[논문리뷰] VAE(Variational Auto-Encoder)
들어가며
오늘 리뷰해 볼 논문은 생성형 모델의 하나인 Variational Auto-Encoder(VAE)입니다. 이 논문은 현재 Diffusion 모델의 토대인 모델인 만큼 아주 중요한 모델입니다. 먼저 이 논문의 제목을 보면 Auto-Encoder라는 말이 있습니다. 이 Auto-Encoder가 뭘까요?

위와 같이 Auto-Encoder는 입력 차원과 출력 차원이 같다는 점이 있습니다. 근데 이걸 왜 하느냐 하면 근본적인 이유는 차원 축소에 있습니다.
본래 차원 축소는 비지도학습으로 이루어졌습니다. 하지만, Auto-Encoder의 경우는 Input x가 입력되고 Encoder뒤에 Decoder를 붙여서 입력과 출력이 같은 구조를 만들고, z가 비지도학습이 아닌 지도학습으로 차원 축소를 이루어내며 크게 각광받았습니다.
VAE는 이 Auto-Encoder와 네트워크 구조가 똑같이 생겼습니다. 하지만 이 탄생 과정은 연관성이 하나도 없습니다. 천천히 살펴보겠습니다.
Maximum Likelihood(ML)
먼저, VAE를 설명하기 앞서 아니라 모든 생성형 모델이 하고자 하는 것은 Maximum Likelihood(ML)의 원리를 기반으로 학습합니다.
여기서 Likelihood란, 데이터를 가장 잘 설명할 수 있는 특정 분포를 이야기합니다. 예를 들어 3개의 가우시안 분포가 있다고 가정하고, 3개의 데이터(빨간 점)가 아래와 같이 있다고 가정하면 아래 그림과 같이 표현할 수 있습니다.
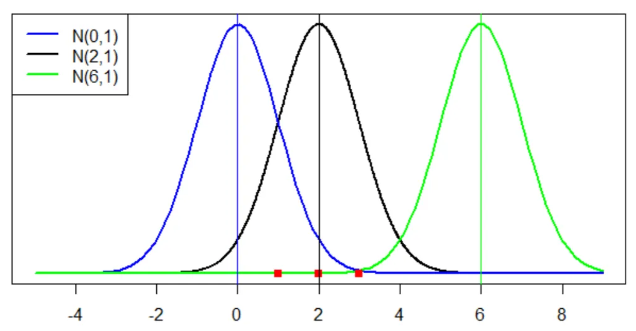
그럼 데이터 X에 대한 Likelihood(L)을 구하면 아래와 같은 식은 총 3가지 가우시안 분포에 대한 식이 나옵니다.

위와 같은 식으로 데이터를 각각의 Likelihood를 구해, 가장 높은 값을 가지는 분포가 데이터를 가장 잘 설명한다고 할 수 있습니다.
자 그럼 위의 식을 그대로 딥러닝에 적용하여, 아래와 같이 파라미터 \( \theta_1 \)으로 학습된 모델 \(f_{\theta_1}(x) \)와 \( \theta_2 \)으로 학습된 모델 \(f_{\theta_2}(x) \)이 있을 때 두 모델 중 어느 것이 likelihood가 높을까요? 분포는 강아지, 고양이를 분류하는 이진 분류인 베르누이 분포로 가정하겠습니다.

likelihood는 아래의 모델이 높을 것을 확인할 수 있습니다. 전체 데이터 표본에 대한 수식으로 표현하면 아래와 같습니다

위 식은 연속된 곱셈으로 미분에 어려움이 있기 때문에, log와 -를 취해서 그 값이 최소가 되는 값을 구하는 것이 Maximum Likelihood입니다.

