[논문리뷰] Denoising Diffusion Probabilistic Models (DDPM)
들어가며
VAE 참고 논문 링크:
[논문리뷰] VAE(Variational Auto-Encoder)
들어가며 오늘 리뷰해 볼 논문은 생성형 모델의 하나인 Variational Auto-Encoder(VAE)입니다. 이 논문은 현재 Diffusion 모델의 토대인 모델인 만큼 아주 중요한 모델입니다. 먼저 이 논문의 제목을 보면 Au
lcyking.tistory.com
이 글은 VAE의 사전 지식이 있다 가정하에 설명을 진행하려 합니다. VAE를 모른다면 이해에 많은 어려움이 있을 수 있으므로, 꼭 한 번 보고 오시는 것을 추천합니다. 하물며, 유명하고 오래된 논문이라 영상이나 포스터가 많이 올라와있으니 참고하시길 바랍니다.
Diffusion 이란?
Diffusion은 VAE, GAN과 같은 이미지 생성 모델입니다. 최근에 많이 각광받고 있는 모델이죠.
그럼 이 Diffusion이란 어원은 어디서 왔냐? 원래는 물리, 화학 쪽에서 유래되었으며 직역하면 '확산'이라는 뜻이고, 특정한 물질이 조금씩 번지면서 농도가 높은 영역에서 낮은 영역으로 이동하는 것입니다.

그럼 이 Diffusion이 어떻게 이미지에 사용되냐하면 아래와 같습니다.

기존 데이터인 이미지에서 가우시안 노이즈를 점진적으로 가하는 절차를 Diffusion이라고 합니다. 이 절차가 점진적으로 진행되면, 가우시안 노이즈가 점차 확산되면서 전체 이미지의 분포는 가우시안 분포와 가까워질 것입니다.
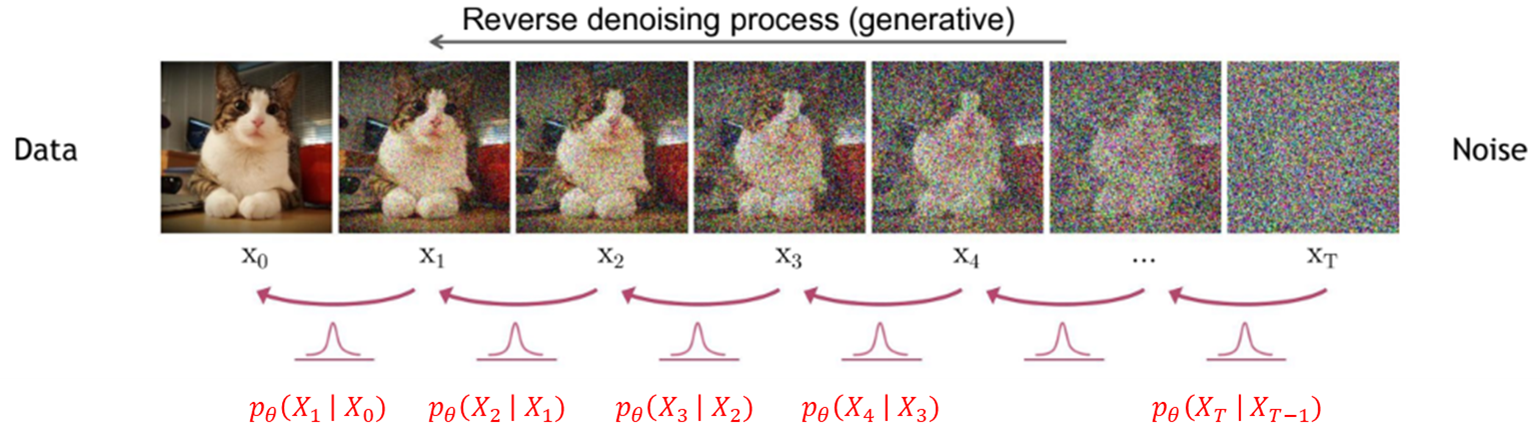
그럼 이 것을 왜하냐? 저희가 중심적으로 봐야 할 것은 이 부분이 아닙니다. 아래의 그림을 보시면 DDPM은 Diffusion 절차뿐만 아니라 하나의 절차가 더 있습니다.

