Pandas 패키지란?
데이터를 수집하고 정리하는 데 최적화된 도구
- numpy 기반으로 작성된 라이브로리로 데이터 불러오기, 전처리, 통계 분석에 사용
- Series 형태와 DataFrame 형태의 자료구조 존재
- 실무에서 접하는 엑셀 파일의 스프레드시트가 DataFrame 형태
- 데이터 분석에 있어서 필수적인 라이브러리로, 전처리시 대부분 pandas를 활용
시리즈(Series)
시리즈는 1차원 배열의 값에 각 값이 대응되는 인덱스를 가지고 있습니다.
import pandas as pd
s = pd.Series([1000, 2000, 3000], index=['a', 'b', 'c'])
sa 1000
b 2000
c 3000
dtype: int64
index와 value로 이루어져 있으므로 접근할 수 있습니다.
print('index : ', s.index)
print('values : ', s.values)index : Index(['a', 'b', 'c'], dtype='object')
value : [1000 2000 3000]
데이터 프레임(Data Frame)
데이터 프레임은 2차원 배열로, 행과 열이 존재합니다. 시리즈가 index와 value가 존재하고, 데이터 프레임은 이 시리즈들을 여러 열에 추가된 것입니다.
table = {'일자': ['2019-01-01', '2019-01-04', '2019-01-07', '2019-01-10', '2019-01-13'],
'가격': [1000, 1500, 2000, 2500, 3000],
'구매여부': ['False', 'True', 'True', 'True', 'True'],
'제품': ['gum', 'snack', 'beverage', 'dongas', 'alchoal']}
df = pd.DataFrame(table)
df

마찬가지로 index, value에 접근할 수 있고 추가로, column도 접근이 가능합니다.
print('index : ', df.index)
print('column : ', df.columns)
print('values : \n', df.values)index : RangeIndex(start=0, stop=5, step=1)
column : Index(['일자', '가격', '구매여부', '제품'], dtype='object')
values :
[['2019-01-01' 1000 'False' 'gum']
['2019-01-04' 1500 'True' 'snack']
['2019-01-07' 2000 'True' 'beverage']
['2019-01-10' 2500 'True' 'dongas']
['2019-01-13' 3000 'True' 'alchoal']]
또 csv파일이나, excel파일도 불러올 수 있습니다.
df = pd.read_csv('data_file/titanic.csv')
df.head(5)

기본 문법
- shape : 데이터 프레임의 크기 확인
- info : 데이터프레임의 기본정보 출력
- describe(include=False): 데이터프레임의 기술통계정보 요약
- count: 열 데이터 개수 확인
- value_counts(): 열 데이터의 고윳값 개수
- dtypes: 열의 속성 확인
groupby
- 집단, 그룹별로 데이터를 집계할 때 사용
- 데이터 프레임. groupby(그루핑 대상, as_index=False)로 사용
- min, max, mean, count, first, last 등의 함수를 사용 가능
타이타닉호의 성별에 따른 생존율을 보면 아래와 같은 결과가 나옵니다. (1: 생존, 0: 사망 0
df.groupby('Sex')['Survived'].mean()Sex
female 0.742038
male 0.188908
Name: Survived, dtype: float64
데이터 선택
대괄호를 하나만 쓰면 Series로, 두 개 써서 리스트로 나열하면 데이터 프레임으로 나옵니다.
df['Pclass'] # 시리즈
df[['Pclass']] # 데이터프레임0~4 인덱스 슬라이싱
df[0:5]

loc: loc [s:e, ['Pclass']] s~e까지 출력 [index이름, column이름]
df.loc[0:3, ['Pclass']]

df.loc[3:5]
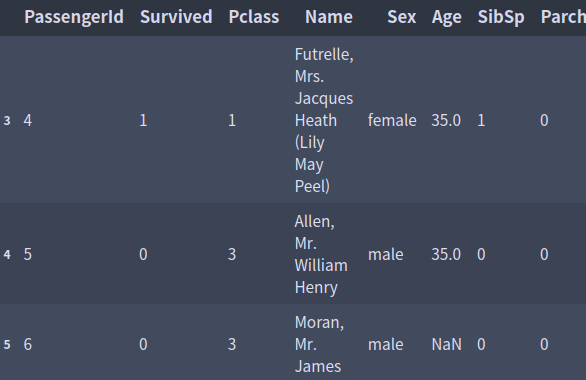
iloc: iloc [s:e, [0]] s부터 e-1까지, 인덱스의 인덱스부터 칼럼의 인덱스까지
df.iloc[1:3, [0]]
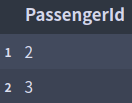
df.iloc[3:4]
df.iloc [3:4]