VAE
개요
전술한 바와 같이, 생성형 모델은 Maximum Likelihood의 원리를 기반으로 동작합니다. 그중에서도 분포를 사전 정의하는 것과, 그렇지 않은 모델이 있는데 VAE 같은 경우에는 분포를 사전 정의 하는 생성형 모델입니다.
여기서 사전 정의된 분포는 보통 가우시안이나 베르누이로 가정합니다. 이건 모델의 구조를 설명하면서 더 자세히 다루도록 하겠습니다.
이 생성 모델은 어떠한 랜덤 변수(z)를 입력으로 할 때 마다, 데이터 표본에서 한 이미지를 출력으로 하는 것을 목적으로 합니다. 그래서 이 z 변경할 때 마다 랜덤 한 이미지를 생성하면 잘 학습된 모델이라고 볼 수 있습니다.
하지만, 이 랜덤 변수(z)를 변경할 때마다 데이터 표본에서 임의의 이미지를 출력하는 것이 아닌, z를 컨트롤 가능하여 데이터 표본의 이미지도 내가 적절하게 컨트롤이 가능하면 더욱 좋겠죠. 그래서 본 논문에서는 이 z를 샘플링하기 용이하게 하려고, 가우시안 분포를 샘플링 함수에 대한 사전 분포를 정의하여 샘플링하는 방식을 사용합니다.
그리고 이 샘플링 하는 방식으로, " 샘플링된 z가 생성 모델을 통과하여(\( g_{\theta}(z) \)) 생성된 이미지와 기존 데이터 표본에 있는 하나의 이미지 x에 대한 Likelihood 값을 최대로 하는 방향으로 생성 모델을 학습하면, 이미지를 잘 컨트롤할 수 있을 거다"라는 아이디어로 아래와 같이 생성 모델을 구성하였습니다.

하지만, 이러한 방식으로 구성하니 데이터 표본에 있는 데이터조차 잘 생성하지 못했습니다.
아까 VAE는 모든 분포를 사전 정의한다고 말씀드린 거 기억하시나요? 그래서 z를 샘플링하는 \( p(z) \) 함수도 가우시안 분포로 사전 정의 하였습니다.
그렇다면 저희가 궁극적으로 구하려 하는 p(x)에 대한 분포도 가우시안으로 사전 정의할 수 있고, Maximum Likelihood를 구한다는 관점에서 가우시안 분포는 Mean Squared Error(MSE)의 문제로 해석할 수 있습니다 (+더 보기).

문제점
근데 이런 식으로 Maximum Likelihood를 구하면 아래와 같은 문제점이 발생합니다.

위 그림에서는 데이터 표본의 이미지(a)와 샘플링된 z를 Generator 모델에 입력하여 생성된 이미지(b, c)가 있습니다. (b)는 약간의 잘린 것이고, (c)는 약간의 화소만큼 옆으로 Shift 된 것입니다. 사람의 관점으로 봤을 때 (c)가 잘 생성된 이미지이지만 픽셀별 MSE 문제로 해석할 때 (b)가 더 적합한 이미지로 학습이 됩니다. 이렇게 되면 데이터 표본의 이미지도 생성하지 못하는 큰 문제점이 생깁니다.
이러한 문제점으로 생각해 낸 것은 "단순하게 정의한 가우시안 샘플링 함수(사전 분포)로 샘플링을 하여 이미지를 생성하니, x 조차 생성하지 못하였다. 그래서, 어떤 이상적인 샘플링 함수를 정의하여 최소한 데이터 표본 x에 대한 이미지는 잘 생성해 주는 게 하자."라는 결론이 도출됩니다.
Variational Inference
위에서 x에 대한 이미지는 생성하여 최소한의 성능을 보장해 주는 어떤 이상적인 샘플링 함수가 필요하다고 했습니다. 기존 임의의 가우시안 분포에서 단순하게 z를 샘플링( \(z \sim p(z) \))가 아닌, "x를 Evidence로 보여주는 어떤 샘플링 함수를 정의하고 z를 샘플링을 하면 (\( z \sim p(z|x) \)) , 데이터 표본 x에 대한 최소한의 성능은 보장해 줄 것이다."가 메인 아이디어입니다.
근데 이 데이터 표본 x를 Evidence로 보여줬을 때에 대한 이상적인 샘플링 함수가 무엇인지는 알 수 없습니다. 그래서 이 샘플링 함수를 어떤 간단한 분포(e.g. 가우시안)로 근사 시키는 것이 Variational Inference입니다.