위와 같이 노이즈 이미지를 기존 이미지를 복원하는 과정인 Denoising 절차가 이 논문의 핵심입니다. 이 Denoising 절차에서 기존 생성 모델들의 목적과 같이 Likelihood를 최대로 하는 것이죠.
이와 같이 DDPM은 Forward 과정인 Diffusion Process와 Reverse 과정인 Denoising Process 두 개의 과정으로 분리됩니다. 일단은 Diffusion은 사전 정의하는 것이고, Denoising은 학습해야 하는 것, 이 두가지만 기억하시면 됩니다. 자세한 과정은 뒤에서 설명하도록 하겠습니다.
Markov Chain
본 논문에서 Diffusion, Denoising 과정은 Markov Chain의 형태를 가집니다. 여기서 Markov Chain이란 Markov 성질을 가지는 이산 확률 과정을 뜻합니다.
- Markov 성질: "특정 상태의 확률(t+1)은 오직 바로 과거(t)의 상태에만 의존한다" -> 내일의 날씨(t+1)는 오늘의 날씨만 보고 예측이 가능하다.
- 이산 확률 과정: 이산적인 시간(오늘, 어제, 그제,...) 속에서 확률적 현상
정리하자면 Markov Chain은 다음과 같이 나타낼 수 있습니다.

Markov Chain이 두 과정에 어떻게 쓰이는지 그림으로 살펴보겠습니다.

DDPM은 점진적으로 Diffusion 과정과 Denoising 과정이 일어납니다. Diffusion 과정에서 \( x_1 \)은 \( x_0 \)에 노이즈를 가한 것이고, \( x_2 \)은 \( x_1 \)에 가한 것으로 계속해서 \( x_T \)은 \( x_{T-1} \)에 노이즈를 가해 최종적인 Diffusion 과정이 일어납니다. Denoising 과정도 이 역순으로 일어난 것이고요.
여기서 모든 노이즈 이미지는 이전 이미지의 상태에만 의존하여, Diffusion 하거나 Denoising 합니다. 이 과정이 Markov chain의 수식과 동일합니다.
여담으로 위 과정에서 Markov chain의 과정을 없애고, 단순하게 \( q(z|x) \)와 \( P_{\theta} (x|z) \)만을 구성하면, VAE 구조와 동일해집니다.
Denoising Diffusion Probabilistic Models(DDPM)
자 드디어 모델에 구조를 설명하는 파트로 진입하였습니다. 수식이 많이 포함되나 꼭 전체 증명 과정을 알 필요는 없다고 생각합니다. 하나, 관심 있으신 분들은 중간중간 +더 보기를 클릭하여 증명과정을 확인해 보시길 바랍니다.
Forward Diffusion Process
먼저 Forward 과정인 Diffusion Process입니다.

전술했듯이 Diffusion에서 가우시안 노이즈를 더하는 과정은 사전 정의한 값(\( \beta_t \))으로 진행합니다(여기서 \( \beta_t \)는 t시점의 \( beta \) 값이며 뒤로 갈수록 커짐). 노이즈를 더하는 과정은 아래와 같은 식으로 진행됩니다.

왼쪽 항은 위에서 정의한 마르코브 성질이죠? 오른쪽 항은 가우시안 노이즈를 가하는 과정인데, 이전 이미지 \( X_{t-1} \)를 \( \sqrt {1-\beta_t} \)만큼 누그러뜨리고, \( \beta_t \mathbf {I} \)만큼 노이즈를 더하는 것입니다. 위에서 \( \sqrt {1-\beta_t} X_{t-1} \)와 \( \beta_t \mathbf {I} \)는 \( q(X_t | X_{t-1}) \)라는 가우시안 분포의 평균과 분산으로 해석할 수 있습니다.
이 가우시안 분포에서 VAE와 동일하게 Reparameterization trick으로 샘플링 합니다. 자 그럼 이 식을 그대로 마르코브 체인으로 연결하면, \( x_0 \)부터 \( x_T \)까지를 구할 수 있습니다.

위 식에서 \( q(X_{1:T}) \)는 1부터 T까지의 joint distribution입니다. 근데 마르코브 체인을 사용하지 않고, 아래와 같이 한 번에 구할수도 있습니다. 이따가 loss 함수의 수식 유도할 때 사용됩니다.

