[논문리뷰] An End-to-End Trainable Neural Networkfor Image-Based Sequence Recognition andIts Application to Scene Text Recognition(CRNN)
들어가며
기존 시퀀스 인식, 특히 장면 텍스트 인식 분야에서 DCNN을 적용하는 것과 RNN을 적용하여 해결하는 것에는 여러 어려움이 있었습니다. 이를 극복하기 위해 본 논문에서는 DCNN과 RNN을 결합한 CRNN을 제안하였습니다.
한계
1. DCNN을 적용한 사례
DCNN은 일반적으로 고정된 길이의 입력과 출력을 필요로 하여 가변적인 라벨 시퀀스를 처리하기 어렵습니다. 현실 세계에서는 단어의 길이가 다 다르고, 이미지의 크기도 제각각이므로, 고정된 길이의 입력과 출력을 필요로 하는 DCNN은 이런 가변적인 상황에 잘 대응하지 못합니다. 그래서 이전에는 개별 문자를 detection 하거나, 장면 텍스트 인식을 이미지 분류 문제로 적용하는 등의 차선책 밖에 없었습니다.
2. RNN을 적용한 사례
그래서, RNN을 도입한 연구도 있었는데, feature를 추출하기 위해 여러 전처리 과정이 필요했으며, 이로 인해 end-to-end 학습이 불가능했습니다. RNN은 시퀀스 데이터를 다루기 위해 고안된 신경망으로, 입력 데이터의 순서를 고려하여 처리할 수 있습니다. 하지만, RNN을 사용하기 위해서는 입력 이미지를 시퀀스 형태로 변환하는 전처리 과정이 필요했고, 이 과정에서 많은 인위적인 작업이 필요했습니다.
또한, RNN과 DCNN을 결합하여 학습하는 것이 어려웠기 때문에, 완전한 end-to-end 학습이 불가능했습니다.
극복 방안: CRNN의 도입
위와 같은 한계를 극복하기 위해 DCNN과 RNN을 결합한 CRNN을 제안합니다. 이는 end-to-end 학습이 가능하며, 시퀀스 인식 분야에서 결합한 것은 최초의 사례입니다. 특히, RNN 파트에서 장면 텍스트 이미지들의 콘텍스트를 학습할 뿐만 아니라, 시퀀스들의 출력도 할 수 있습니다. 이는 fully-connected layers가 필수가 아니란 소리입니다. 이로 인해 모델의 파라미터 수가 줄어듭니다.
CRNN의 도입으로 별다른 라벨링 없이, end-to-end로 시퀀스 라벨들이 직접적으로 학습될 수 있습니다. 이미지 데이터들로부터 DCNN이 표현을 학습하므로, RNN의 입력으로 넣기 위한 feature를 추출하기 위해 전처리 과정이 필요하지 않습니다. 또한, 시퀀스 길이에 제약이 없습니다.
네트워크 아키텍처
CRNN의 전체 구조는 convolutional layers, recurrent layers, transcription layers로 총 3개의 컴포넌트로 구성됩니다.

