sklearn
class CIFAR_Dataset(Sequence):
def __init__(self, images_array, labels, batch_size=64, aug=None, shuffle=False, pre_func=None):
self.images_array = images_array
self.labels = labels
self.batch_size = batch_size
self.aug = aug
self.pre_func = pre_func
self.shuffle = shuffle
if self.shuffle:
self.on_epoch_end()
def __len__(self):
return len(self.labels) // self.batch_size
def __getitem__(self, index):
# 배치 사이즈 만큼 np.array를 가져옴
images_fetch = self.images_array[index*self.batch_size:(index+1)*self.batch_size]
# 훈련데이터인 경우
if self.labels is not None:
label_batch = self.labels[index*self.batch_size:(index+1)*self.batch_size]
# 배치 사이즈만큼 이미지를 담을 빈 공간을 만듬
image_batch = np.zeros((images_fetch.shape[0], 128, 128, 3))
for i in range(images_fetch.shape[0]):
# 이미지가 32 x 32 이므로 128, 128로 사이즈를 늘려줌
image = cv2.resize(images_fetch[i], (128, 128))
# augmentation이 있으면 적용
if self.aug is not None:
image = self.aug(image=image)['image']
# scaling이 있으면 적용
if self.pre_func is not None:
image = self.pre_func(image)
# 모두 적용한 데이터를 넣음
image_batch[i] = image
return image_batch, label_batch
def on_epoch_end(self):
if self.shuffle:
self.images_array, self.labels = sklearn.utils.shuffle(self.images_array, self.labels)
# input shape, classes 개수, kernel_regularizer등을 인자로 가져감.
def create_alexnet(in_shape=(227, 227, 3), n_classes=10, kernel_regular=None):
# kernel_size를 매우 크게 가져감(11, 11)
input_tensor = Input(shape=in_shape)
x = Conv2D(filters= 96, kernel_size=(11,11), strides=(4,4), padding='valid')(input_tensor)
x = Activation('relu')(x)
# LRN을 대신하여 Batch Normalization 적용.
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
# 두번째 CNN->ReLU->MaxPool. kernel_size=(5, 5)
x = Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), padding='same',kernel_regularizer=kernel_regular)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
# 3x3 Conv 2번 연속 적용. filters는 384개
x = Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=kernel_regular)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=kernel_regular)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
# 3x3 Conv를 적용하되 filters 수를 줄이고 maxpooling을 적용
x = Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=kernel_regular)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
# Dense 연결을 위한 Flatten
x = Flatten()(x)
# Dense + Dropout을 연속 적용.
x = Dense(units = 4096, activation = 'relu')(x)
x = Dropout(0.5)(x)
x = Dense(units = 4096, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_oh_labels = to_categorical(train_labels)
test_oh_labels = to_categorical(test_labels)
tr_images, val_images, tr_oh_labels, val_oh_labels = train_test_split(train_images, train_oh_labels, test_size=0.15)
tr_dataset = CIFAR_Dataset(tr_images, tr_oh_labels, batch_size=64, aug=None, shuffle=True, pre_func= lambda x : x / 255.0)
val_dataset = CIFAR_Dataset(val_images, val_oh_labels, batch_size=64, aug=None, shuffle=False, pre_func= lambda x : x / 255.0)
test_dataset = CIFAR_Dataset(test_images, test_oh_labels, batch_size=64, aug=None, shuffle=False, pre_func=lambda x : x / 255.0)
# 이미지 사이즈가 너무 작으면 MaxPooling에서 오류가 발생함
model = create_alexnet(in_shape=(128, 128, 3), n_classes=10, kernel_regular=regularizers.l2(l2=1e-4))
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
learn_cb = ReduceLROnPlateau(monitor='val_loss', mode='min', factor=0.2, patience=5, verbose=1)
stop_cb = EarlyStopping(monitor='val_loss', mode='min', patience=5, verbose=1)
model.fit(tr_dataset, epochs=30, validation_data=val_dataset, callbacks=[learn_cb, stop_cb])
model.evaluate(test_dataset)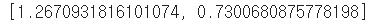
약 73%의 정확도가 나왔는데, 시간 관계상 EarlyStopping을 빨리 한 것이라 epoch를 더 수행하면 더 좋은 결과가 나올 것 같습니다.
'컴퓨터비전 > CNN' 카테고리의 다른 글
| [딥러닝] GoogLeNet(Inception) 모델의 개요 및 특징 (0) | 2022.03.17 |
|---|---|
| [딥러닝] VGG 모델의 개요 및 특징 (0) | 2022.03.17 |
| [딥러닝] Albumentations의 데이터 증강 이해 (2) | 2022.03.17 |
| [딥러닝] Kears의 전처리와 데이터 로딩의 이해 (0) | 2022.03.16 |
| [딥러닝] 전이 학습(Transfer Learning) (0) | 2022.03.15 |




댓글