Keras의 전처리와 데이터 로딩

위 사진을 보면 왼쪽은 화질이 좋은 강아지 사진이 있고 오른쪽은 화질이 좀 떨어지는 고양이 사진이 있습니다. 이 두 사진은 np.array로 표현하면, 각각 (2000 x 1640 x 3), (320 x 240 x 3) 입니다.
왼쪽의 이미지는 너무 값이 크니까 오른쪽 고양이와 같은 사진이 50000장 있다고 가정해 봅시다. 이 메타데이터들을 한 번에 np.array로 변환시켜 CPU에 올리면 320 x 240 x 50000 = 3,840,000,000KB 대략 3.8TB입니다. RAM이 3.8TB나 되는 사람은 없겠지요.... 그래서 나온 방법이 메타데이터 즉. jpg 사진들을 Batch Size만큼 CPU가 np.array로 바꾸고 또 GPU가 받을 수 있게 tensor로 변형시키고, GPU가 연산을 끝내면 CPU에게 다시 Batch Size만큼 데이터를 요청합니다. 그러면 CPU가 다시 np.array로 바꾸고 연산하고 반복적으로 50000건의 데이터가 전부 학습이 되면 이제 Generator를 메모리에서 없앱니다.
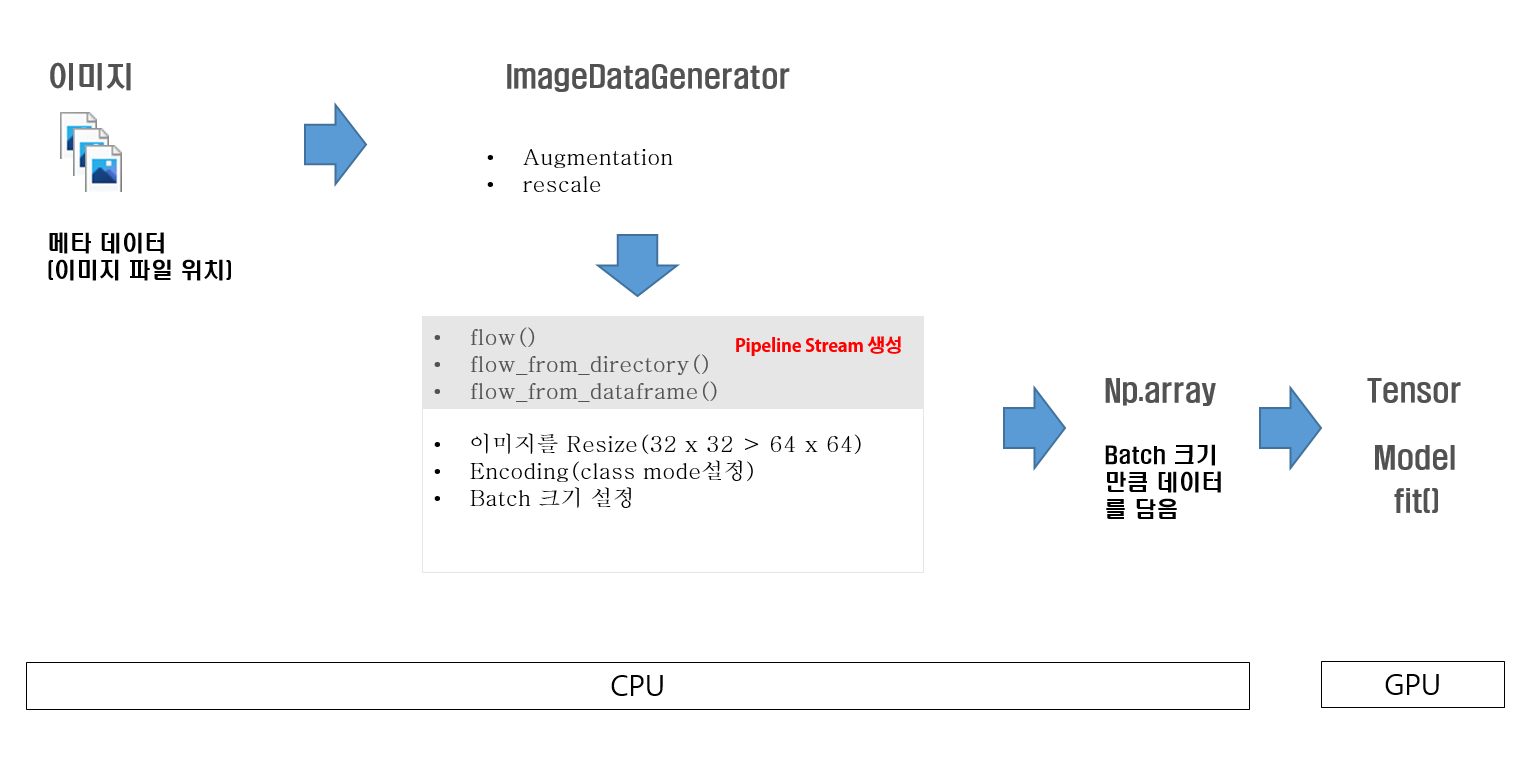
이해를 더 돕기 위해 Batch Size가 4이고 20개의 데이터로 구성된 이미지가 있다고 가정해봅시다. 아래의 그림을 보면 4개의 데이터를 읽어 전처리, Augmentation 등등하고 Tensor로 변경해 Model에 학습시키고 학습이 완료하면 다음 데이터가 올 때까지 대기하는 과정을 모든 데이터가 학습할 때까지 반복합니다. 이렇게 하여 CPU와 GPU가 서로 같이 일을 하며 딥러닝 연산의 병렬 처리를 더욱더 빠르게 하고, Out Of Memory 즉 메모리가 터지는 것을 방지합니다.

이제 코드로 구현해 보겠습니다.
코드
Kaggle에 Cat and Dog라는 데이터를 활용하겠습니다. 이 데이터는 강아지와 고양이 두 동물을 분류하는 것입니다.
os.walk로 /content/input디렉터리 하위 디렉터리에 있는 모든 메타 파일들을 읽어서 출력하였습니다.
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/content/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
위 소스를 활용하여 paths(데이터의 절대 경로), data_divs(train, test 구분), label_divs(DOG, CAT 구분) 3개의 column으로 구성된 데이터 프레임을 만들고, 잘 만들어졌는지 결과를 확인해 보겠습니다.
paths = []
data_divs = []
label_divs = []