Reverse Denoising Process
이제 본격적으로 Reverse 과정인 Denoising Process 입니다. 전술한 바와 같이 생성 모델은 데이터 X에 대한 Likelihood인 최대로 하는 것은 공통적으로 같습니다. 그럼 VAE와 같이 베르누이나 가우시안 같은 분포를 정해놓고, Maximum Likelihood를 구해야하는데 어떤 분포를 정의할지에 대한 의문점이 생깁니다.
근데 이것은 이미 답이 정해져 있습니다. Forward 과정이 가우시안 분포이면, Reverse 과정도 가우시안 분포라는 것이 이전 연구에서 증명되었습니다(Feller et al.).
그럼 이제 Reverse \( q(x_{t-1} | x_t) \)도 가우시안이라는 것도 알았고, Maximum Likelihood를 구하면 되는데 이 Reverse에 대한 평균과 분산을 알기가 쉽지 않습니다. 그렇기 때문에 딥러닝 모델을 사용하여 평균과 분산을 구하고, \( q(x_{t-1} | x_t) \)에 근사하는 방식으로 진행하는 것이 핵심입니다.
위 과정을 T시점부터 0시점까지 마르코브 체인으로 연결하면 아래와 같은 식이 나옵니다.

여기서 가우시안 분포 \( p(X_T) \)는 \( X_0 \) 이미지에서 수많은 노이즈화 과정으로, 거의 완전한 가우시안 분포를 띄는 것으로 해석할 수 있습니다.
Loss
이제 저희는 위의 딥러닝 모델로 예측한 가우시안을 Markov chain으로 연결하여, 최종적으로 기존 이미지인 \( x_0 \)에 대한 Likelihood를 최대화해야 합니다. VAE와 동일하게 Negative log likelihood \( \mathbb {E}_{X_T \sim q(X_T | X_0)} [-log p_{\theta} (X_0)] \)를 최소화하는 방향으로 진행하면 아래와 같이 총 3개의 식이 나옵니다.

