[논문리뷰] Masked Autoencoders(MAE) Are Scalable Vision Learners
들어가며
이번에 소개할 논문은 BERT의 자기 지도학습(self-supervised learning) 방식을 컴퓨터 비전에 도입한 masked autoencoders (MAE)입니다. MAE의 장점은 아주 심플하고, 빠르게 훈련되며, 더 정확합니다. 본문에 들어가기 앞서 단 몇 가지만 알면 됩니다.
- 비대칭 Encoder-Decoder: 기존 저희가 알던 Encoder-Decoder 구조는 웬만하면 대칭적인 구조였죠? 근데 본 논문의 MAE는 비대칭적인 구조를 가지게 자기지도학습으로 사전학습(Pre-train)을 합니다. 왜 일까요? 아래의 그림을 살펴봅시다.

만약 저희가 1000-Epoch 동간 자기 지도학습을 했다고 가정합시다. 그 후, 저희는 디코더 부분은 버리고 사전 학습된 인코더 부분만 사용하여 downstream(Segmentation, Object Detection, Classification)에 이용할 것입니다. 여기서 주목할 점은 디코더 부분은 버린다는 것입니다. 그래서 어차피 버릴 건데 시간만 오래 걸리고 그러니까 디코더는 인코더보다 상대적으로 Layer 층을 작게 쌓았습니다. 층을 작게 쌓으니 당연히 속도에도 이점이 있습니다. - Masking: 기존 BERT모델에서 토큰을 마스킹하는 방법을 그대로 가져왔습니다. 여기서 궁금증이 하나 생깁니다. 이미지에서는 어떻게 마스킹을 하느냐입니다. 눈치 빠른 분들을 바로 아셨겠지만 Vision Transformer(ViT)의 모델을 활용합니다. ViT는 BERT에서 사용하는 모델인 Transformer를 Vision에도 적용한 모델입니다. Transformer Encoder로 입력되기 전에 이미지를 패치로 나누는 작업을 하는데 이 패치들을 마스킹 하는 것입니다.
이러한 방식은 큰 수용량을 가진 모델들에 일반화가 잘 됐다고 합니다. 일반적으로는 큰 수용량을 가진 모델들은 데이터에 과적합이 될 확률이 높다고 합니다. 또한 이 방식은 일반 지도 학습으로 사전학습(Pre-training) 시킨 것보다 성능이 더 잘 나왔다고 합니다.
기존 BERT와 MAE 비교
먼저 BERT의 개념을 간략히 설명하자면, 데이터의 일정 부분을 마스킹 한후, Transformer encoder에 입력하여 이 마스킹된 부분을 예측하는 것입니다. 이렇게 간단한 방법으로 수백만이 넘은 파라미터를 가진 모델의 일반화를 가능하게 했습니다.
하지만 이러한 방식은 NLP의 Masked Autoencoder가 동작하는 방식이고, NLP와 Computer Vision은 약간의 차이가 있습니다. Language는 사람의 구어로 만들어내는 신호이고, Image는 공간의 중복성이 큰 자연 신호입니다. 자기 지도학습에서 Language는 한 문장에 대한 정밀한 이해를 바탕으로 마스킹된 단어를 예측을 하는 것이고, 이미지에서는 객체 및 장면 등의 높은 이해 없이 마스킹된 이미지 패치의 근처 패치들만 이용해서 복구할 수 있습니다.

위 그림의 각각 Language와 Image에서 BERT의 자기 지도학습이 사전학습되는 예시입니다.
- Language(왼쪽): 마스킹된 단어 토큰들이 Transformer 인코더에 입력되면, 인코더는 문장, 토큰들 간에 관계, 각 토큰의 명사 등 여러 가지 정밀한 문장에 대한 이해를 필요로 함.
- Image(오른쪽): 마스킹된 이미지 패치 토큰들이 Transformer 인코더에 입력되면, 마스킹된 토큰은 근처 토큰들의 픽셀 정보를 이용하여 쉽게 복구가 가능.
이처럼 기존 Language에서 마스킹된 토큰을 예측하려면 모든 토큰에 대한 정밀한 이해가 필요합니다. 그렇기 때문에 BERT는 마스킹 비율을 15%정도로 작게 가져가 천천히 자가지도학습을 하였습니다. 하지만 이미지에서는 이렇게 작은 비율로 마스킹을 하면 이미지에 대한 풍부한 정보들을 학습하는 것이 아닌, 주변 패치의 픽셀들을 이용하여 복구하는 단순한 정보만 학습한다는 것입니다.
이 차이를 메꾸기 위해, MAE는 한 75% 정도 높은 비율로 이미지 패치에 대한 마스킹을 해버리면 주변 패치의 픽셀들을 이용한 복구가 불가능 해질것이고, 공간의 중복성 또한 줄여져 더 높은 수준으로 풍부한 정보에 대한 학습이 이루어지겠다는 아이디어입니다.

