Faster R-CNN
이전 포스트: https://lcyking.tistory.com/91
[딥러닝] Fast R-CNN 논문 리뷰
Fast R-CNN 이전 포스트 : https://lcyking.tistory.com/90 앞서 포스팅 한 것처럼 기존 R-CNN은 2000개의 이미지를 모두 CNN에 입력하고, 이미지 사이즈를 모두 같은 크기로 맞춰주는 문제점이 있었는데 이제 하
lcyking.tistory.com
개요
이전 포스트에서 Fast R-CNN은 Region Proposal 영역의 Selective Search는 GPU가 아닌 CPU로 돌아가 2.3초라는 시간이 걸렸습니다. 이것은 실시간에 적용하기에는 무리가 있습니다.
그래서 Faster R-CNN의 핵심 아이디어는 Region Proposal Network(RPN)입니다. 기존 Fast R-CNN의 구조의 Region Proposal 영역만 RPN으로 바꾼 것입니다. 이를 통해 GPU를 통한 RoI 계산이 가능해지고, RoI 학습시켜 정확도도 높일 수 있었습니다. 전체적인 동작 순서는 아래와 같습니다.
- 원본 이미지를 Pre-Trained된 CNN 모델에 feature map을 얻습니다.
- feature map은 RPN에 전달되어 적절한 Region Proposal을 얻어냅니다.
- Region Proposal을 feature map을 통해 ROI Pooling 하여 크기를 고정합니다.
- Classification과 Bounding Box Regression을 수행합니다.
아래는 Faster R-CNN의 구조입니다.


위 구조를 보시면 이제 Region Proposal 영역이 RPN으로 바뀐것을 볼 수 있습니다. Feature Map을 추출한 다음 RPN으로 던져주는 것을 볼 수 있습니다. 자 그럼 이제 RPN이 무엇인지 살펴보겠습니다.
Anchor Box
만약 Selective Search를 통해 영역을 추출하지 않을 경우, 원본 이미지를 일정 간격 Grid로 나누어 그 cell들을 Bounding Box로 간주하여 Feature Map에 적용해야 하는데 이미지마다 가까이있는 사물은 크게 보이고 멀리 있는 사물은 작게 보입니다. 그리고 차나 동물 사람마다 전부 크기가 다르므로 같은 Grid로 cell을 나누면 모든 사물에 대한 영역을 가져오지 못할 가능성이 높습니다. 그래서 고안한 방법이 Anchor Box 입니다.

위의 이미지와 같이 18 x 25 = 450개의 점이 모두 Anchor입니다.각 Anchor들의 좌표가 다 찍혔으니 이 좌표를 중심으로 여러 개의 Anchor Box를 생성할 것입니다.
- 표준길이: [64, 128, 256]
- 비율 →1:1, 1:2, 2:1
위와 같은 길이와 비율로 Anchor Box를 만들면 [64 x 64, 64 x 128, 128 x 64, 128 x 128, 128 x 256...]의 박스들이 Anchor의 중심으로부터 만들어집니다. 그럼 450개의 Anchor가 있으니까 450 x 9 = 4050개의 박스들이 만들어지겠네요. 하나의 좌표를 중심으로 예시를 들겠습니다.

위의 그림은 하나의 좌표에 박스들이 생긴 것이고 모든 좌표에 박스들이 생깁니다. 모든 좌표에 박스를 적용한 그림은 아래와 같습니다.

이 수많은 박스들이 Region Proposal들이고, 이제 학습을 해나아 가는 것입니다.
RPN(Region Proposal Network)

위는 Faster RCNN의 세부구조입니다. 이전에 말한 Anchor Box들로 수많은 Region Proposal들이 만들어졌습니다.
RPN의 세부구조를 보면
- 3x3 Convolution를 한번 더 해줍니다. padding은 same으로 주어 원래 Feature Map의 크기를 유지합니다.
- 1x1 Convolution연산을 각각 실행해주어 Classification과 Bounding Box Regression의 정보를 추출합니다.
- Classification에서는 박스가 오브젝트인가, 아닌가를 학습합니다. 즉, 물체가 있나 없나 만 판단 합니다. 2x9가 되도록 설정하여 Anchor box를 9개가 되도록 설정하였습니다.
- Bounding Box Regression 영역에서는 x1, y1, W, H의 정보들을 받아 원래 영역에 맞게 학습해 나아갑니다. 4x9가 되도록 설정하여 Anchor box를 9개가 되도록 설정하였습니다.