1. Convolutional Layers (합성곱 층)
- DCNN과 유사하게, convolution과 max-pooling 레이어로 구성되어 있으며, 이미지의 중요한 시각적 특징을 추출합니다.
- 모든 Feature maps는 동일한 높이의 입력 이미지로 스케일링 되어 출력된 것입니다.
- 위 Feature maps로 RNN에 입력으로 사용될 featue vectors의 시퀀스를 추출
- 모든 Feature maps의 columns의 채널들을 결합한 형태로, 왼쪽에서 오른쪽 순서로 생성됩니다.
- CNN은 translation invariant이므로, 각 feature maps의 column도 왼쪽에서 오른쪽으로 자동으로 대응됩니다.
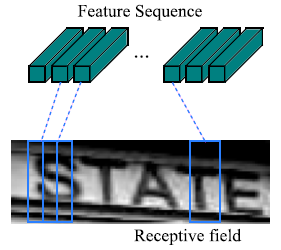
2. Recurrent Layers (순환 층)
- 이 층은 시퀀스 데이터를 처리합니다. BiLSTM(양방향 장단기 기억 네트워크)을 사용하여 각 프레임의 레이블 분포를 예측합니다.
- 순환층은 시퀀스의 문맥 정보를 캡처할 수 있어, 독립적으로 예측하는 것보다 더 정확하게 레이블을 예측할 수 있습니다. 예를 들어, "i"와 "l"과 같이 모호한 문자를 문맥을 고려하여 더 쉽게 구분할 수 있습니다.
- 이 층을 CNN 위에 연결시킴으로써 end-to-end 학습이 가능하고, 고정된 길이가 아닌 임의의 길이의 시퀀스 연산도 가능합니다.
3. Transcription Layers (전사 층)
- 최종적으로 순환 층의 출력 시퀀스 \( \mathbf {y} = y_1, ..., y_T \) (T는 시퀀스의 길이)를 최종 label sequence로 변환하는 과정입니다.
- lexicon-free, lexicon-based 두 가지 버전으로 나뉩니다.
3.1 Probability of Label Sequence
- 두 버전을 설명하기 앞서, 기존 label sequence를 변환하는 과정을 설명하자면, 순환 층의 출력 시퀀스 \( \mathbf {y} = y_1,..., y_T \)에서 각각의 프레임의 확률 분포를 예측합니다. 이 확률 분포의 카테고리 개수는 모든 알파벳에 벳에 ‘blank’를 더해 총 27개입니다.
- 예측된 시퀀스 \( \pi \in \mathcal {L}'^T \)에 중복된 라벨 및 blank를 제거해주는 매핑 함수 \( \mathcal {B} \)가 있습니다. 예를들어 -hh-e-l-ll-oo-라는 \( \pi \) 결과가 있으면, 이것을 hello로 매핑해 주는 함수입니다.
- 그래서 조건부 확률을 아래와 같이 나타낼 수 있으며, 모든 가능한 \( \pi \)를 \( \mathcal {B} \)로 매핑했을 때, \( l \)이 되는 확률 값들의 합입니다. \( l \) 이 hello라는 label sequence 일 때, \( \pi \)는 -hh-e-l-l-o, -h-e-l-l-o-o 등, 매핑 과정을 거쳤을 때 hello가 되는 모든 집합들이겠죠.

- 여기서 \( \pi \)의 확률은 각 프레임에서 대응되는 확률 값의 곱이며 \( p(\pi|y) = \mathrm {\Pi}_{t=1}^T y^t_{\pi_t}\)로 정의될 수 있습니다.
3.2 Lexicon-Free Transcription
- 하지만 위 과정은 모든 \( \pi \) 에 대해 계산해야 하기 때문에, 계산량이 너무 많다는 제한점이 있습니다.
- 그래서 위 과정을 근사하기 위해, 단순하게 가장 높은 확률값 \( l^* \)에 대해서만 예측으로 받아들이려고 하였습니다.
- 이 과정도 tractable하지 않아, 각 시간 단계 \( t \)에서 가장 높은 확률을 가지는 라벨을 선택하고, 이를 기반으로 최종 레이블 시퀀스 \( l^* \)를 얻어, 매핑과정을 거치는 과정으로 근사하였습니다( \( l^* \approx \mathcal {B}(argmax_{\pi} p(\pi|y) \)).
3.3 Lexicon-Based Transcription
Lexicon-based transcription은 입력된 시퀀스 데이터를 미리 정의된 사전(lexicon)에 있는 단어 중 하나로 전사하는 방법입니다. 이 접근법은 lexicon-free 방식보다 정확할 수 있지만, 더 많은 계산을 필요로 할 수 있습니다.
- 먼저 3.2절과 같이 근사하는 방식으로 label sequence를 예측합니다.
- 예측된 label sequence와 edit distance metric 기준으로 가장 가까운 lexicon \( \mathcal {D} \)를 선택합니다. 예를 들어 label sequence가 cet이라고, lexicon에 등록된 cat와 cow가 있다면, cat과 distance가 더 가까우니 cat으로 변환한다는 것입니다.

- \( \delta \)는 최적의 edit distance이고, \( l' \)은 Lexicon-free에서 y로 예측한 시퀀스, \( \mathcal {N}_{\delta}(l') \)는 가장 가까운 Lexicon입니다
- 본 논문에서는 \( \mathcal {N}_{\delta}(l') \)을 가장 효율적으로 찾기위해 BK-tree를 사용하고, 시간 복잡도는 O(log|D|)입니다.
마치며
학습은 negative lod-likelihood를 최소화하는 방향으로 하였고, 모든 과정은 end-to-end로 진행할 수 있게 되었습니다. 실험단은 본문을 참고하시길 바랍니다.