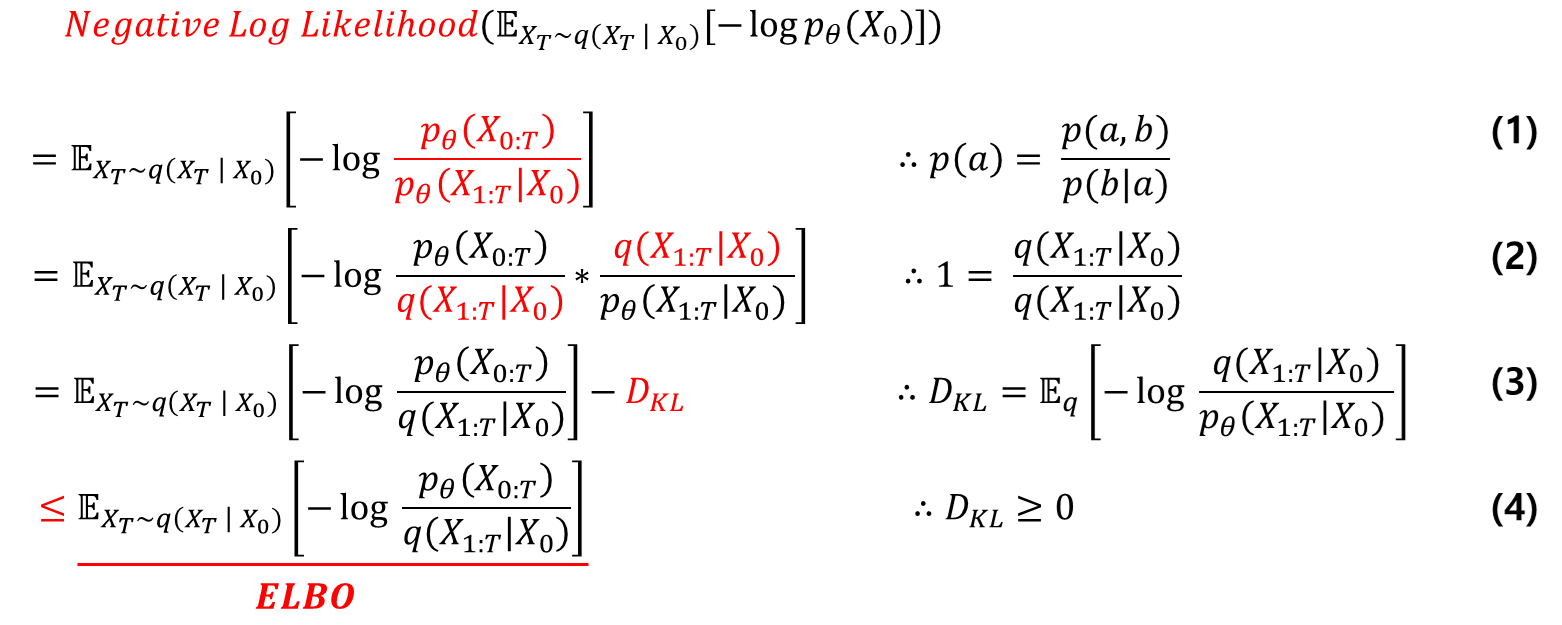
1. 베이즈정리의 \(a = X_0 \), \(b = X_{1:T} \)를 삽입.
2. \(q(X_{1:T} | X_0) \)를 분모 분자에 곱해줌.
3. 2번에서 정리한 식으로 KL-Divergence 식을 유도할 수 있음.
4. 4번의 식은 3번의 식보다 같거나 큼으로, ELBO로 사용
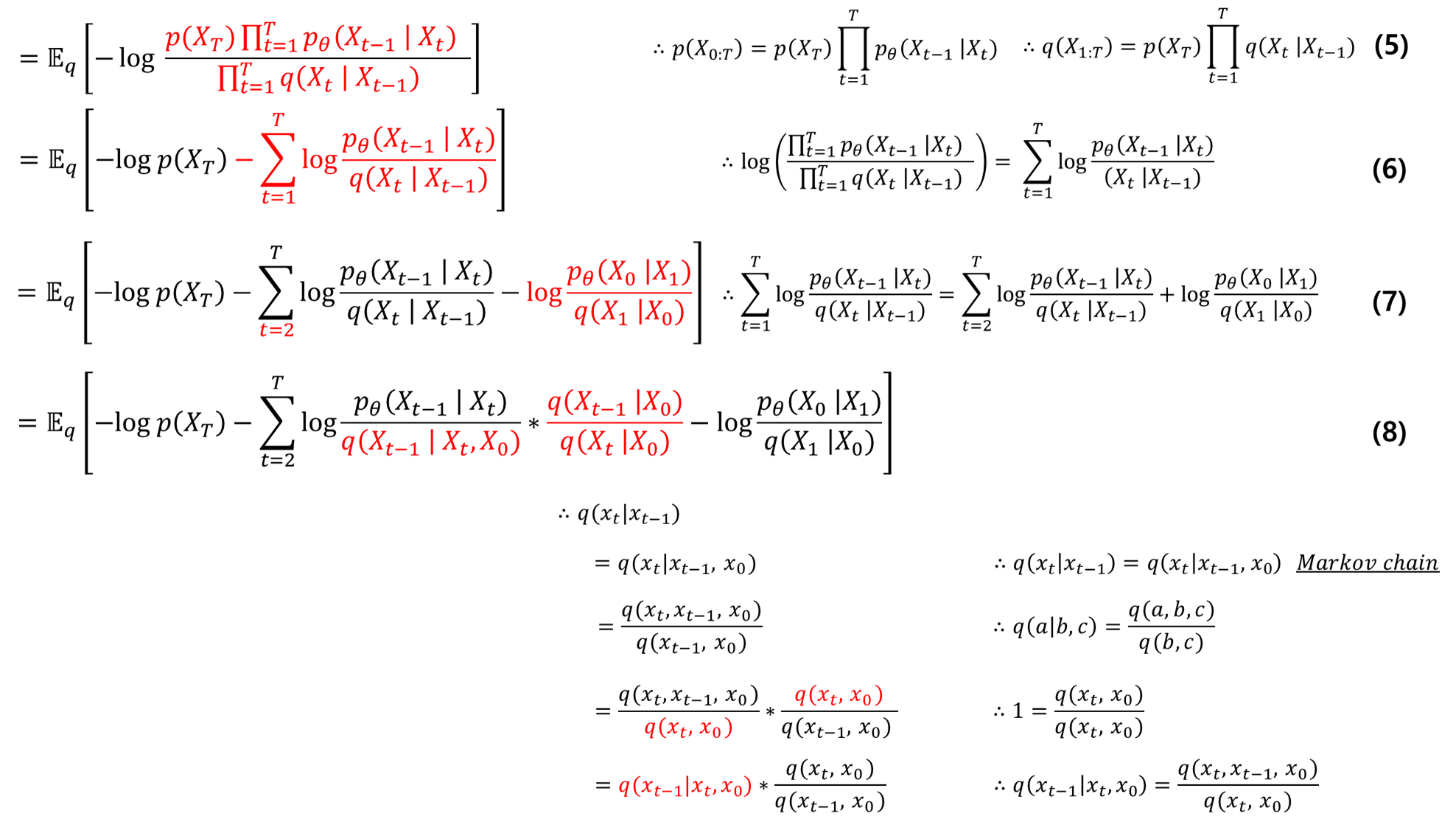
5. 4번 식을 markov chain을 사용하여 풀 수 있음
6. log 안의 식을 분리
7. 시그마 안의 t=1식을 분리
8. ->\( q( x_t | x_{t-1} ) \)를 Markov chain을 이용하여 \( q(x_t | x_{t-1}, x_0 ) \) 로 재정의
-> 베이즈정리
-> 분모 분자에 \( q(x_t, x_0) \)를 곱해줌
-> 베이즈정리