위 사람과 벽의 패치의 질감이 비슷하죠? 이런 것을 공간의 중복성이라고 칭합니다. 만약 사람 얼굴에 마스킹이 되면 저런 벽쪽에 대한 정보를 이용하여 마스킹된 사람 얼굴에 대한 패치의 복구가 가능할 것입니다.
이 두가지로, 모델들을 효과적이고 효율적으로 3배 이상의 학습을 가속화시키고, 정확도 또한 향상한 것입니다.
게다가, 기존 ViT에서도 자가지도학습이 이루어졌는데, 그때는 마스킹, 마스킹 되지않은(비마스킹) 이미지 패치를 모두 Transformer 인코더에 입력이 되었는데 본 논문에서는 오로지 비마스킹 이미지 패치(25%)만 인코더의 입력으로 사용하였습니다.
상대적으로 낮은 Layer를 가진 디코더, 비마스킹된 이미지 패치들만의 인코더 입력 이 두 가지로 3배 정도에 사전 학습을 가속화시켰다고 합니다.
간략한 설명은 이렇고, 이제 어떻게 돌아가는지 살펴보겠습니다.
Masked autoencder (MAE)
MAE는 기존 ViT와 동일한 Encoder-Decoder 구조를 구성하되, "Encoder는 기존과 동일하게 Decoder는 아주 가볍게" 네트워크를 변형시켜 비대칭적인 구조를 가집니다. 전체적인 흐름은 아래와 같습니다.

- 기존 ViT와 동일하게 이미지들을 패치로 나눔
- 나눠진 패치들에 랜덤 하게 마스킹
- 비마스킹된 이미지 패치들만 Encoder로 입력
- 인코더의 출력(latent representation)과 마스킹된 패치들을 결합하고, 디코더에 입력되어 오리지널 이미지를 재구성
뭐 전체적인 내용은 이렇고, 저희가 유심히 봐야할 세부적인 내용은 마스킹을 어떻게 하는지, 인코더와 디코더는 어떻게 구성하는지 를 봐야 합니다. 세부적인 내용은 아래와 같습니다.
Masking
아까 위에서 ViT와 동일하게 나눠진 이미지 패치에서 랜덤하게 마스킹을 한다고 했습니다. 이 마스킹이 진행되는 방법은 아래 그림과 같습니다.
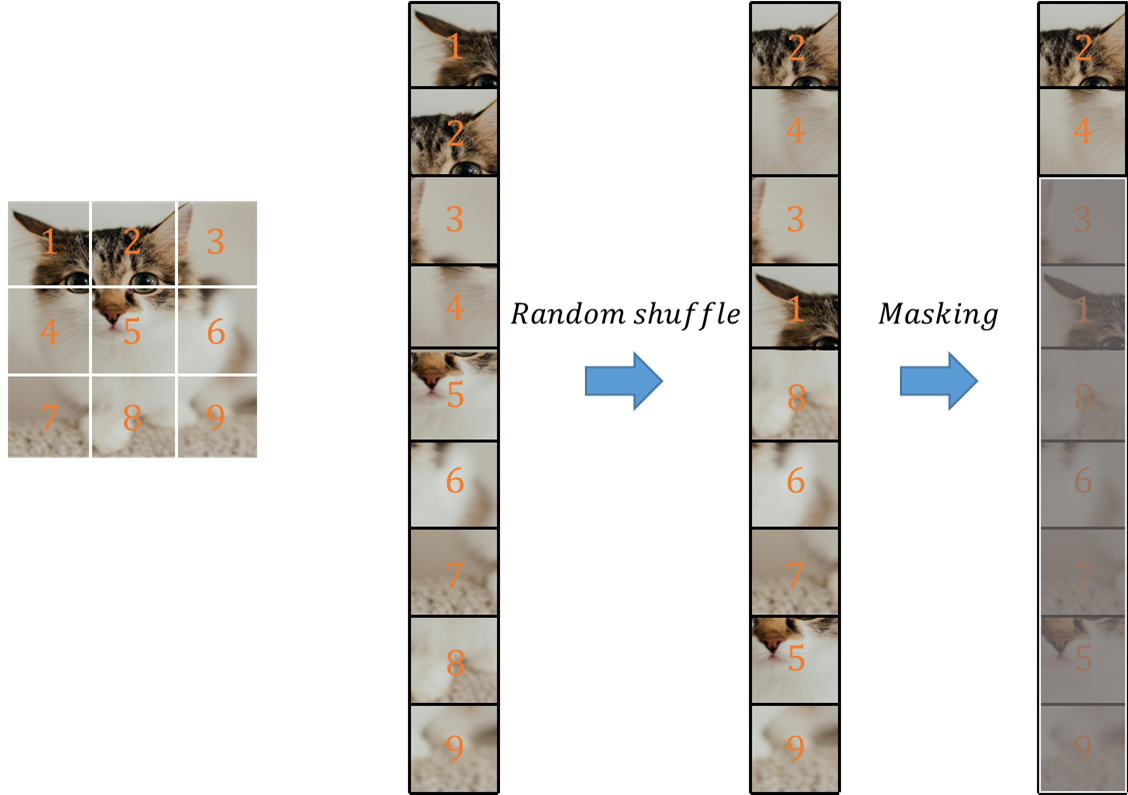
- 먼저, 이미지 별로 패치를 나누고 리스트를 형성합니다.
- 이어서, 이 리스트를 랜덤하게 섞습니다.
- 설정한 마스킹 비율(위 그림에선 7/9)을 기준으로 리스트의 마지막부터 마스킹합니다.
- 최종적으로 비마스킹된 영역([2, 4] 인덱스)들만 인코더의 입력으로 들어갑니다.
위와 같이 마스킹 비율을 아주 크게 가져가서, 이미지 패치 간에 중복성을 제거함으로써 이웃하는 이미지 패치들로 쉽게 원본 이미지를 재구성하는 것을 막고, 인코더가 효율적으로 풍부한 Representations을 학습할 수 있는 기회를 줄 수 있습니다.
MAE Encoder
구조는 ViT와 같습니다. 하지만 기존 ViT와 달리 비마스킹 이미지 패치들만 입력에 사용됩니다. 그러므로, 이 샘플 수만큼의 연산 속도에 이점이 있습니다.