- 여기서 True Posterior는 데이터 x를 바탕으로 만들어진 이상적인 함수 즉, \( p(z|x) \)이며 구할 수가 없습니다.
- 그래서 이 True Posterior인 \( p(z|x) \)를 근사하기 위한 함수 가우시안 분포를 정의하고, 평균 (\( \mu \)) 과 분산 (\( \sigma \)) 을 바꿔가며 최대한 근사 시킨다(Variational Inference).
그럼 이 평균(\( \mu \))과 분산(\( \sigma \))을 어떻게 바꾸며 근사할 것이냐? 이게 어려우니 딥러닝 모델을 사용하는 것입니다. x를 입력으로 넣어서 출력으로 \( \mu \)와 \( \sigma \)를 예측하고, 파라미터를 조정하여 최적의 \( \mu \)와 \( \sigma \)를 예측하여, 가우시안 분포를 True Posterior에 근사 시키는 것입니다.
그럼 이제 생성 모델은 기존에 있던 \( g_{\theta} (x|z) \)와 이상적인 샘플링 함수 \( p(z|x) \)를 근사하는 Variable Inference 모델 \( q_{\phi} (z|x) \), 두 네트워크가 구성이 됩니다.

이제 우리가 아는 Auto-Encoder와 동일한 구조가 구성이 되었습니다. 처음부터 Auto-Encoder로 접근한 것이 아니라 최적의 생성모델을 만드려고 하다 보니 동일한 구조로 변형된 것입니다. Encoder에서 적어도 x에 대한 성능이 보장이 되는 최적의 샘플링 함수를 만들기 위해 \( \mu \)와 \( \sigma \)를 추정하여 가우시안 함수를 구성합니다. 이 이미지 x에 대한 최소한의 성능은 보장하면서, 이미지를 잘 컨트롤하여 여러 이미지를 생성하기 위해 z를 샘플링합니다. 이제 이 z를 Decoder에 입력하여 다시 x 이미지를 생성합니다.
자 이제 네트워크 구성은 이렇게 끝났습니다.
ELBO(Evidence LowerBOund)
네트워크 구성이 끝났으니, 이제 loss함수를 구성해야 합니다. 저희의 본래 목적은 입력 데이터 x를 넣었을 때, 이 데이터를 가장 잘 생성해 내는 함수 \( p(x) \)의 ML를 구하는 것입니다. 앞서 전술했듯이 미분의 편의를 위해 \( log \)를 취해 ML을 구하는 것으로 해석할 수 있습니다.
본 논문에서는 \( p(x) \)와 True Posterior \(p(z|x) \), Variance Inference \( q_{\phi} (z|x) \), 이 3가지 관계식을 가지고 loss 함수를 아래와 같이 유도하였습니다.

수식 유도 과정은 위와 같고, 유심히 봐야 할 것은 아래 ELBO와 KL입니다. KL은 두 확률분포 간의 거리이며, 항상 양수의 값을 가집니다. KL 안의 두 확률 분포를 보면 x를 Evidence로 준 True Posterior \( p(z|x) \)와 이것을 Variational Inference 하는 \( q_{\phi}(z|x) \)입니다.
이 식을 직접적으로 구할 순 없지만, p(x)에 대한 ML = ELBO + KL 알 수 있고, KL은 항상 양수의 값을 가진다는 것을 알 수 있습니다. 그렇다면, ML = ELBO가 되도록 ELBO의 값을 ML에 최대한 가깝게 만들면, KL은 저절로 0에 수렴하게 되고 이 말은 즉슨 \( q_{\phi} (z|x) \)는 True Posterior로 수렴한다는 것입니다. 이 ELBO를 다시 정리하면 아래와 같습니다.