for dirname, _, filenames in os.walk('/content/input'):
for filename in filenames:
# 이미지 파일이 아닌 파일을 걸러내야함
if '.jpg' in filename:
# 파일의 절대 경로
file_path = dirname + '/' + filename
paths.append(file_path)
# train, test 데이터 세트 구분
if '/training_set/' in file_path:
data_divs.append('train')
elif '/test_set/' in file_path:
data_divs.append('test')
# 개, 고양이 구분
if 'dogs' in file_path:
label_divs.append('DOG')
elif 'cats' in file_path:
label_divs.append('CAT')
df = pd.DataFrame({'path':paths, 'data': data_divs, 'label':label_divs})
df.head()
데이터 프레임이 정상적으로 만들어졌습니다. 이제 데이터들을 확인해보겠습니다.
import matplotlib.pyplot as plt
import cv2
fig, axs = plt.subplots(nrows=1, ncols=5, figsize=(20, 8))
for i in range(5):
axs[i].imshow(cv2.cvtColor(cv2.imread(df.loc[i, 'path']), cv2.COLOR_BGR2RGB))
데이터 경로도 잘 잡힌 것으로 보입니다. 하지만 데이터의 크기가 전부 다릅니다. 모델에 학습할 때는 데이터의 크기가 전부 같아야 합니다. 그리고 훈련 데이터 세트를 검증 데이터 세트로 나누겠습니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
train_df = df[df['data'] == 'train']
test_df = df[df['data'] == 'test']
tr_df, val_df = train_test_split(train_df, test_size=0.2, stratify=train_df['label'])
# 훈련 데이터는 좌우와 상하반전 스케일적용, 검증과 테스트 데이터는 스케일만 적용
tr_gen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True, rescale=1/255.)
val_gen = ImageDataGenerator(rescale=1/255.)
test_gen = ImageDataGenerator(rescale=1/255.)