9. log의 성질로 곱을 합으로 분해
10. 시그마 전개하면 위와 같은 식이 나옴
11. 분자와 분모 약분(빨간색)하고, log의 성질을 이용하여 \( q(X_T | X_0) \)항을 앞으로 뺌(파란색)
최종적으로 기대값 \( \mathbb {E}_q \)에 대한 2개의 KL-Divergence와 log항이 도출됨

- Regularization: 어디서 많이 본 용어죠? 맞습니다 VAE의 Regularization Error에서 따온 것입니다. \( X_0 \)과 \( X_T \)를 각각 \( x\)와 \(z \)로 생각하면, VAE와 같은 수식이 완성됩니다.
- Reconstruction: 마찬가지로 VAE의 Reconstruction Error에서 따온 것입니다. \( X_0 \)과 \( X_1 \)를 각각 \( x\) 와 \(z \)로 생각하면, VAE와 같은 수식이 완성됩니다.
- Denoising: 이 Loss가 바로 핵심입니다. 본 논문의 모든 Denoising 절차에 대한 Loss를 합한 것입니다(수식을 보면 \( \Sigma \)가 포함되어 있음).
Regularization
사실상 이 Regularization Error은 필요가 없습니다. VAE는 prior distribution을 \( N(0, 1) \)로 고정하고, \(q(X_T|X_0)\)와 KL-Divergence로 정규화 과정을 진행했습니다.

\( X_0 \) 이미지를 수많은 노이즈화를 진행시켜, \( X_T \)를 만들면, 완전한 노이즈 형태가 형성되고 이는 \( N(0, 1) \)와 비슷한 형태의 가우시안 분포를 띈다는 것입니다. 아래는 실제로 \( \beta_1 = 10^-4,..., \beta_T = 0.02 \)로 쭉 노이즈를 씌우면 아래와 같은 형태를 띱니다.

\( q(X_T|X_0) \approx p(X_T) \) 가 되므로 이 Regularization Error term은 학습에서 제외합니다.
Denoising
Denosing Error의 식은 앞에 시그마 단은 떼고 가져오면 아래와 같습니다.

먼저 q와 p는 둘 다 가우시안 분포이므로, 이미 정해져있는 두 가우시안 분포에 대한 KL-Divergence를 구하는 식으로 아래와 같이 나타낼 수 있습니다.