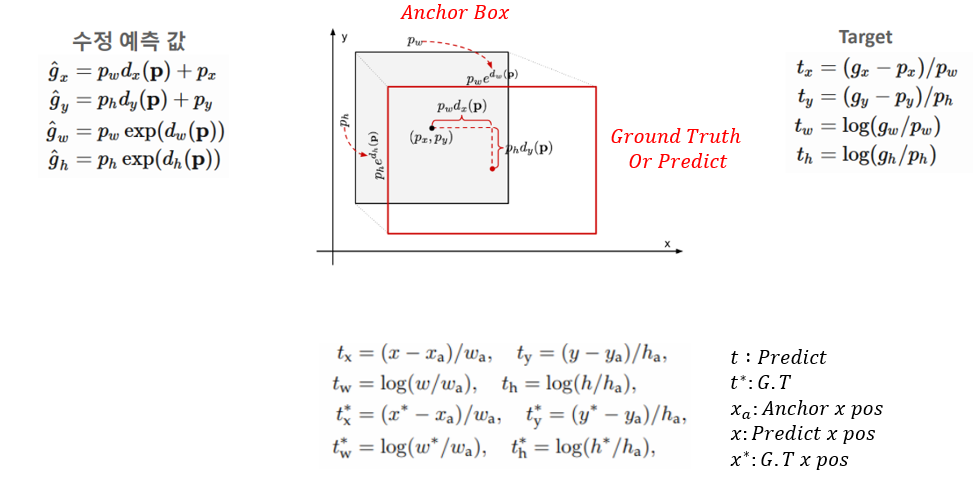
RPN Bounding Box Regression

Positive Anchor Box가 예측한 Bounding Box의 차이와 Ground Truth Box의 차이가 동일하면 같은 박스라 보는 식으로Anchor Box가 Predict BBox의 차이와 Ground Truth BBox의 차이가 동일하게 학습을 진행합니다.
Loss


학습
1) Pretrained 된 모델에 Feature Extration을 얻습니다.
2) 원본 이미지에 대한 Anchor Box를 생성합니다.
3) RPN의 Class Score와 Bounding Box Regression을 반환합니다.
4) NMS(Non Maximum Suppression)을 적용하여 겹치는 객체를 제거한 후, Class Score의 상위 N개의 Anchor Box를 추출합니다.
5) positive/negative 데이터를 sampling 해줍니다.

위 그림과 같이 한 가지 그림에 여러 개의 Anchor가 겹치는 경우도 있습니다.
- IOU가 가장 높은 Anchor Box는 Positive
- IOU가 0.7 이상이면 Positive
- IOU가 0.3 ~ 0.7이면 그냥 무시
- IOU가 0.3보다 낮으면 Negative(Background)로 학습합니다.
6) Pretrained 된 모델에서 얻은 Feature Map에 Anchor의 크기만큼 비율을 조정하여 RoI Pooling을 수행합니다.
전체 학습
- ImageNet Pretrained 된 모델을 불러와 RPN을 학습시킵니다. 이 과정에서 Pretrained 모델 역시 학습됩니다.
- Fast R-CNN을 학습시킵니다. Pretrained 모델 역시 학습됩니다.
- RPN에 해당하는 부분만 학습(fine tune)합니다. Fast R-CNN과 PreTrained 된 모델은 Freeze 합니다.
- Fast R-CNN을 학습(fine tune)합니다. RPN과 Pretrained 된 모델은 Freeze 합니다
'컴퓨터비전' 카테고리의 다른 글
| [논문리뷰] HOW MUCH POSITION INFORMATION DO CONVOLUTIONAL NEURAL NETWORKS ENCODE? (0) | 2024.01.19 |
|---|---|
| [논문리뷰] Masked Autoencoders(MAE) Are Scalable Vision Learners (0) | 2024.01.08 |
| [딥러닝] Fast R-CNN 논문 리뷰 (0) | 2022.03.23 |
| [딥러닝] SPPNet(Spatial Pyramid Pooling Network) 논문 리뷰 (0) | 2022.03.23 |
| [딥러닝] R-CNN 논문 리뷰 (0) | 2022.03.23 |




댓글