참고 자료
[논문리뷰] Attention is All you need의 이해
소개 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an atten
lcyking.tistory.com
[논문리뷰] BERT(Pre-training of Deep Bidirectional Transformers forLanguage Understanding)의 이해
Abstract unlabel 된 데이터를 pretrain 후, label 된 데이터를 task에 맞게 fine-tuning 해주면 성능이 더 좋아집니다.(OpenAI GPT, ELMo,...) ELMO와 같이 network를 left-to-right뿐만 아니라 right-to-left도 결합하여 unidirect
lcyking.tistory.com
Abstract
Transformer 구조는 NLP 분야에서 주목받고 있지만, 컴퓨터 비전 분야에서는 여전히 CNN이 주로 사용되었습니다. 이전까지는 Transformer를 컴퓨터 비전에 적용할 때, 전체적인 CNN 구조를 유지하면서 일부 컴포넌트만을 Transformer로 변형하는 경우가 대부분이었습니다. 전체 구조를 Transformer로 전환한 사례는 드물었습니다.
본 논문에서는 컴퓨터 비전 분야에 Transformer를 전면적으로 적용하는 새로운 접근 방식을 소개합니다. 이미지를 패치의 시퀀스로 변환하고 이를 Transformer 구조에 적용하여 이미지 분류 작업에 활용합니다. 방대한 양의 데이터로 사전 학습을 수행하고, 작은 크기의 이미지 인식 작업에 전이 학습을 적용했을 때 이 방법은 뛰어난 성능을 보여줍니다. 뿐만 아니라, 기존의 CNN 방식에 비해 훨씬 적은 계산 자원을 사용합니다.
이 논문은 컴퓨터 비전 분야에서 CNN 구조를 Transformer로 전환한 최초의 연구로, 이후의 많은 연구에 영향을 미치고 패러다임을 변화시키는 중요한 발판이 되었습니다.
Introduction
본 논문에서는 NLP 분야에서 널리 활용되고 있는 Transformer 구조를 이미지 인식 분야에 처음으로 적용한 접근 방식을 소개합니다. 이전에는 Transformer가 주로 대규모 데이터 세트를 사전 학습(pre-train)하는 데 사용되었고, 특정 작업에 대해 더 작은 데이터 세트로 미세 조정(fine-tune)하여 우수한 성능을 달성했습니다. 모델과 데이터 세트의 확장에 따라 성능이 지속적으로 향상되었습니다.
그러나 이러한 Transformer의 장점은 CNN에는 완전히 활용되지 못했습니다. 여전히 ResNet과 같은 CNN 기반 백본(backbone) 모델들이 이미지 인식 분야에서 최고의 성능(State-of-the-Art, Sota)을 보여주고 있었습니다.
본 논문은 이러한 한계를 극복하고자 이미지를 패치로 분할하고 이들을 선형 시퀀스로 변환하여 Transformer 구조에 입력하는 방법을 제안합니다. 이 방법은 이미지 패치들을 NLP에서의 토큰처럼 다루며, 이를 통해 이미지 분류 작업에 적용합니다.
그러나 ResNet과 같은 크기의 ImageNet 데이터 세트를 사용하여 학습했을 때, Transformer 기반 모델은 약간 떨어지는 성능을 보였습니다. 이는 CNN이 가지는 Translation equivariance와 locality 같은 본질적인 특성, 즉 inductive biases가 부족하기 때문으로 분석됩니다.
Inductive biases(귀납적 편향)
Inductive biases는 딥러닝 알고리즘의 일반화를 돕기 위해 추가적으로 가정하는 개념입니다. 모든 딥러닝 알고리즘에는 이러한 가정이 내재되어 있으며, 특히 CNN에는 Translation equivariance와 locality와 같은 중요한 가정들이 존재합니다. CNN은 k x k 크기의 필터를 사용하여 이미지의 국소적인 부분에 연산을 수행합니다. 이러한 연산 방식은 Locality의 개념을 반영하며, 이를 통해 이미지가 이동해도 같은 특징을 인식할 수 있는 Translation equivariance 특성을 가지게 됩니다.

Transformer 모델은 CNN과 달리 특정한 Inductive biases가 부족하기 때문에, 작은 데이터 세트를 사용했을 때 일반화 성능이 떨어질 수 있다고 알려져 있습니다.
그러나 대규모 데이터 세트(14M-300M images)에서 학습할 경우 상황이 달라집니다. 이 경우, Transformer는 CNN의 Inductive biases를 능가하는 성능을 보여줄 수 있음이 발견되었습니다. 반대로, 이와 같이 방대한 데이터를 CNN에 적용하려 할 때, CNN의 Locality 특성으로 인해 전체적인 Global context를 충분히 학습하는 데 한계가 있어, 데이터의 규모를 모델이 충분히 활용하는 데 어려움이 있을 수 있습니다.
