참고자료
[논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(Vision Transformer)
참고 자료 [논문리뷰] Attention is All you need의 이해 소개 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best perfor
lcyking.tistory.com
들어가며
본 논문은 Vision Transformer의 사전 지식이 있다는 가정하에 작성되었습니다.
기존에 Dense Prediction Task(Segmentation, Detectdion)는 CNN이 주로 사용되고 있었습니다. 하지만 본 논문이 게재될 당시, Transformer 계열의 모델인 Vision Transformer(ViT)가 이미지 분류에서 좋은 성능을 내고 있었습니다. 그에 따라, ViT로 Dense Prediction도 할 수 있지 않을까 하는 생각으로 비슷한 연구가 진행되고 있었습니다.
하지만, 계산량을 줄이기 위해 픽셀들을 16 * 16 정도의 큰 패치로 잘라서 사용하는 ViT는 저해상도의 feature map을 가지고, 단일 스케일로 representations을 학습하기 위해 연산이 진행됩니다.
본 논문에서 주장하는 바는, 일반적으로 CNN 구조에서 Dense Prediction를 수행하는 네트워크를 생각해 보면, 고차원에서 저차원으로 차원을 축소하며 이걸 또 Pyramid 구조로 연결시키면서 풍부한 Representations을 학습해나가는 구조인데, 기존 ViT처럼 단일 스케일과 저 차원의 Feature map으로 Representaitons을 학습해나 가는 건 적절하지 않다고 주장합니다.
그래서, 이 ViT를 Pyramid 구조로 만들면 어떻겠냐 하는 것이 이 논문에서의 주안점입니다. 이렇게 Pyramid 구조를 구성하여 풍부한 표현들을 학습한다면, 다른 Task들을 쉽게 플러그인 하여 좋은 성능을 기대할 수 있다고 합니다.

본 논문에서 ViT에 Pyramid 구조를 적용한 것을 Pyramid Vision Transformer(PVT)라 하며, 기존 ViT와 3가지 차이점이 있다고 합니다.
- 기존 ViT의 큰 패치(16 * 16)를 더 세분화된 패치(4 * 4)로 시작 패치를 나눔.
-> Dense Prediction의 핵심인 고해상도의 표현들에 대한 학습이 가능 - 계산 비용을 줄이기 위해 네트워크가 깊어질수록 progressive shrinking strategy 도입
-> 1번과 같이 고해상도의 연산만 계속해서 고수하면, 계산 비용과 메모리 비용이 너무 커지기 때문 - 추가적으로 계산 비용을 더 줄이기 위해, 기존 Transformer의 Multi-Head Attention(MHA)를 Spatial-Reduction Attention(SRA)로 변경
대략적인 설명은 이렇고, 이제 세부적인 구조를 살펴보도록 하겠습니다.
Pyramid Vision Transformer(PVT)
본 논문은 ViT에 Pyramid를 적용하는 것이라 하여, 기존 ViT 구조와 비슷한 모양을 띕니다. 아래는 전체 구조에 대한 그림입니다.
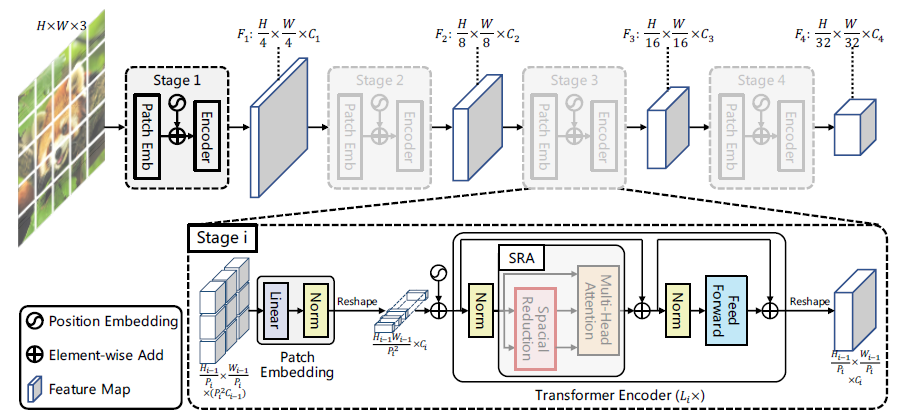
기존 ViT 구조에서 4개의 서로 다른 스케일을 생성하기 위해 4개의 스테이지를 가집니다. 모든 스테이지는 패치 임베딩과 여러개의 Transformer Encoder \( L_i \) 레이어를 가집니다.
모든 스테이지는 다른 스케일을 가진다는 것 외에는 같은 구조를 가지기 때문(transformer Encoder 레이어 수만 좀 다를 수 있음)에, 첫 스테이지에 대한 예시를 먼저 들겠습니다.
Stage
먼저, 1. (H * W * 3)의 차원을 가지는 입력 이미지가 \( \frac {HW} {4^2} \)의 패치들로 나눠집니다. 2. 나눠진 패치들은 Flatten과 Linear Projection으로 \( \frac {HW} {4^2} * C_1 \)의 차원을 가지는 패치 임베딩이 되며, 3. 이 패치 임베딩에 Position Embedding이 더해져 Transformer Encoder \(L_i \)에 입력되고 레이어의 수만큼 Transformer 연산을 진행합니다. 연산인 끝난 4. 패치 임베딩을 다시 \( \frac {H} {4} * \frac {W} {4} * C_1 \)로 Reshape하여 feature map \( F_1 \)으로 변환합니다.
위와 같은 과정이 4개의 서로 다른 스케일에 진행되는데, 첫 Patch Embeding 과정에서만 1/4로 쪼개고 이후에는 1/2의 패치 사이즈로 Feature map을 분할합니다. 그렇게 하여 각 스테이지에서 1/4, 1/8, 1/16, 1/32 해상도의 Multi-Scale Feature map을 얻을 수 있고 이 과정이 앞서 말한 progressive shrinking strategy입니다.
Transformer Encoder
마지막으로 제안된 기술로, 고해상도의 Feature map에 대한 Attention 연산을 그대로 진행하면 계산 비용이 너무 많이 들기 때문에, MSA를 SRA로 교체한다고 말했습니다.
Query(Q), Key(K), Value(V)를 입력으로 받는 것은 MSA와 동일하나 K, V의 차원을 축소합니다.
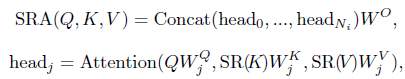
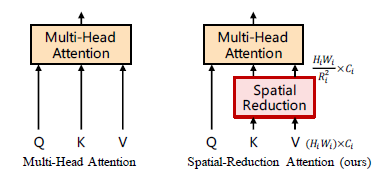
위의 \( W_j^Q, W_j^K, W_j^V \in \mathbb {R}^{C_i * D_{head}} \)와 \( W^O \in \mathbb {R}^{C_i * C_i} \)는 기존과 동일하고, 차이점은 차원 축소 함수인 SR(x)의 추가입니다. SR(x)은 아래와 같이 구성됩니다.