query: df.query(조건) column의 조건
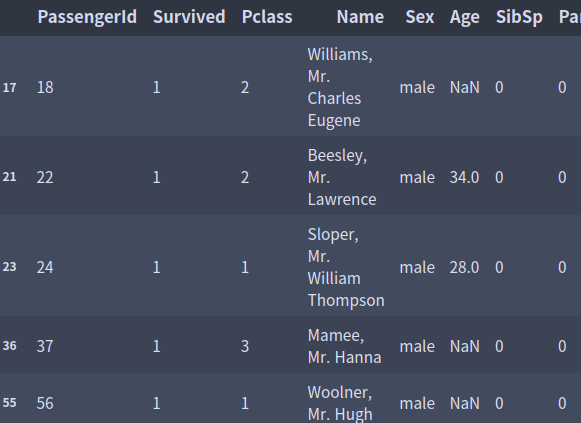
df.query('Survived == 1 & Sex == "male"')
filter: 이름을 이용한 칼럼 선택 (items=None, like=None, regex=None, axis=None)
df.filter(items=['Survived', 'Sex']) #Survived, Sex의 아이템만 포함

df.filter(regex='S', axis=1) # S가 포함된 axis가 칼럼인 곳 regex에 정규식 사용 가능

mask: 조건에 해당하는 데이터 행을 mask처리
# 생존자 마스킹 처리
df.mask(df['Survived'] == 1)['Survived'].value_counts()0.0 549
Name: Survived, dtype: int64
df.mask(cond = df['Survived'] == 1, other = 999)
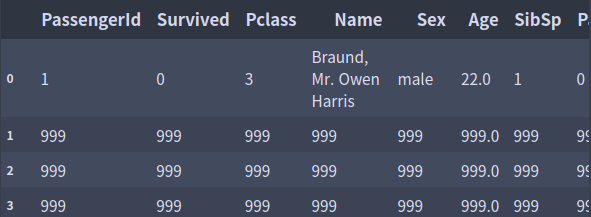
데이터 결합
concat/append
- 기준 열을 사용하지 않고 데이터를 연결함
- 위/아래로 데이터의 행 추가, 단순히 두 Series 또는 DataFrame을 연결해서 index가 중복될 수 있음
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
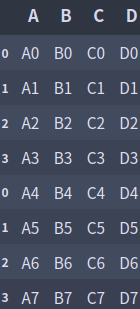
# ignore_index를 True로 하면 모든 인덱스 무시
pd.concat([df1, df2], axis=0, ignore_index=False)
merge/join
- DataFrame의 공통 열 혹은 인덱스를 기준으로 두 개의 DataFrame을 합침 ( 이때 기준이 되는 행, 열을 켜라고 함)
- merge와 join은 동일한 기능인데, 명령어가 다른 정도의 차이
- A, B 병합할 경우에 merge 사용 ex) merge(A, B)
- A에 B를 결합할 경우에는 join 사용 ex) A.join(B)
- pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, copy=True, indicator=False)
- left, right: merge 대상
- how: merge 종류 (left, right, inner, outer)
- on: 기준이 되는 column or index
- left_on: 왼쪽 column or index 중 조인할 이름
- right_on: 오른쪽 column or index 중 조인할 이름
- indicator: 결합된 데이터의 출처를 알 수 있음
- pd.DataFrame.merge(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
left = pd.DataFrame({'key1': ['K0', 'K1', 'K2', 'K3'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K2', 'K3'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2']) # default: inner
result

result = pd.merge(left, right, on=['key1', 'key2'], how='left')
result

result = pd.merge(left, right, on=['key1', 'key2'], how='right')
result
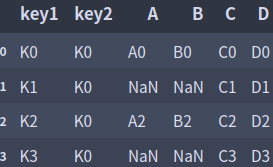
result = pd.merge(left, right, on=['key1', 'key2'], how='outer', indicator=True)
result
left = pd.DataFrame({'key1': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'C': ['C1', 'C2', 'C3'],
'D': ['D1', 'D2', 'D5']},
index=[1, 2, 5])
result = left.join(right) # key를 주지 않으면 index끼리 join
result

데이터 변환
transpose
- T(transpose, 전치)는 데이터의 중심 대각선 기준으로 행과 열 변환 행 -> 열/열-> 행으로 변환
- df.T, df.transpose()
import pandas as pd
from IPython.display import display
df = pd.DataFrame({'A': ['K0', 'K1', 'K2', 'K3'],
'B': ['A0', 'A1', 'A2', 'A3'],
'C': ['B0', 'B1', 'B2', 'B3']})
display(df)
display(df.T)

