회귀란?
회귀는 현대 통계학을 떠받치고 있는 주요 기둥 중 하나입니다.
영국의 통계학자 갈톤이 수행한 연구에서, 부모의 키가 모두 클 때 자식의 키가 크긴 하지만 그렇다고 부모를 능가하지 않았고, 부모의 키가 모두 아주 작을 때 그 자식의 키가 작기는 하지만 부모보다는 큰 경향을 발견했습니다.
부모의 키가 아무리 크더라도 자식의 키가 부모를 능가하면서 시대를 넘어 무한정 커지는 것은 아니고, 자식의 키가 아무리 작더라도 부모보다 더 작아서 시대를 이어가며 무한정 작아지는 것은 아니라는 것입니다.
즉, 사람의 키는 평균 키로 회귀하려는 경향을 가진다는 자연의 법칙이 있다는 것입니다.
데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법입니다.
회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법입니다.
예를들어, 아파트의 방 개수, 방 크기, 역까지거리 등 여러개의 독립변수가 아파트의 가격이라는 종속변수를 뜻합니다.

여기서 X1, X2, X3... Xn 이 독립변수이고, Y가 종속변수, W1, W2, W3... Wn 이 회귀계수(가중치) 입니다.
회귀 예측의 핵심은 주어진 피처(독립변수)와 결정 값(종속변수)로 최적의 회귀 계수를 찾아내는 것입니다.
독립변수가 1개이면 단일회귀, 선형 회귀이고
여러개이면 다중 회귀, 비선형 회귀 입니다.
선형회귀

선형 회귀는 실제 값과 예측값의 차이를 최소화하는 직선형 회귀선을 최적화하는 방식입니다.
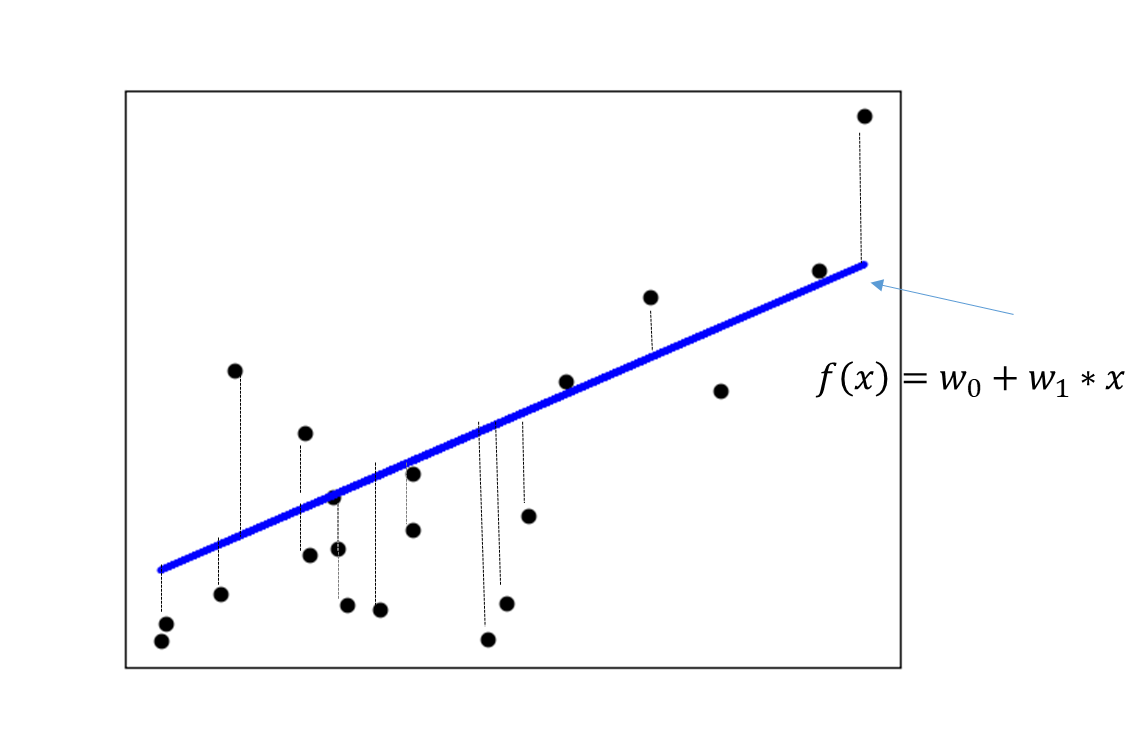
실제 값과 회귀 모델의 차이에 따른 오류 값을 잔차라고 부릅니다. 최적의 회귀모델을 만든다는 것은 바로 전체 데이터의 잔차(오류 값)의 합이 최소가 되는 것입니다.
잔차는 +나 -가 될수 있기 때문에 절댓값을 취해서 더하거나(Mean Absolute Error), 제곱을 구해서 더하는 방식(Residual Sum of Square)을 취합니다. 일반적으로 미분의 계산을 편리하게 하기 위해 RSS 방식으로 구합니다.
그럼 최적의 회귀선은 어떻게 구할까요?? 위에서 말했듯이 RSS는 잔차의 제곱의합을 구하는 것입니다. MSE는 이를 독립변수의 갯수(N)만큼 나누어 주는 것입니다.
RSS = (y1 - (w1*x1 + w0)²) + (y2 - (w1*x2 + w0)²) + (y3 - (w1*x3 + w0)²) + ....(yn - (w1*xn + w0)²)
MSE = ((y1 - (w1*x1 + w0)²) + (y2 - (w1*x2 + w0)²) + (y3 - (w1*x3 + w0)²) + ....(yn - (w1*xn + w0)²)) / N
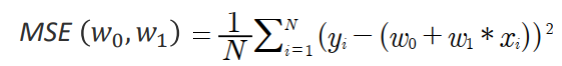
다변량 회귀(Multivariate Regression), 다항식 회귀
다변량 회귀(Multivariate Regession)
두개 이상의 변수로 만든 회귀식
ex) 선형회귀 => 몸무게를 이용해 키를 예측 키 = w0 + x1 * 몸무게
ex) 다변량 회귀 => 몸무게와 나이를 이용해 키를 예측 => 키 = w0 + w1 * 몸무게 + w2 * 나이
변수가 여러 개인 경우 행렬로 표시합니다.
다항식 회귀(Polynomial Regession)
y = w0 + w1*x + w2*(x^2)