자 여기서 처음에 Diffusion 과정에서 노이즈를 넣던 수식을 생각해 봅시다. \( q(X_t | X_{t-1}) = N(X_t; \sqrt {1-\beta_t} X_{t-1}, \beta_t I )\)입니다. 여기서 분산 부분을 사전 정의된 \( \beta_t \) 만큼의 분산으로 가우시안 노이즈가 씌워지는 것을 볼 수 있습니다. 이렇게 사전 정의된 값에 대해서는 굳이 학습으로 구할필요가 없기 때문에, 데이터의 분포를 알아내기 위한 평균만을 학습으로 구하는 것으로 간추려 집니다.

두 평균에 대한 MSE 문제로 식이 간단해졌습니다. 그리고 \( \hat {\mu_t}(X_t, X_0) \)와 \( \mu_{\theta} (X_t, t) \)는 아래와 같이 나타낼 수 있습니다.

다음 대입하면 아래와 같은 간단한 수식으로 Loss가 구성됩니다.

참고용
아래는 초반부에 정의한 \( X_0 \)에서 \( X_t \)에 대한 가우시안 분포를 구하는 식
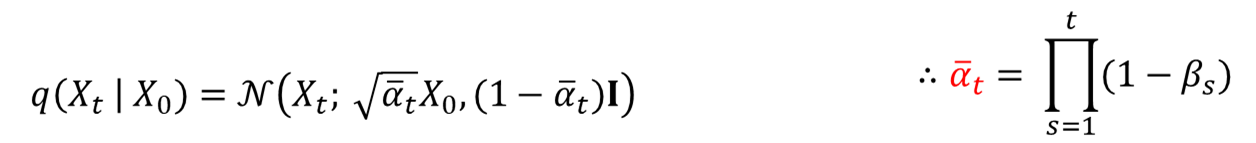
\( q(X_{t-1} | X_t, X_0) \) 평균 계산 증명