pivot
- 데이터 칼럼에서 key 칼럼(index, columns)을 지정하여 값(value)을 변형(행과 열 변환)
- "index"지정 칼럼은 행(row)의 index로 사용하고 "columns" 지정 컬럼은 열의 index로 사용
- 만약 각 행과 열에 해당하는 데이터(value)가 존재하지 않으면 NaN으로 채워짐
df = pd.DataFrame({'index': [1, 1, 1, 2, 2, 2],
'column': ['col_1', 'col_2', 'col_3', 'col_1', 'col_2', 'col_3'],
'value_1': [1, 2, 3, 4, 5, 6],
'value_2': ['x', 'y', 'z', 'q', 'w', 't']})
display(df)
display(df.pivot(index='index', columns='column', values='value_1'))
display(df.pivot(index='index', columns='column', values=['value_1', 'value_2']))
melt
- pivot의 반대 개념으로 ID로 지정한 칼럼을 제외한 나머지 칼럼의 자료를 위에서 아래로 쌓는 변환
- ID칼럼을 기준으로 원래 데이터에 있던 여러 개의 컬럼 이름의 'variable' 칼럼에 쌓고(위에서 아래로) 'value' 컬럼에 ID와 variable에 해당하는 값을 넣어주는 식
- pd.melt(df, id_var=None, value_vars=None, var_name=None, value_name='value', col_level=None)
df = pd.DataFrame({'index': [1, 1, 1, 2, 2, 2],
'column': ['col_1', 'col_2', 'col_3', 'col_1', 'col_2', 'col_3'],
'value_1': [1, 2, 3, 4, 5, 6],
'value_2': ['x', 'y', 'z', 'q', 'w', 't']})
# melt: id_var를 제외한 나머지 컬럼을 풀어서 넣음
display(df.melt(id_vars=['index', 'column']))
# id 및 value 컬럼을 지정
display(df.melt(id_vars=['index', 'column'], value_vars=['value_1']))
stack/unstack
- stack: 칼럼의 index를 행의 여러 개 label중 가장 안쪽의 label 로 un-pivot(melt)하여 변환
- unstack: stack의 반대로, 행의 여러 개 label중 가장 안쪽의 label을 컬럼의 index(열의 이름들)로 변환
df = pd.DataFrame({'index': [1, 2, 3],
'alpha': ['A', 'B', 'C'],
'values': [11, 22, 33],
'xyz': ['x', 'y', 'z']})
display(df)
df_stack = df.stack()
print(df_stack)
df_stack.unstack()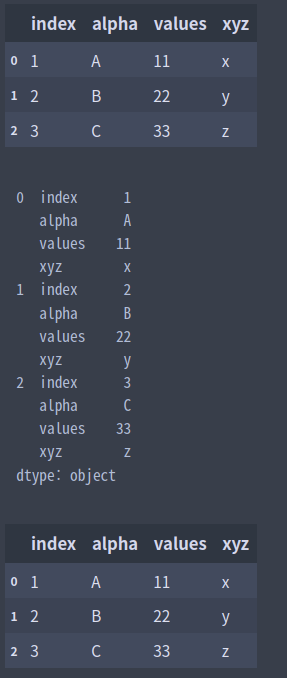
crosstab
- 지정된 컬럼의 값(수준) 별 빈도를 요약하여 도수 분포표, 교차 표를 생성
- 범주형 변수의 빈도를 파악에 자주 사용
- pd.crosstab(index, columns, rownames=None, colnames=None, margins=False, margins_name = 'All', normalize=False)
df = pd.DataFrame({'factor1': ['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'factor2': ['a', 'b', 'c', 'a', 'b', 'a', 'b', 'c', 'c'],
'value': [11, 13, 12, 12, 14, 12, 13, 11, 12]})
display(df)
display(pd.crosstab(df['factor1'], df['factor2']))
display(pd.crosstab(df['factor1'], df['factor2'], rownames=['Fact1'], colnames=['Fact2'], margins=True))
데이터 변환
- 행 인덱스 기준 행렬: DataFrame.sort_index()
- 열 기준 정렬: DataFrame.sort_values()
dict_data = {'c0': [1, 2, 3], 'c1': [4, 5, 6], 'c2': [7, 8, 9], 'c3': [10, 11, 12],
'c4': [13, 14, 15]}
df = pd.DataFrame(dict_data, index=['r3', 'r1', 'r2'])
display(df)
display(df.sort_index(ascending=False)) # 현재는 사전순으로 정렬
display(df.sort_values(by='c2', ascending=False))
데이터 중복 확인
- duplicated: 중복되는 행을 Boolean 값으로 표시 -> DataFrame.duplicated()
- DataFrame.drop_duplicates(['칼럼 1']) -> 칼럼 1을 기준으로 중복된 행 삭제 unique행만 남김
dict_data = {'a': [1, 2, 3, 2, 3], 'b': [1, 2, 3, 2, 3], 'c': [1, 2, 3, 2, 3]}
df = pd.DataFrame(dict_data)
display(df)
print(df.duplicated())
display(df[~df.duplicated()])
display(df.drop_duplicates())
댓글