# x_col은 메타 데이터용 DataFrame에서 image 파일의 절대경로 위치를 나타내는 column명을 의미
# y_col은 메타 데이터용 DataFrame에서 label값 column명을 의미. 이 때 y_col로 지정된 컬럼은 반드시 문자열(object type)이 되어야 함.
# y_col의 경우 미리 encoding(label 또는 원핫)을 해서 숫자값으로 절대 변경하면 안됨.
# image array 는 224, 244로 변경, batch size 는 64
tr_flow_gen = tr_gen.flow_from_dataframe(dataframe=tr_df,
x_col='path',
y_col='label',
target_size=(224, 224),
batch_size=64,
class_mode='binary', # 문자열만 가능
shuffle=True)
val_flow_gen = val_gen.flow_from_dataframe(dataframe=val_df,
x_col='path',
y_col='label',
target_size=(224, 224),
class_mode='binary',
batch_size=64,
shuffle=False)이제 Generator가 잘 적용되었는지 next로 확인해보겠습니다. next는 generator를 디버깅할 때 처음 배치 사이즈만큼 데이트를 가져오는 메서드입니다.
first_tr = next(tr_flow_gen)
first_val = next(val_flow_gen)
print(first_tr[0].shape, first_tr[1].shape, first_val[0].shape, first_val[1].shape)
print(first_tr[0])
print(first_val[0])
데이터도 잘 가져오고 스케일링도 잘 된 것을 볼 수 있습니다. 이제 데이터를 로딩할 준비는 다 됐으니 학습모델만 만들고 학습만 시키고 평가만 하면 됩니다. 모델은 이미 만들어져 있는 xception이라는 모델을 전이 학습하고, 학습과 평가 둘 다 진행하겠습니다.
from tensorflow.keras.applications import Xception
from tensorflow.keras.layers import GlobalAveragePooling2D, Dropout, Dense, Input
from tensorflow.keras.models import Model
input_tensor = Input(shape=(224, 224, 3))
base_model = Xception(input_tensor=input_tensor, include_top=False, weights='imagenet')
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(rate=0.5)(x)
x = Dense(50, activation='relu')(x)
# softmax가 아닌 sigmoid generator에서 class_mode를 binary로 설정했기때문
output = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
# softmax에서 sigmoid가 되었기때문에 binary_crossentropy
model.compile(optimizer=Adam(0.001), loss='binary_crossentropy', metrics=['accuracy'])
lr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, mode='min', verbose=1)
st_cb = EarlyStopping(monitor='val_loss', patience=5, mode='min', verbose=1)
model.fit(tr_flow_gen, epochs=15, validation_data=val_flow_gen, callbacks=[lr_cb, st_cb])
test_flow_gen = test_gen.flow_from_dataframe(dataframe=test_df,
x_col='path',
y_col='label',
target_size=(224, 224),
class_mode='binary',
batch_size=64,
shuffle=False)
result = model.evaluate(test_flow_gen)
print('loss : ', result[0], ', accuracy : ', result[1])
'컴퓨터비전 > CNN' 카테고리의 다른 글
| [딥러닝] AlexNet 모델의 개요 및 특징 (0) | 2022.03.17 |
|---|---|
| [딥러닝] Albumentations의 데이터 증강 이해 (2) | 2022.03.17 |
| [딥러닝] 전이 학습(Transfer Learning) (0) | 2022.03.15 |
| [딥러닝] 데이터 증강(Data Augmentation) (2) | 2022.03.14 |
| [딥러닝] GAP(Global Average Pooling) (0) | 2022.03.14 |




댓글