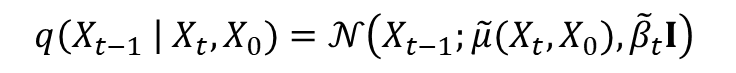
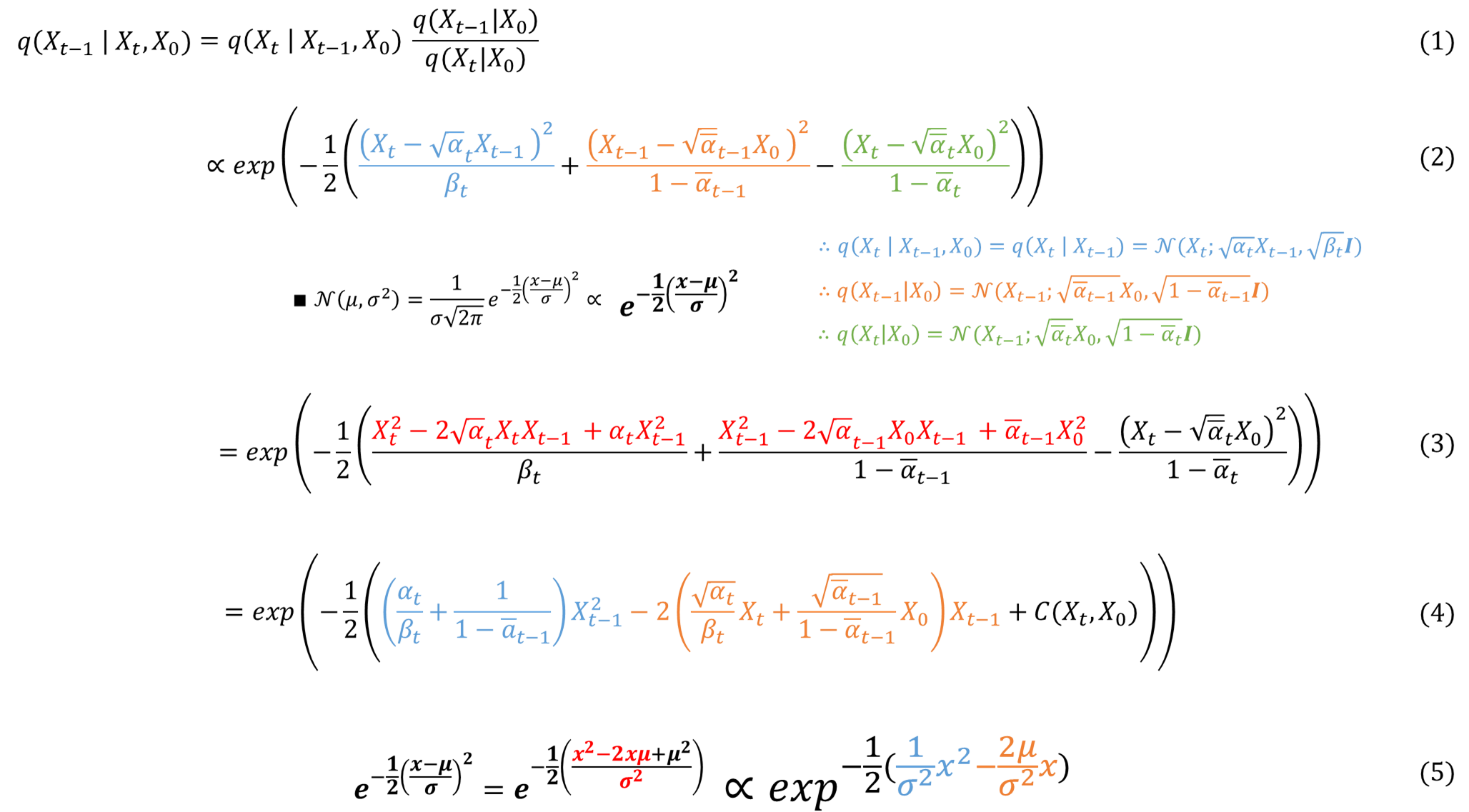
- 베이즈정리
- 가우시안 함수에 앞에 정규화 상수 부분을 떼고, 각 \( q \) 함수에 대한 평균과 분산을 대입
- 분자들을 분배 법칙으로 품
- \( X_{t-1} \) 항으로 묶음(C는 상수의 항)
- 최종적으로 \( X^2_{t-1} \)항 안에 식은 \(1/ \sigma^2 \)가 되고, \( X_{t-1} \)항 안에 식은 \(\mu/ \sigma^2 \)가 됨
위의 식이 도출이 되었으니, \(1/ \sigma^2 \)에 역수를 취해 먼저 분산(\( \tilde {\beta}_t \) )부터 구하면 아래와 같습니다.
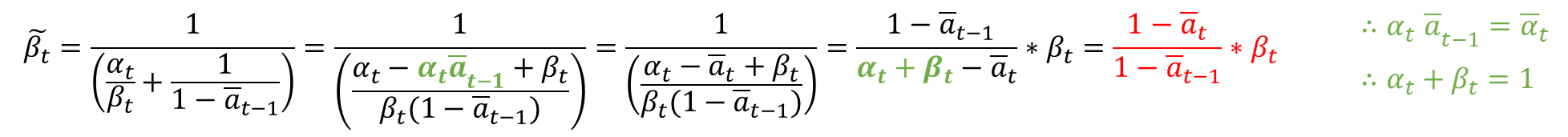
평균(\( \bar {\mu}_t (X_t, X_0) \))을 구하는 식은 아래와 같습니다.
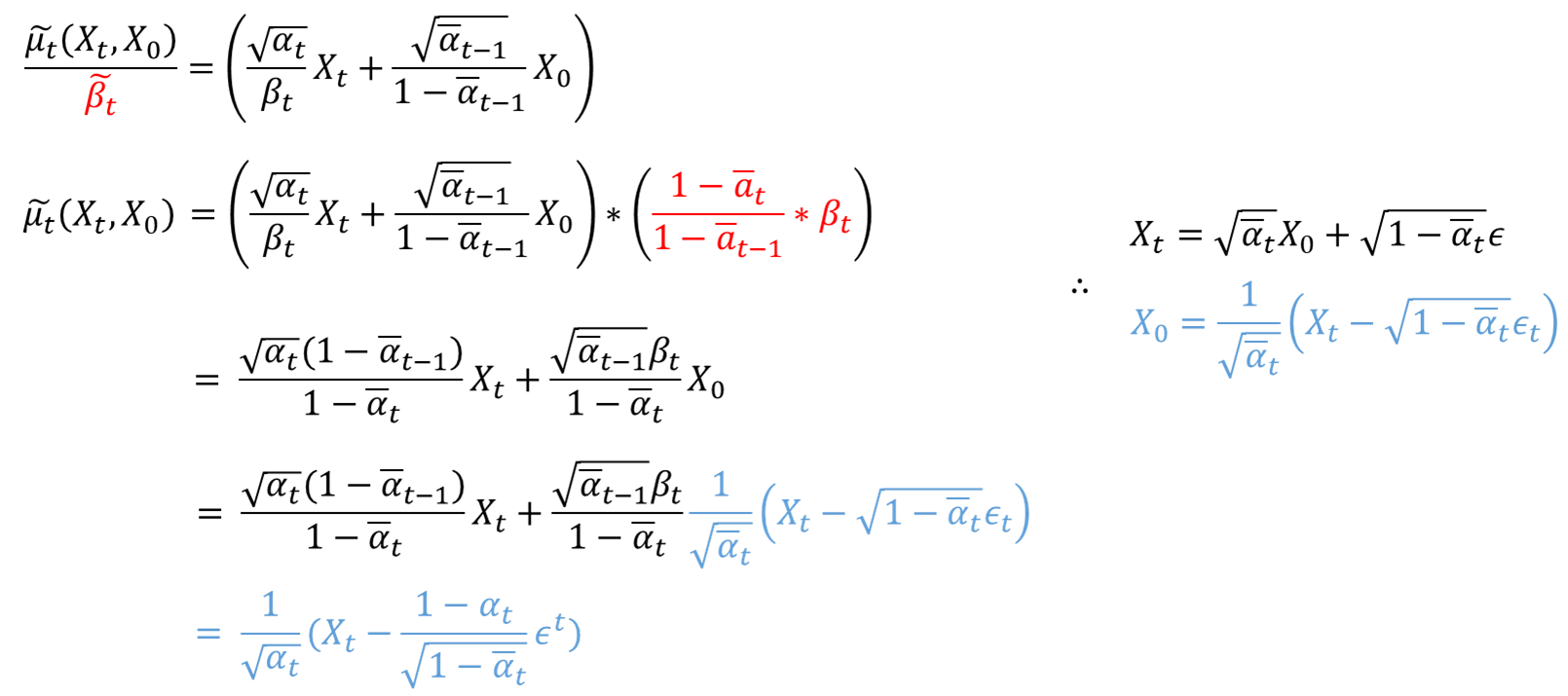
\( p_{\theta}(X_{t-1} | X_t) \) 평균 계산 증명
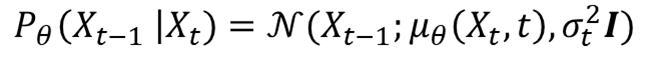