이제 그럼 어떻게 회귀계수를 구하는지 알아보겠습니다.
경사 하강법(Gradient Descent)
경사 하강법의 사전적 의미에서도 알수 있듯이, '점진적으로' 반복적인 계산을 통해 W 파라미터의 값을 업데이트 하면서 잔차의 값이 최소가 되는 W 파라미터를 구하는 방식입니다.

위에서와 같이 젤 밑에 기울기가 최소가 되는 지점이 잔차가 최소가 되는 지점입다. 손실함수에서는 각 가중치마다 편미분을 해주어 미분 함수의 최솟값을 구해주어야 합니다.
일반적인 1차함수로 예시를 들면
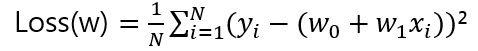
각각 편미분 해주어서 하강한 가중치를 구합니다.

이렇게 기존 W값에 손실 함수의 편미분 값을 감소 시키는 방식을 적용하는데 일정한 계수를 곱해서 감수 시키며, 이를 학습률(Learning Rate) 이라고 합니다.

통계적 방법



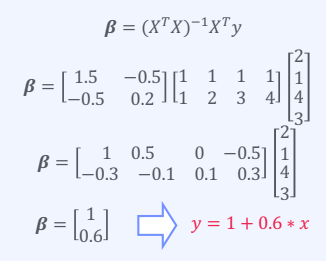
Bisection Method
- 임의의 두개의 값을 설정한다.
- 두 값의 y값을 비교한다.
- y값이 큰 점을 두점의 가운데 점으로 바꾼다.
- 임의의 두 값의 차이가 작아질 때 까지 1~3을 반복한다
'머신러닝' 카테고리의 다른 글
| [머신러닝] 의사결정트리(Decision Tree) 알고리즘 (2) | 2022.05.05 |
|---|---|
| [머신러닝] 성능 평가 지표 (0) | 2022.05.04 |
| [머신러닝] Logistic Regression (0) | 2022.05.04 |
| [머신러닝] 지도학습 (학습/테스트/검증 데이터 분리) (0) | 2022.05.03 |
| [머신러닝] 머신러닝이란? (0) | 2022.05.03 |



댓글