이에 따라 본 논문은 대규모 데이터 세트로 사전 학습을 진행한 후, 특정 작업에 맞게 전이 학습을 하면 이미지 분류에도 Transformer 모델이 우수한 성능을 달성할 수 있음을 제시합니다.
Vision Transformer(ViT)
모델의 전체적인 구조는 아래와 같습니다.

전체 수식
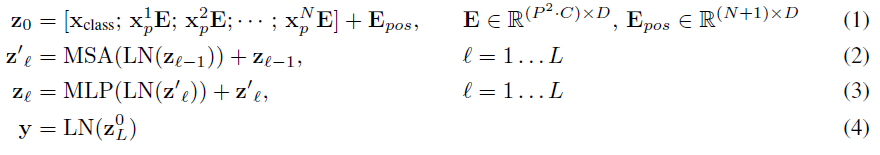
- 먼저, 클래스 임베딩과 패치 임베딩을 결합하고 평탄화(Flatten)한 후, Transformer 학습을 위해 이를 D차원으로 선형 투영(Linear projection)합니다. 이후, 위치 정보를 제공하기 위해 위치 임베딩(Position Embedding)을 추가합니다.
- 1단계에서 생성된 결과에 레이어 정규화(Layernorm)가 먼저 적용되고, 이어서 Multihead self-attention가 적용되고, 1단계에서의 결과에 residual connections이 적용됩니다.
- 2단계에서의 결과에 다시 레이어 정규화가 적용되며, MLP블록이 도입됩니다. 여기에도 마찬가지로 잔차 연결이 적용됩니다.
-> 위의 1-3단계 과정이 Encoder 레이어의 전체 개수(L)만큼 반복 적용됩니다. 이 모든 과정은 패치 임베딩을 제외하고는 기존 Transformer 모델과 동일합니다.
- 마지막으로, 출력된 패치 임베딩 중 0번째 인덱스(클래스 임베딩)에 레이어 정규화를 적용한 후, 예측될 클래스의 수만큼 Linear layer를 구성하여 최종적으로 이미지 분류 작업을 진행합니다.
Patch Embedding
본 논문에서는 표준 Transformer 모델의 접근 방식을 따르며, 이 모델은 원래 1차원 토큰 임베딩 시퀀스를 입력으로 받습니다. 이에 착안하여, 논문에서는 2차원 이미지를 Transformer 모델에 적용하기 위해 먼저 이미지를 2차원 패치들로 변환하는 방식을 제시합니다.

- (\(H, W\)) : 원래 이미지의 해상도
- \(C\) : 채널의 수
- (\(P, P\)) : 각 이미지 패치의 해상도
- \(N\) : 패치의 수 (\( HW / P^2 \))
Transformer 모델의 특징 중 하나는 모든 입력과 출력이 동일한 차원을 가진다는 것입니다. 이를 기반으로, 논문에서 제안된 방식은 2차원 이미지 패치들을 먼저 시퀀스 형태로 Flatten 하고, 이를 D차원으로 매핑합니다. 이 과정을 통해 생성된 D차원의 임베딩은 기존 Transformer에서 사용하는 학습 가능한 임베딩과 동일한 형태를 가지므로, 이를 '패치 임베딩'이라고 부릅니다.
CNN 임베딩(Hybrid 구조)
또 다른 방법으로, CNN의 feature maps을 활용하여 입력 시퀀스를 형성하는 접근법도 있습니다. 이 경우, 입력 채널이 3개인 (R, G, B) 이미지를 D 출력 채널을 가진 컨볼루션 레이어에 적용합니다. 이 레이어는 커널 크기가 (P, P)이고 스트라이드(stride)도 (P, P)인 구성으로 되어 있습니다. 이미지를 이 컨볼루션 레이어에 입력하면, 하나의 커널이 하나의 패치 역할을 하게 되며, 이를 통해 중복되지 않는 N개의 패치가 D차원으로 시퀀스 형태로 매핑됩니다.
위의 이미지 패치에 더 나아가, BERT의 [class] 토큰에 해당하는 개념으로 추가적인 학습 가능한 클래스 임베딩을 도입합니다. 이 임베딩은 \(z^0_0 = x_{class}\)로 표현되며, 여기서 아래 첨자는 Encoder 레이어의 인덱스(총 개수: L)를, 위 첨자는 패치의 인덱스(총 개수: N + 1)를 나타냅니다. 이 임베딩을 'Classification head'라 하고, Pre-training과 fine-tuning 각각 다르게 동작합니다.