\( p_{\theta} \)의 목적은 \( q \) 함수의 평균을 최대한 근사화하는 것입니다. 그런데 \( \alpha_t \)와 \( \bar {a}_t \)의 정보는 이미 아는 정보입니다. 그래서 위 식을 그대로 활용하여, \( \epsilon_t \)만 학습하여 예측하는 것으로 정의합니다.
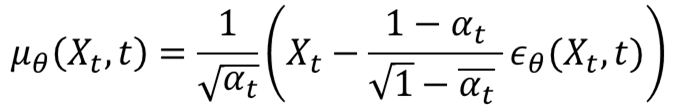
최종 계산

- \(epsilon \)을 구하는 문제로 재정의
- 위에서 유도한 평균 값들을 대입
- 2의 식을 풀어서 L2 norm안에 \( epsilon \)에 대한 식만 남김
- 앞선 전술한 식 \( X_t = \sqrt {\bar {\alpha}_t} X_0 + \sqrt {1 - \bar {\alpha}_t} \epsilon_t \) 를 대입
- 최적화 과정에 연관이 없는 상수들을 제거
- 최종 식
수식을 유도하는 과정에서 생각보다 많은 시간을 할애하였습니다....
모든 수식 유도하는 과정은 직접 만들었기 때문에 오타나 잘못된 수식이 포함되어 있을 거 같네요.
혹시나 오타나 잘못된 지식이 있다면 언제든 지적해 주시면 감사하겠습니다.