MAE Decoder
디코더의 입력으로는 인코더에서 사용한 비마스킹 이미지 패치들의 출력과, Masking 이미지 패치 둘 다 사용됩니다. 여기서 각 마스킹 이미지 패치는 비마스킹 이미지 패치들의 출력의 정보를 이용하여, 디코더에서 누락된 패치의 존재를 나타내기 위해 학습됩니다.
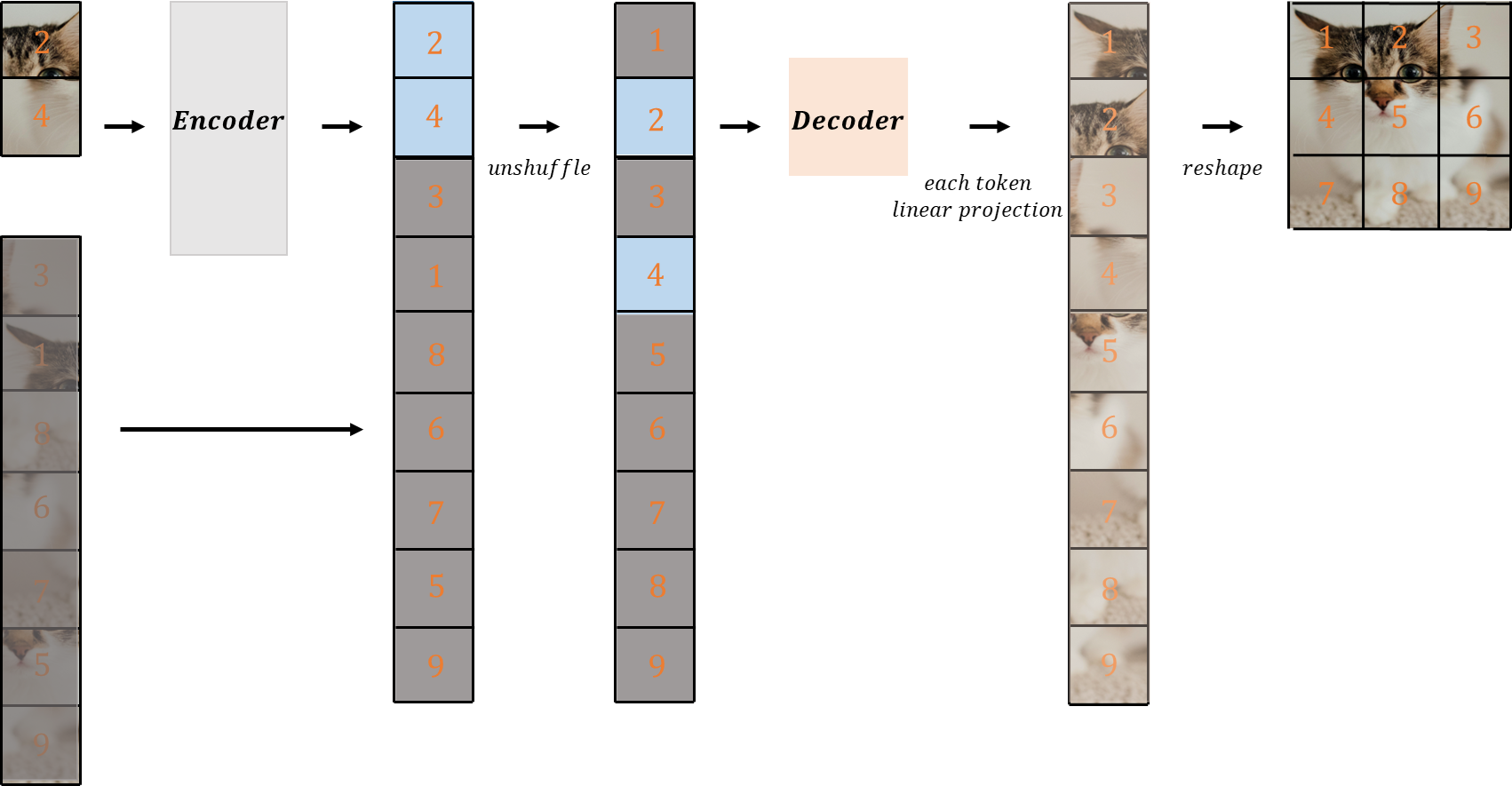
- 위인코더에서 출력된 이미지 토큰들과, 마스킹 토큰들을 결합
- 처음에 섞은 패치들을 원래대로 unshuffle
- 이 모든 토큰들이 디코더로 입력되고(위치 정보가 없기 때문에 Positional embdding이 추가), 디코더에서 출력된 각 토큰이 각 패치의 픽셀수만큼 Linear projection되고, 1자로 펴진 vector들을 reshape 하여 오리지널 이미지를 재구성합니다.
- 재구성된 이미지에는 픽셀별로 mean squared error(MSE)를 적용하며, loss는 오직 마스킹 패치들에 대해서만 적용
디코더에서 전체적인 흐름은 위 그림과 같고 MAE 디코더는 사전 학습에서 오로지 이미지 재구성 작업에만 활용됩니다. 