- Pre-training: 오직 하나의 은닉층(hidden layer)을 가지고 있으며, 이는 BERT와 유사하게 마스크 언어 모델(MLM)과 다음 문장 예측(NSP)을 사용하여 사전 학습됩니다. 그러나 기존의 NSP 방식과 차별화되는 점은, 이 모델은 다음 문장 대신 다음 이미지 패치를 예측하는 방식을 채택하고 있습니다. 한 개의 은닉층을 가진 모델이므로, 이는 바이너리(0 또는 1) 예측을 수행합니다. 여기서 다음 이미지 패치가 정확하면 1로, 그렇지 않으면 0으로 학습됩니다.
- Fine-tuning: 이미지 분류 작업에 예측될 클래스의 개수 만큼 은닉층을 가지고 있으며, 기존 이미지 분류 모델과 동일하게 작동합니다.
Position Embedding
위치의 정보가 없는 Transformer의 특성에 따라 본 논문은 위치 정보를 패치 임베딩에 추가합니다. 2D Position embeddings이 성능 향상이 그다지 없었기 때문에 1D Position embeddings을 사용합니다.
마지막으로, ViT는 Transformer 특성에 따라 CNN이 가지는 locality와 Translation equivariance 같은 Inductive biases가 부족합니다. 이 구조는 오직 MLP 레이어들로만 구성되어 있으며, CNN의 지역적 특성과는 달리 전역적 관점에서 학습이 이루어집니다. 이러한 특성 때문에 ViT는 대규모 데이터에 대한 Pre-training이 필요하며, 그 후 각각의 Task에 맞게 Fine-tuning이 필요합니다.
패치 임베딩 과정에서는 이미지의 해상도가 커지더라도 패치의 크기는 동일하게 유지되어, 메모리의 한계 내에서 긴 이미지 시퀀스를 생성할 수 있습니다. 그러나 이미지의 해상도에 따라 변하는 시퀀스는 사전 학습된 Position embeddings의 의미를 잃어버릴 수 있습니다. 이를 해결하기 위해 위치 정보에 2차원 보간(2D interpolation)을 적용하여 위치 임베딩을 조정합니다.
Experiments
- 사전학습 데이터 셋: ImageNet-1k(1.3M), ImageNet-21k(14M), JFT-18k(303M)
- 평가 데이터 셋: 19-Task VTAB - 3가지 하위 요소 [Natural, Sepcialized, Structred]
Model Variants
Comparison to state of the Art
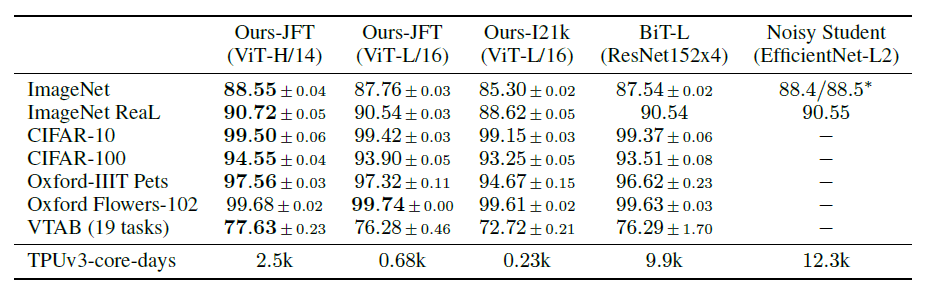
ViT 모델 "/ 옆에 있는 숫자"는 이미지 패치 사이즈입니다. ViT에 사전 훈련한 모델들이 기존 모델의 성능을 능가하는 것과 학습에 실질적으로 더 적은 계산 자원이 필요한 것을 볼 수 있습니다.
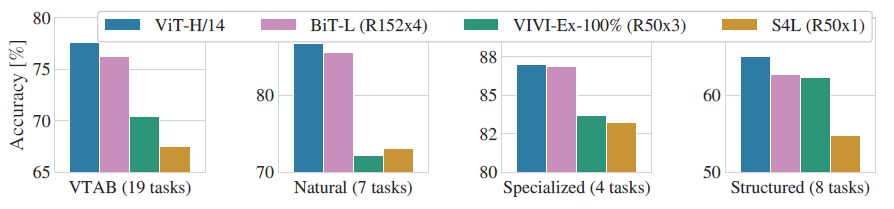
모든 평가 데이터에 대해서도 기존 CNN 모델의 성능을 능가하였습니다.
