[논문리뷰] Twins: Revisiting the Design of Spatial Attention inVision Transformers
참조
[논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(Vision Transformer)
참고 자료 [논문리뷰] Attention is All you need의 이해 소개 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best perfor
lcyking.tistory.com
[논문리뷰] Pyramid Vision Transformer(PVT)
참고자료 [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(Vision Transformer)참고 자료 [논문리뷰] Attention is All you need의 이해 소개 Attention Is All You Need The dominant sequence transducti
lcyking.tistory.com
[논문리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
소개 오늘 리뷰하는 논문은 Swin Transformer(Swin)입니다. 이 논문은 Vision Transformer(ViT)의 후속작이라고 보시면 될 것 같습니다. 그렇기 때문에 ViT 기반으로 모델이 동작하는 부분이 대다수이기 때문
lcyking.tistory.com
[논문리뷰] CPVT(CONDITIONAL POSITIONAL ENCODINGS FOR VISION TRANSFORMERS)
참조 [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(Vision Transformer)참고 자료 [논문리뷰] Attention is All you need의 이해 소개 Attention Is All You Need The dominant sequence transduction model
lcyking.tistory.com
들어가며
본 글은 Vision Transformer(ViT), Pyramid Vision Transformer(PVT), Swin Transformer(SwinT), Conditional Positional Vision Transformer(CPVT)에 대한 사전 지식이 있다는 가정하에 작성되었습니다.
최근 ViT가 컴퓨터 비전에서 CNN과 대등하게 새로운 구조로 단단하게 자리 잡고 있습니다. 하지만 Self-Attention 연산이 픽셀수에 따라 이산적으로 계산 복잡도가 올라간다는 제한점이 존재하였습니다. 그래서 이 제한점을 개선하기 위해, ViT에 대한 2가지 파생 연구가 나왔습니다.
- SwinT: 각 Window에 대해서만 Attention을 수행하는 Window Attention과 상호작용을 위한 Shifted Window 방식
- PVT: Key, Value를 Sub-Sampling하여 연산
두 연구 다 공통적으로 계산량을 줄이기 위해 Attention을 어떻게 디자인할지에 대한 연구를 주안점으로 두었습니다. 본 논문도 이러한 선행 연구에 힘입어, SwinT와 PVT에 약간의 변형 및 추가를 가한 Twins-PCPVT와 Twins-SVT를 제안하였습니다.
자세한 구조는 아래에서 살펴보도록 하겠습니다.
Twins
Twins-PCPVT
Twins-PCPVT의 기반 모델인 PVT는 Dense Prediction 분야에서 예측을 더 잘하기 위해, 다양한 표현력을 학습하는 피라미드 구조를 채택했습니다. 아울러 glocal attention에 Key와 Value의 차원을 줄이는 Spatial Reduction(SR)을 도입함으로써 계산 복잡도도 줄여주었습니다.
하지만, Shifted Window 방식을 사용하는 SwinT보다는 성능이 떨어집니다. 본 논문은 이러한 이유가 PVT에서 사용하는 Absolute Position Encoding(APE)에 있다고 합니다. 이미지 사이즈에 맞춰진 고정된 크기의 APE를 사용함으로써 다양한 사이즈의 이미지를 처리할 수 없고, Translation invariance도 없애는 제한점이 있다고 합니다. 여담으로 SwinT도 Relative Position Encoding(RPE)을 사용합니다.
따라서 이 APE를 CPVT에서 사용한 Conditional Position Encoding(CPE)를 사용하면 성능이 올라가지 않을까 하는 생각으로 출발합니다. 뭐 사실 APE에 대한 제한점은 CPE에서도 지적한 사안이며, 이 논리를 자연스레 가져온 것 같습니다. 전체적인 구조에 대한 그림은 아래와 같습니다.
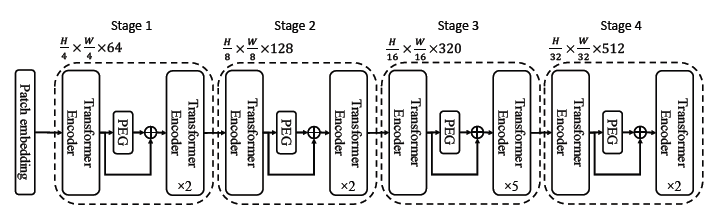
- 각 스테이지 첫 번째 인코더 블록에 Position Encoding Generator(PEG) 삽입
- Batch Normalization 없이, 2D Depth-Wise Conv로 구성
- 이미지 분류를 기준으로 Class Token을 없애고, 마지막 스테이지에서 Global Average Pooling(GAP)로 결과 출력
-> 다른 테스크(e.g. Segmentation, Detection)에서는 그대로 Class Token을 둠
사실상 PVT + CPVT라고 봐도 무방합니다. 이렇게 해서 SwinT와 견줄만한 성능을 낸다고 합니다. 그리고 SwinT의 RPE도 CPE로 변경하면 성능이 좋지 않을까 해서 변경해 봤지만, 성능 변화는 거의 없었다고 합니다. 아마 Shifted Window 방식에는 적절하지 않을것이라 추측합니다.