본질적인 목표는 인코더가 인식(Recognition)에 대한 Representations을 학습하는 것에 있으며 디코더는 이것에 대한 보조역할이라 보시면 됩니다. 그렇기 때문에 디코더의 레이어 수는 인코더의 레이어 수에 독립적으로 유연하게 구성할 수 있습니다.
본 논문에서는 이 디코더의 레이어 수를 인코더의 10%로 구성했다고 합니다. 이래서 비대칭적인 구조가 생기고, 아주 가벼운 디코더가 구성이 되었다고 하죠. 이렇게 디코더를 구성하면서 사전학습의 시간을 상당히 줄일 수 있게 되었습니다.
Experiments
ImageNet Experiments
MAE는 2가지 지도 학습으로 자가지도학습의 사전학습에 대한 성능 평가를 합니다.
- Fine-tuning: 사전 학습된 모델의 Weight를 고정하지 않고, downstream task(여기서는 이미지 분류)에 맞게 전체적으로 재학습
- Linear-probing: 사전 학습된 모델의 Weight를 고정한 후, 마지막에 분류 작업할 레이어에 대한 학습만 이루어짐. 이 방법의 경우 사전 학습 모델의 표현력이 상당히 좋아야 성능이 잘 나올 것임.
아래는 top-1 평가에 대한 ViT-L 모델을 기준으로 처음부터 학습시킨 것과 fine-tuning 시킨 것에 대한 결과입니다.