Pre-training data
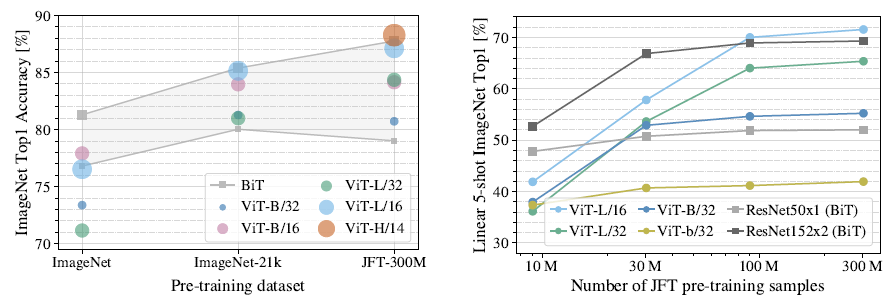
동일한 학습 설정 하에, ViT는 데이터 크기가 작고 모델 사이즈가 작을 때 CNN에 비해 상대적으로 낮은 성능을 보이지만, 데이터 크기가 커지고 모델의 파라미터가 증가함에 따라 성능이 지속적으로 향상됩니다. 반면, CNN의 경우 데이터 크기가 커질수록 성능 향상의 그래프가 빠르게 감소하는 경향을 보입니다.
이는 직관적으로 해석할 때, CNN이 작은 데이터셋에서는 내재된 Inductive biases 덕분에 Transformer보다 우수한 성능을 보이지만, 큰 데이터셋에서는 Inductive biases 없이 데이터의 패턴을 직접 학습하는 것이 더 효과적임을 시사합니다.
Inspecting vision transformer
이 파트에서는 네트워크의 내부 표현들을 분석하고, 그 결과는 아래와 같습니다.
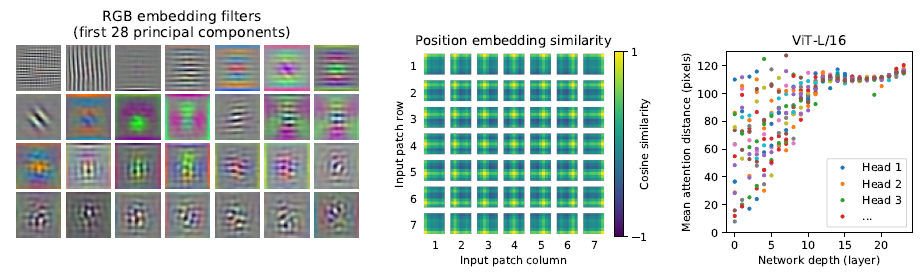
- 왼쪽 그림: RGB 이미지를 ViT에 입력하기 전에 이미지를 패치로 나누고, D차원으로 매핑한 후, 학습된 임베딩 필터들의 주요 구성 요소를 보여줍니다. 이 구성 요소들은 잘 학습된 CNN 필터의 기능과 유사한 패턴을 나타내는 것을 볼 수 있습니다
- 가운데 그림: ViT에서 이미지 패치 임베딩에 이어 포지션 임베딩을 주입한 상태를 나타냅니다. 이 그림은 포지션 임베딩 간의 코사인 유사도를 분석한 것으로, 가까운 패치 간에 높은 유사도가 나타나는 것을 확인할 수 있습니다. 같은 열이나 같은 행에 있는 패치들 사이에서 높은 유사도가 관찰됩니다.
- 오른쪽 그림: 각각의 Attention head가 네트워크에서 self-attention 기능을 얼마나 잘 활용하는지 조사한 결과를 보여줍니다. 이미지 공간에서 attention weights를 기반으로 정보가 통합되는 평균 거리, 즉 "attention distance"를 계산합니다. 이는 CNN의 수용 필드의 크기와 유사합니다. 224 x 224 크기의 이미지로 실험을 진행했기 때문에, 평균 거리가 대략 112 정도에 이르면 각 픽셀이 전역적으로 정보를 통합했다고 볼 수 있습니다. Layer 층이 깊어질수록 모든 Attention head가 이 거리에 근접해 모든 정보를 통합할 수 있는 것을 확인할 수 있습니다.
더보기
위의 오른쪽 그림은 Inductive biases가 내장되어 있는 CNN과 Transformer를 통합하여 각 Head가 수렴하는 정도를 비교하였는데, 확실히 첫 번째 레이어부터 기존 모델보다 대체적으로 Attention distance가 높고, 더 빠르게 수렴하는 정도를 보입니다.
오늘은 처음으로 Transformer를 컴퓨터 비전에 접목시킨 ViT 논문을 리뷰 해보았습니다.
자세한 내용은 본 논문을 참고하시고, 언제나 게시글에 대한 피드백은 환영입니다.
긴 글 읽어주셔서 감사합니다.




댓글