위 함수는 단순하게 입력값 \( x \in \mathbb {R}^{(H_iW_i) * C_i} \)에 축소 비율 \( R_i \)만큼 축소하는 함수입니다. 먼저, 1. Reshape(x, \(R_i \))가 x를 \( \frac {H_iW_i} {R_i^2} * (R^2_iC_i) \) 만큼 차원 변환을 합니다. 그 후, 2. \(W_S \in \mathbb {R}^{(R^2_iC_i) * C_i} \)에 linear projection하여, 차원을 축소합니다.
-> 라고 논문에는 기재되어 있지만, 코드에는 \( R \) 만큼의 커널 사이즈와 Stride를 가지는 Convolutoin layer를 통과시키는 간단한 방법으로 해결하였습니다.
마치며
본 논문은 위와 같은 단순한 절차들로, Dense prediction task에서 우세한 성능을 내었다고 합니다. Object Detectoin에 적용한 결과만 살펴보겠습니다.
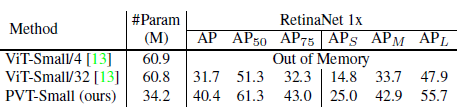
이와 같은 결과로 Dense Prediction에서 Pyramid 구조가 중요함과 동시에, Dense Prediction에서 PVT가 최초로 Transformer 구조를 잘 도입하였다고 결과를 입증하고있습니다.
오늘은 Pyramid Vision Transformer의 리뷰를 해보았습니다.
긴 글 읽어주셔서 감사합니다
'컴퓨터비전' 카테고리의 다른 글
| [논문리뷰] CPVT(CONDITIONAL POSITIONAL ENCODINGS FOR VISION TRANSFORMERS) (0) | 2024.04.25 |
|---|---|
| [논문리뷰] PVT v2: Improved Baselines with Pyramid Vision Transformer (2) | 2024.04.24 |
| [논문리뷰] Mask R-CNN (0) | 2024.03.20 |
| [논문리뷰] Denoising Diffusion Probabilistic Models (DDPM) (3) | 2024.03.06 |
| [논문리뷰] VAE(Variational Auto-Encoder) (3) | 2024.02.28 |




댓글