[논문리뷰] Cascade R-CNN
들어가며
이 글은 Faster-RCNN에 대한 사전 지식이 있다는 가정하에 작성되었습니다.
본 논문에서 Object Detection에 대한 학습을 진행할 때 Detector의 Predict와 Ground-Truth(GT) 사이의 IOU(Intersection Over Union)를 결정하는 임계값(Threshold) \( \mu \)에 따라 성능이 크게 좌우한다고 합니다.

그런데 고품질의 Object Detection을 학습하는 데 있어서 최적의 Threshold 결정하는 것은 몇 가지 어려움이 존재합니다. 만약 "너무 낮은 임계값을 사용하면 많은 Noise낀 BBox가 Positive로 선정되어 학습에 어려움"이 있고, 반대로 "너무 높은 임계값을 사용하면 아주 작은 BBox에 대한 Positive만 선정되어 과적합"에 우려가 있습니다.

대부분의 Object Detection 논문들이 \( \mu \) 값을 0.5로 고정하여 사용하였습니다. 그런데 Inference시 어떤 Evaluation Metric은 0.6이나 0.7의 임계값에 대한 성능을 요구할 때도 있습니다(e.g. COCO). 이런 상황에서 "고정된 임계값을 사용하는 것은 Inference의 평가 지표의 임계값과의 Mismatch"가 일어난다고 합니다.
본 논문인 이런 임계값에 대한 문제점들을 간단하게 Multi-Scale 구조를 활용하여 해결하였습니다. 이 구조는 먼저 Faster-RCNN과 같이 처음 Region Proposal Network(RPN)에서 학습에 사용될 여러 BBox들을 추출하고, 이후 각 스테이지에서는 이전 스테이지에서 추출한 BBox들에 대한 Resampling을 합니다. 여기서 이 Resampling 하는 것이 이 논문의 핵심입니다.
또한, 학습 loss는 각 stage마다 진행되며, 층이 깊어질수록 임계값 \( \mu \)를 점진적으로 높게 선정하는 방식으로 학습을 진행하였습니다. 이렇게 \( mu \)를 점진적으로 높여가면서 학습을 진행하면, 각 스테이지 임계값에 따른 최적의 방향으로 점진적인 Resampling이 이루어져, 아래와 같이 점진적으로 IoU가 높은 샘플이 많아진다고 합니다.