Twins-SVT
Twins-SVT는 기존 ViT의 Self-Attention에서 계산 복잡도가 너무 크다(\( O(H^2 W^2 d) \))고 지적합니다. 그리하여, Twins-SVT에서는 이 계산복잡도를 줄여주는 spatially separable self-attention(SSSA)를 제안하고, SSSA는 Locally-grouped self-attention(LSA)과 global sub-sampled attention(GSA)로 구성되어 있습니다.
Locally-grouped self-attention (LSA)
먼저 LSA에 대한 설명을 하자면, 2D feature maps을 m * n 개의 sub-windows로 나눕니다(SwinT와 같은 방식). 그렇다면 각 그룹은 \( \frac {HW} {mn} \) 개의 픽셀들을 가지고, 하나의 윈도에 대한 Attention 계산 복잡도는 \( O(\frac {H^2W^2} {mn} d) \)입니다. 그리고 \(k_1 = \frac {H} {m} \)와 \(k_2 = \frac {W} {n} \)로 치환한다면 계산복잡도를 \( O( k_1 k_2 HWd) \)로 다시 정의할 수 있습니다.
그리고, \(K < H \)이고 \( K < W \)이니 계산복잡도는 \( O(HWd) \)로 다시 정의할 수 있고, 기존 HW에 이산적인 복잡도를 가진 ViT와 달리 선형적인 복잡도를 가집니다.
그리고 윈도 내에서만 Attention 하는 것이 아닌 윈도끼리도 상호작용을 해 줘야 하는데 본 논문은 Shifted Window를 사용하는 SwinT와 달리 GSA를 제안하였습니다.
Global sub-sampled atttention (GSA)
이 방법은 각 윈도를 서프샘플링 하고, 이 서브샘플링된 윈도끼리 상호작용을 하는 것입니다. 이렇게 하면, Global Attention도 되고 계산 복잡도도 줄일 수 있다는 논리입니다(Key와 Value에 대해서만 서프샘플링).
이 대표자를 선정하는 함수는 Average Pooling, Depth-Wise strided convolutions, regular stride convolutions을 사용해 봤는데 여기서 그냥 regular stride convolutions의 성능이 가장 좋았다고 합니다. 이 과정은 Key와 Value의 서브샘플링을 위해 Convolution을 사용하는 PVT의 SR과 동일한데 형식적으로 이름은 SSSA로 지었다고 합니다.
그리고 매 스테이지마다 윈도 사이즈가 작아지는데, 이 서브샘플링의 비율을 동일하게 가져가면 차원이 너무 작아지니, 마지막 3개의 스테이지에 대해 각각 4, 2, 1 비율로 서브샘플링을 하였고, 아래는 SSSA의 전체 연산 과정을 나타낸 것입니다.

먼저, LSA로 Window끼리 지역적인 attention 연산을 해주고, GSA로 각각의 윈도의 상호작용을 해주었습니다. 아울러 아래 그림 (a)는 위 식을 도식화한 것이고, (b)는 GSA에서 윈도우의 서브샘플링이 이루어지는 과정입니다.
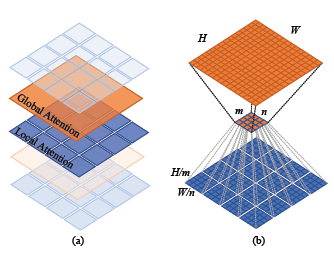
그리고, 이 Twins-SVT도 PCPVT처럼 매 스테이지의 처음에 CPVT를 삽입해 주었습니다. 이렇게 함으로써, 가변적인 사이즈의 입력을 받을 수 있게 되었습니다.
이러한 과정은 SR을 하지만, 이산적인 연산량을 가지는 PVT보다 효과적인 계산 효율성을 가집니다. 그리고, Swin은 Shifted Window를 하기 위해, torch.roll이라는 pytorch에 종속된 함수를 사용하는데, 이러한 함수가 일부 디바이스(모바일)에 대해 메모리 친화적이지 않아 스피드가 느릴 것이랍니다(TensorRT라는 것을 사용하면 1.7배 빠름).
마치며
마치면서 몇 가지 실험 결과를 살펴보겠습니다.
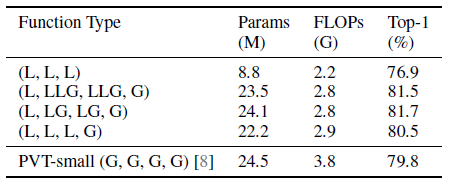
위 그림은 각 Stage에 L은 Local, G는 Global-Attention을 적용한 것인데 확실히 모두 Local만 적용한 것이 윈도끼리의 상호작용이 없어 성능이 많이 낮습니다. 반면, 모두 Global attention을 적용한 PVT보다 적당히 Local attention을 섞은 모델이 더 나은 성능을 기록하였네요.

그리고 위 결과는 CPVT가 Swin에는 효과가 없는 것을 볼 수 있습니다. 이는 Shifted Window이 CPVT에 별 효과가 없는 것으로 결론 지을 수 있습니다.
오늘은 Twins 논문을 리뷰해 보았습니다.
긴 글 읽어주셔서 감사합니다.