MAE가 확실히 큰 성능 향상을 기록하였습니다. 아무래도 처음부터 학습시킨 결과는 쉽지않고 불안정적입니다. 그리고 ViT-L/H과 같은 큰 모델에 학습할 때 NaN loss가 자주 발생한다고 합니다. 몇 가지 하이퍼 파라미터를 조정하면 76.5에서 82.5까지 성능을 올릴 수 있었다고 합니다(자세한 내용은 논문 참고). 처음부터 학습시킨 것은 200 epochs 돌았고, MAE는 50 epochs 돌았다고 하네요.
Masking ratio
MAE는 75%일 때 linear-probing, fine-tuning 두 평가에서 잘 동작했다고 합니다.

아래는 각 마스킹 비율마다 오리지널 이미지를 예측한 결과입니다.

Masking ratio
아래는 디코더 레이어의 수와 차원마다 변화하는 linear probing과 fine-tuning 결과입니다.
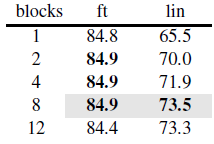
위 표에서 linear probing의 결과는 레이어 층이 깊을수록 상당한 차이를 보입니다. 이것으로 재구성 작업과 인식 작업 사이의 차이가 설명될 수 있습니다. 디코더 레이어의 층이 작으면, 오토 인코더의 마지막 몇몇 레이어의 Representations는 이미지 재구성에 좀 더 특화되어 있을 것이라는 것입니다.

위 그림에서 파란색 레이어는 인식 작업에, 녹색 레이어는 재구성 작업에 각각 특화되어 있습니다. 사전 훈련이 완료된 후, 디코더 부분은 제거되고 인코더 부분만을 사용합니다. 만약 디코더의 레이어 수가 적다면, 인코더의 마지막 레이어 중 일부는 여전히 재구성 작업에 특화된 상태로 남아있게 됩니다. 결과적으로, 이러한 레이어들의 가중치를 고정하는 Linear Probing에서 인식 작업에 적합하지 않아 성능이 저하될 수 있습니다. 하지만 디코더 레이어 수를 늘리면 인코더의 모든 레이어가 인식 작업에 더 잘 맞춰지며, 이에 따라 성능이 향상됩니다.
그러나, 레이어의 Weight를 고정하지 않고 학습시키는 Fine-tuning을 통해 재구성에 특화된 레이어들도 다시 인식 작업에 특화되도록 학습할 수 있습니다. 위의 표에서 볼 수 있듯이, 미세 조정 과정에서는 디코더 레이어 수가 성능에 미치는 영향이 크게 줄어듭니다. 이렇게 Fine-tuning 함으로써 디코더 레이어의 수도 적게 가져가면서, 학습에 추가적인 속도의 이점을 얻을 수 있습니다.
Data augmentation
MAE는 augmentation으로 crop만 사용한다고 합니다. 여담으로 이전 연구들은 이 augmentation에 크게 성능이 좌지우지(13% - 28%) 한다고 하네요.

그래도 random한 크기도 crop 하니까 성능이 약~간 올라가긴 했네요. 뭐 이 정도는 여러 환경에 따라 달라질 수 있으니 유의미하진 않다고 생각합니다. 그리고 애초에 랜덤 하게 이미지 패치를 마스킹하는 것이 augmentation이라고 합니다.
Mask sampling strategy
이번에는 이미지패치에 대한 마스크를 어떻게 할지 입니다.

한마디로 정리하자면, random하게 하는 것이 성능이 가장 잘 나옵니다.
마무리
MAE는 800-epoch 사전학습 됐습니다. 1600까지 학습했는데도 계속해서 성능이 올라갔습니다. 이러한 MAE는 더 큰 모델에서도 꾸준한 성능 향상을 보였으며, 이전 사전훈련모델들과 비교했을 때 더 심플하고, 더 빠른 장점이 있습니다. 지도학습을 한 모델들과도 비교했을 때, 더 나은 성능을 보였다고 합니다.
MAE는 다른 downstream(Instance Segmentation, Object Detection, Semantic Segmentation)에 전이학습을 하였을 때도 좋은 성능을 보였습니다.
오늘은 컴퓨터 비전에서 사용하는 self-supervised learning 논문인 MAE 한 번 리뷰해 보았습니다.
자세한 내용은 본 논문을 참고하시고, 언제나 게시글에 대한 피드백은 환영입니다.
긴 글 읽어주셔서 감사합니다.