여기서 앞에 식의 \( p(x|z) \)는 z가 주어졌을 때 x를 생성하는 이상적인 함수이고, \( p(z) \)는 z를 샘플링하는 어떤 함수(e.g. 가우시안)입니다. 본 논문에서 이미지 생성 함수 \( p(x|z) \)는 \( \theta \)를 최적화하는 \( g_{\theta} (x|z) \)의 ML를 구하는 것입니다.
그렇다면 \( p(z) \)는 뭘까요? 서로 다른 이미지 x가 \( q_{\phi}(z|x) \)에 입력되면, 서로 다른 가우시안 분포를 출력할 것입니다. 이 서로 다른 가우시안들을 하나의 샘플링 함수 \( p(z) \)에 정규화시켜 샘플링 함수를 다루기 쉽게 하는 것입니다.
그럼 \( p(x|z) \)를 \( g_{\theta}(x|z) \)로 변경하고, \( p(z) \)는 평균이 0이고 분산이 1인 가우시안 분포 \( N(0, 1) \)로 가정하고, 양변을 음수로 바꿔 최적화 문제로 변경하면 아래와 같이 최종식이 나옵니다.

앞에 식은 x를 인코더에 입력하고, 디코더에서 x를 생성하기 때문에 Reconstruction error라는 이름이 붙었고, 뒤에 식은 서로 다른 가우시안을 하나의 샘플링 함수(위에서는 표준 정규 분포)로 정규화시켰기 때문에 Regularization error라는 이름이 붙었습니다.
Loss Function
자 이제 학습입니다. 먼저, 뒤에 Regularization error를 계산하는 것은 그냥 두 가우시안에 대한 KL을 구하는 공식이 있습니다. 하지만, Reconstruction error는 학습 과정에서 구할 수가 없습니다.
본 논문은 앞서 말했듯이, 인코더는 \( \mu \)와 \( \sigma \)를 출력하고 이 가우시안 분포에서 랜덤 하게 샘플링하여 디코더로 입력됩니다. 근데 이렇게 랜덤 하게 변화되는 값을 Backpropagation을 할 수 없습니다. 그러므로 학습이 이루어질 수가 없습니다.
본 논문에서는 이 과정을 Reparameterization Trick을 사용하여 해결하였습니다. 이 과정은 아래와 같습니다.

단순하게 인코더에서 출력된 \( \mu \)와 \( \sigma \)에 표준 정규 분포에서 랜덤 하게 샘플링된 값을 곱해줌으로써 Backpropagation을 가능하게 하였습니다. 이 과정은 아래 코드로 보시는 게 더 쉬울 것입니다.
import torch
def reparameterize(mu, sigma):
eps = torch.randn_like(std) # 평균이 0이고 분산이 1인 표준 정규 분포에서 무작위 샘플링
return mu + eps*sigma # 재매개변수화된 샘플
x = torch.randn((1, 3, 28, 28)) # 랜덤 이미지 (Batch, Channels, Height, Width)
mu, sigma = vae_encoder(x) # 인코더에서 출력된 평균과 분산
z = reparameterize(mu, sigma) # 재매개변수화를 통한 샘플링
이렇게 해서 전체 구조는 아래와 같이 구성됩니다.

가우시안 분포를 가진다고 가정한 인코더 및 디코더와 분산은 1로 고정하고 평균만 예측한다고 예시를 들었을 시, 위와 같은 Reconstruction Error와 Regularization 이 나옵니다. 전술했듯이, Reconstruction Error는 가우시안 분포일 때 위와 같이 픽셀 간 MSE와 같은 형태가 나오고, Regularization은 두 가우시안 분포의 KL에 따라 위와 같은 식이 나옵니다.
이 분포는 가우시안뿐만 아니라 베르누이로도 가정할 수 있고 보통 계산의 편의를 위해 가우시안, 베르누이 두 분포만 사용한다고 합니다.
오늘은 VAE의 리뷰를 해보았습니다.
긴 글 읽어주셔서 감사합니다.