이러한 과정들로 오버피팅과 Mismatch를 해결하였다고 주장합니다. 대략적인 설명은 이렇고 아래에 더 자세한 네트워크의 학습과정을 설명하도록 하겠습니다.
Cascade R-CNN
Faster R-CNN 리뷰
먼저 Cascasde R-CNN의 토대가 되는 Faster R-CNN의 간단한 설명을 하자면 아래 그림과 같습니다.
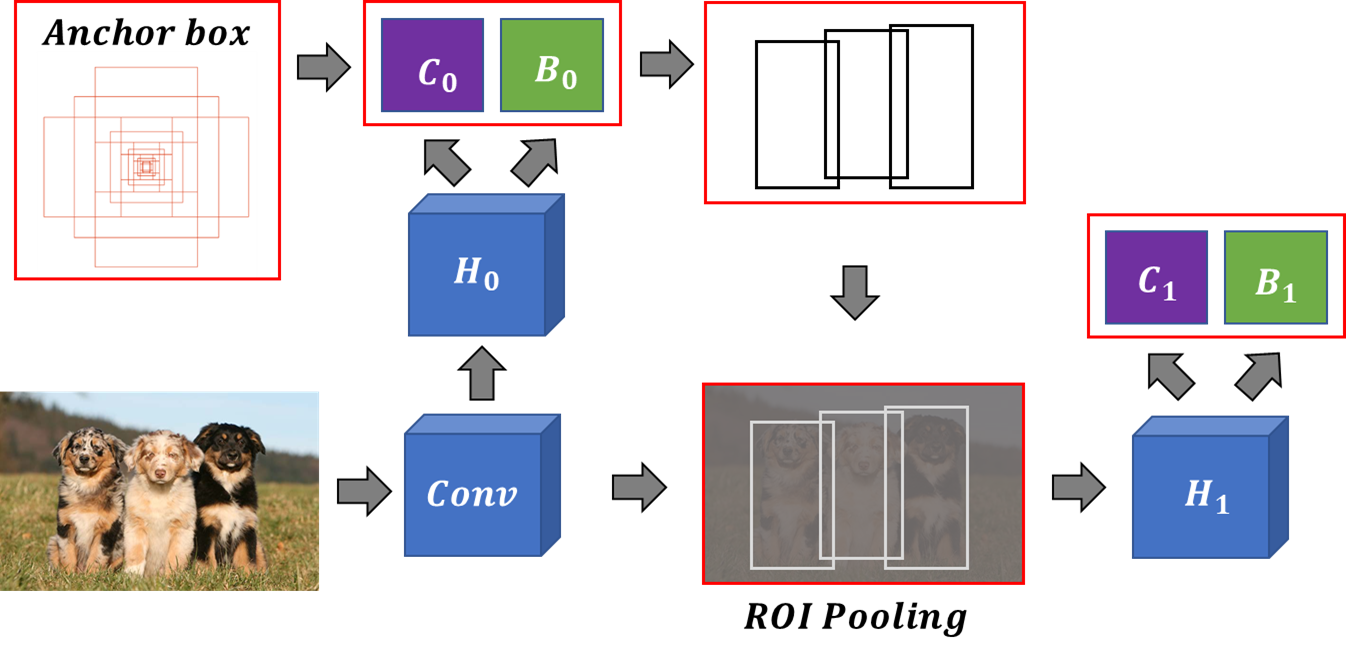
먼저 backbone network로는 ResNet을 사용하였습니다. 이 ResNet을 걸친 Feature map이 RPN인 \( H_0 \)로 입력되고 여기서 Anchor box가 이동할 location을 계산하기 위한 Convolution(\(B_0 \))과, 이동된 박스의 객체 유무 Classification을 계산하기 위한 Convolution( \(C_0 \))이 적용됩니다. Classification의 개수는 Binary(객체가 있다, 없다)로 출력이 구성되고, location은 x, y, width, height로 총 4개로 layer의 출력이 구성됩니다.
위에서 출력된 Proposals 중, 상위 k개(하이퍼 파라미터)만큼 Proposals을 추출하고 여기서 Non Maximum Suppression(NMS)를 진행하여 학습에 사용될 Proposals을 솎아냅니다. 솎아낸 Proposals을 기준으로 GT와의 IoU가 임계값 \( \mu \) 이상(0.7)이면 Positive(Foreground), 이하(0.3)이면 Negative(Background)로 선정하여 RPN에 대한 학습이 이루어집니다.
이후, ResNet에서 추출된 Feature map과 RPN의 영역들에 대한 Region Of Interest(ROI) Pooling이 이루어지고, ROI에 대한 Head layer \( H_1 \)와 최종적으로 예측할 클래스들의 Convolution(\(C_1 \)), Location의 Convolution( \(B_1 \))에 대한 출력으로 학습이 이루어집니다.
Cascade R-CNN
Cascade R-CNN은 위 Faster R-CNN와 동일한 구조를 Multi-Scale에 걸쳐 진행한 것과 각 Stage에서 점진적으로 \( \mu \) 값을 높여가며 학습을 진행한 것 이 두가지 차이밖에 없습니다. 전체 구조는 아래와 같습니다.

Faster R-CNN과 동일하게 Backbone은 ResNet이라고 가정합니다. 먼저, ResNet의 각 스테이지(총 3개)에 따라 앵커박스들을 구성하고, RPN에서 초기 저품질의 Box들을 추출합니다(이 Proposals을 Total Boxes라고 명명하겠습니다).
이어서 추출한 Total Boxes를 Faster R-CNN과 같이 다음 스테이지의 Feature map과의 ROI Pooling을 하고, ROI Head, Classifcation, Location layer를 구성하고 이 Location layer로 구한 x, y, width, height를 기준으로 Total Box에 대한 Resampling이 이루어집니다. 다시 말해, 현재 스테이지의 Feature map를 활용하여 Total Boxes의 위치의 재배치가 이루어진다고 생각하시면 됩니다.
이 재배치된 Total Boxes는 \( mu \)의 값에 대해 학습이 진행되고, 이 \( \mu \)는 레이어가 깊어질수록 커집니다(\( stage_1:0.5, stage_2:0.6, stage_3:0.7 \)). 초기 낮은 \( \mu \)의 학습부터 점진적으로 높은 \( \mu \)에 대한 학습이 이루어 짐에 따라 점진적인 최적화 과정이 일어난다고 본 논문에서는 주장합니다. 이에 대한 Loss 함수는 아래와 같습니다.

\( t \)는 각 스테이지를 의미하고, \( h_t \)는 Classification에 대한 출력, \( f_t \)는 location에 대한 출력입니다.
이러한 과정은 충분히 많은 Box들의 샘플인 Total Box의 개수는 변화하지 않고, 지속적인 Resampling만 이루어지고 임계값 \( \mu \)를 점진적으로 늘려가며 학습하기 때문에, 초기에 전술한 Threshold 값 설정의 모호성과 Mismatch에 대한 우려를 해결하였습니다.
오늘은 Cascade R-CNN의 리뷰를 해보았습니다.
긴 글 읽어주셔서 감사합니다.